Transaction Understanding
- Transaction Understanding
- 1. Overview
- 2. ACID
- 3. Single and Multi Objects Operations - Atomicity + Isolation
- 4. Isolation Levels
- 5. Two Phase Locking
- 6. Serializable Snapshot Isolation
Transaction Understanding
1. Overview
1.1 Things can go wrong
- db software or hardware could fail at any time
- application could crash at any time
- interruptions in the network can unexpectedly cut off the application from the db, or one db node from another
- several clients may write to the db at the same time, overwriting each other’s change
- race conditions between clients can cause surprising bugs
1.2 Transaction
- Transaction is the mechanism for us to simplify those issues
- Group several reads and writes together is a logical unit
- either the entire transaction succeeds or it fails
- application can safely retry if it fails
- Transaction makes error handling much more easier
- no need to worry about partial failure
- Transaction is created with a purpose, to simplify the programming model for applications accessing a database
- database take care of such issue
- for transaction, we need to understand
- what safety guarantees transactions can provide
- what costs are associated with them
2. ACID
- ACID are the safety guarantees provided by transactions
- Atomicity
- Consistency
- Isolation
- Durability
2.1 Atomicity
- Atomic means sth cannot be broken down into smaller parts
- Describes what happens if a client want to make several writes, but a fault occurs after some of the writes have been processed
- if the writes are grouped together into an atomic transaction
- the transaction cannot be completed due to a fault,
- then the transaction is aborted
- the database must discard or undo any writes it has made so far in that transaction
- The ability to abort a transaction on error and have all writes from that transaction discarded is the defining feature of ACID atomicity
2.2 Consistency
- Consistency refers to an application specific notion of the database being in a good state
- The idea of ACID consistency is that you have certain statements about your data (invariants) that must always be true—for example, in an accounting system, credits and debits across all accounts must always be balanced
- But this ususally is application code responsibility to define what data is valid or invalid
2.3 Isolation
- Isolation means that concurrently executing transactions are isolated from each other: they cannot step on each other’s toe
2.4 Durability
- Purpose of a db system is to provide a safe place where data can be stored without fear of losing it
- Durability is the promise that once a transaction has committed successfully, any data it has written will not be forgotten, even if there is a hardware fault or the database crashes.
- In a single node database
- means data has been written to nonvolatile storage such as a hard drive or SSD
- could also involves a write ahead log
- In a replicated db,
- means data has been successfully copied to some number of nodes
3. Single and Multi Objects Operations - Atomicity + Isolation
3.1 Multi Object Transactions
3.1.1 Why we need it
- Need some way to determine which read and write operations belong to the same transaction
- In relational db, typically done based on the client’s TCP connection to the database server
- on any particular connection, everything between a BEGIN TRANSACTION and a COMMIT statement is considered to be part of the same transaction
3.1.2 Scenarios
- In a relational data model, a row in one table often has a foreign key reference to a row in another table
- multi object transactions allow you to ensure that these references remain valid
- In a document data model, the fields that need to be updated together are often within the same document, which is treated as a single object—no multi-object transactions are needed when updating a single document. However, document databases lacking join functionality also encourage denormalization. When denormalized information needs to be updated, you need to update several documents in one go. Transactions are very useful in this situation to prevent denormalized data from going out of sync
- In db with secondary indexes, indexes also need to be updated every time you change a value
- These indexes are different database objects from a transaction point of view: for example, without transaction isolation, it’s possible for a record to appear in one index but not another, because the update to the second index hasn’t happened yet.
3.2 Single Object Writes
- Atomicity and isolation also apply when a single object is being changed
- all storage engines universally aim to provide atomicity and isolation on the level of a single object on one node
- Atomicity
- Using a log for crash recovery
- increment operation
- compare and set
- Isolation
- Using a lock on each object
3.3 Handling errors and aborts
- ACID DB Philosophy
- Aborts of transaction point is to safely retry, thus we should have some retry mechanism build for such scenario
4. Isolation Levels
Concurrency bugs are hard to find by testing, cause they are rare, and difficult to reproduce. For such reasons, databases have long tried to hide concurrency issues from application developers by providing transaction isolation
In theory, isolation should make your life easier by letting you pretend that no concurrency is happening: serializable isolation means that the database guarantees that transactions have the same effect as if they ran serially
In practice, isolation has a performance cost, and many databased don’t want to pay that price. Thus it’s common for systems to use weaker levels of isolation, which protect against some concurrency issues, but not all
4.1 Read Committed
4.1.1 Guarantees
- when reading from the database, you will only see data that has been committed(no dirty reads)
- when writing to the database, you will only overwrite data that has been committed (no dirty writes)
4.1.2 No dirty reads Explanation
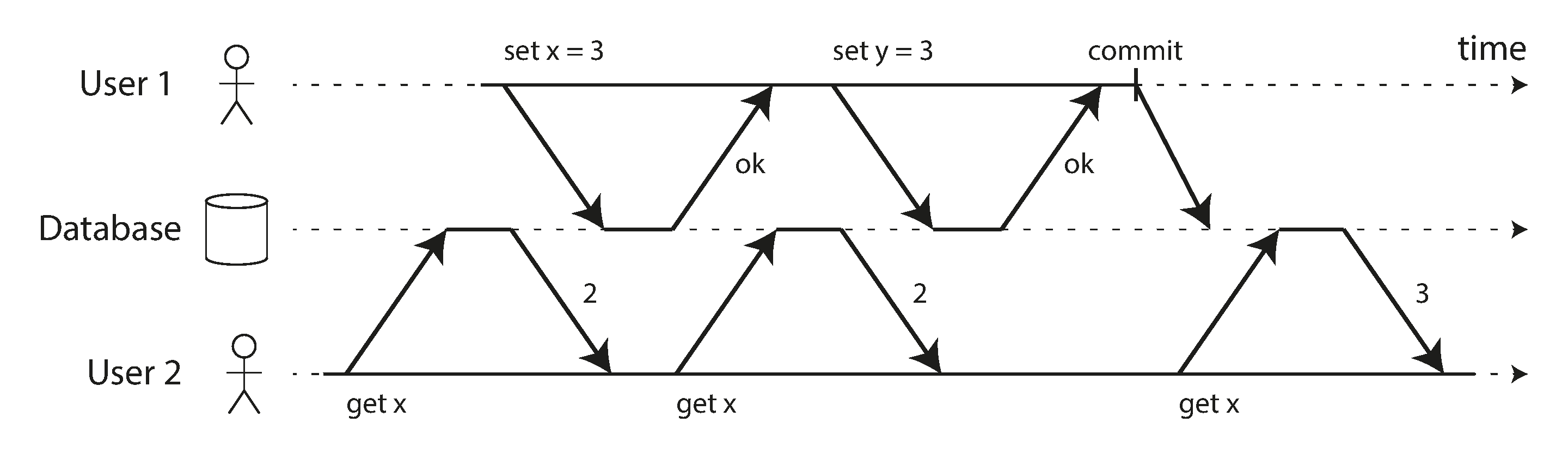
Prevent dirty read, only committed record could be seen
reasons for dirty read prevention
- See the database in a partially updated state is confusing to users and may cause other transactions to take incorrect decisions
- If a transaction aborts, any writes it has made need to be rolled back (like in Figure 7-3). If the database allows dirty reads, that means a transaction may see data that is later rolled back—i.e., which is never actually committed to the database. Reasoning about the consequences quickly becomes mind-bending.
4.1.3 No Dirty Write Explanation
- If two transactions concurrently try to update the same object in a db, we normally assume that the later write overwrites the earlier write
- Dirty write happen when
- the earlier write is part of a transaction that has not yet committed, so the later write overwrites an uncommitted value
- how does committed isolation level work?
- by delaying the second write until the first write’s transaction has committed or aborted
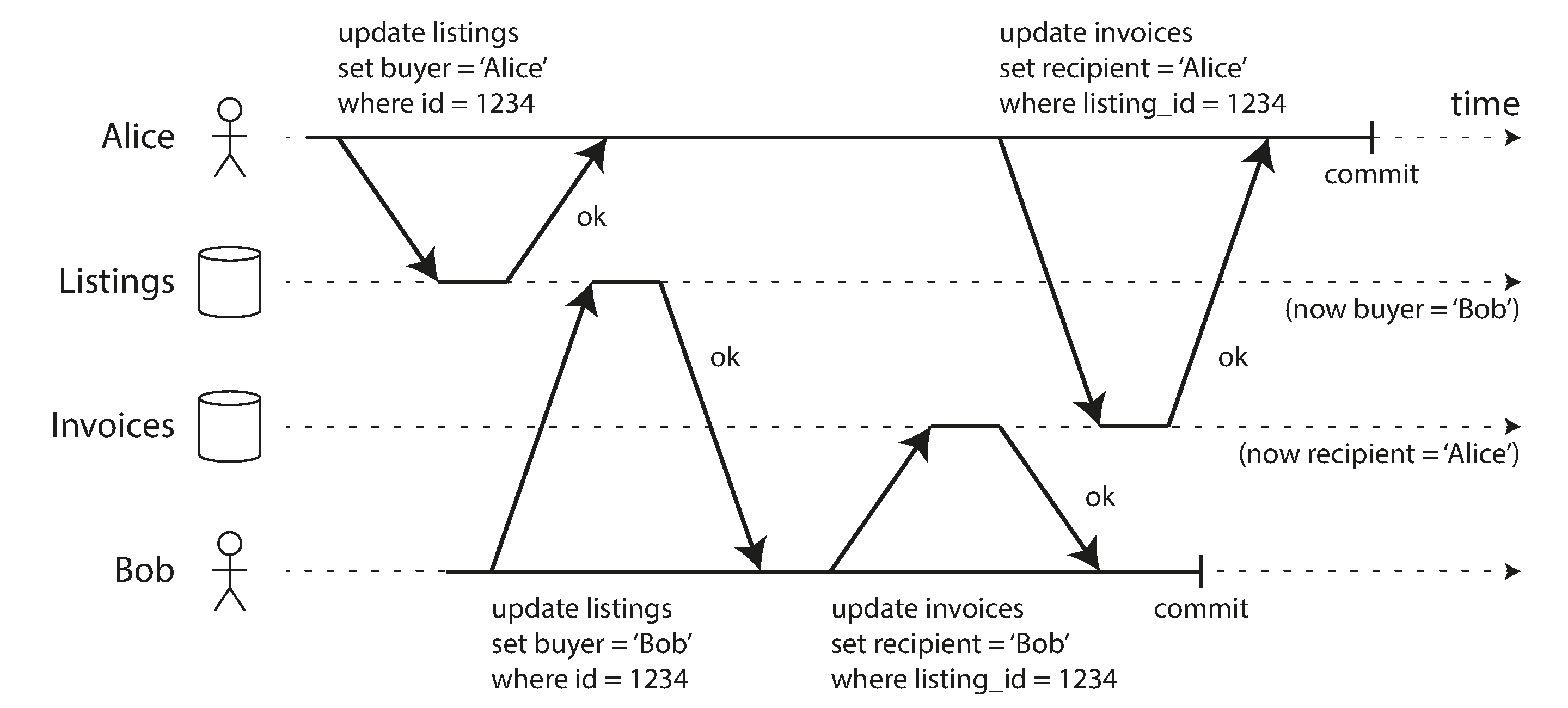
4.1.4 Implementation
Dirty writes — Row level lock
- when a transaction wants to modify a particular object (row or document), it must first acquire a lock on that object.
- It must then hold that lock until the transaction is committed or aborted.
- Only one transaction can hold the lock for any given object;
- if another transaction wants to write to the same object, it must wait until the first transaction is committed or aborted before it can acquire the lock and continue.
- This locking is done automatically by databases in read committed mode (or stronger isolation levels).
Dirty Reads —
still use row level lock
- the approach of requiring read locks does not work well in practice, because one long-running write transaction can force many other transactions to wait until the long-running transaction has completed, even if the other transactions only read and do not write anything to the database
This harms the response time of read-only transactions and is bad for operability: a slowdown in one part of an application can have a knock-on effect in a completely different part of the application, due to waiting for locks.
most databases prevent dirty reads using the approach illustrated here
for every object that is written, the database remembers both the old committed value and the new value set by the transaction that currently holds the write lock.
While the transaction is ongoing, any other transactions that read the object are simply given the old value. Only when the new value is committed do transactions switch over to reading the new value.
4.2 Snapshot Isolation and Repeatable Read
4.2.1 Issue with Read Committed
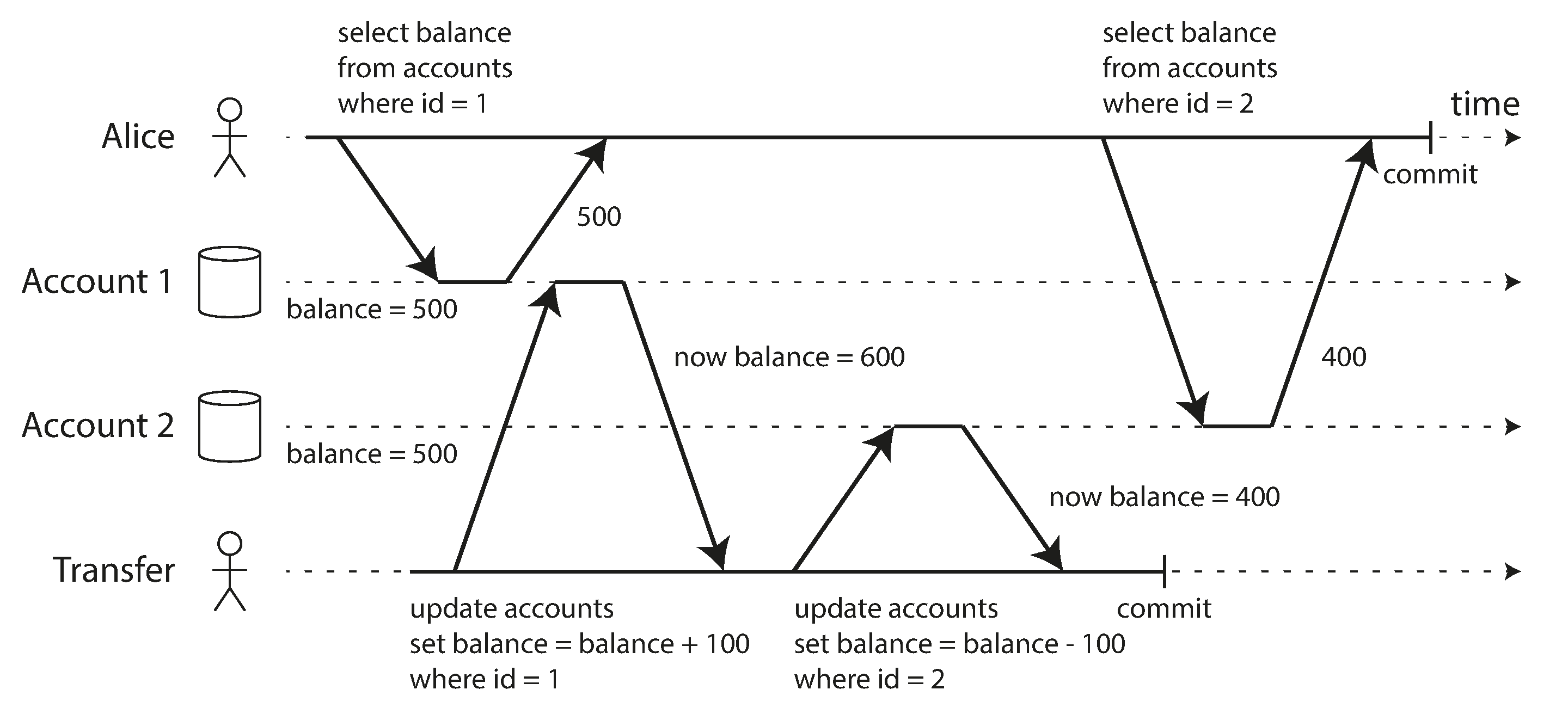
- Read committed can still have concurrency bug
- In the image above, there will be certain time the amount of 2 accounts are not equal to 1000
- called read skew — nonrepeatable read
- there will be temporary inconsistency
- read the committed data by another transaction
- But there are certain situations, that cannot tolerate such temporary inconsistency
- Backup
- Taking a backup requires making a copy of the entire database, which may take hours on a large database. During the time that the backup process is running, writes will continue to be made to the database. Thus, you could end up with some parts of the backup containing an older version of the data, and other parts containing a newer version. If you need to restore from such a backup, the inconsistencies (such as disappearing money) become permanent.
- Analytic queries and integrity checks
- nonsensical results will be returned if the database is at different points in time
- Backup
4.2.2 Solution: Snapshot isolation
- Each transaction reads from a consistent snapshot of the database,
- the transaction sees all the data that was committed in the db at the start of the transaction
4.2.3 Snapshot Isolation Implementation
Use write locks to prevent dirty writes
- a transaction that makes a write can block the progress of another transaction that writes to the same object
reads do not require any locks.
- From a performance point of view, a key principle of snapshot isolation is readers never block writers, and writers never block readers
- This allows a database to handle long-running read queries on a consistent snapshot at the same time as processing writes normally, without any lock contention between the two.
To implement snapshot isolation, db uses a generalization of the mechanism
- db must potentially keep several different committed versions of an object, because various in progress transactions may need to see the state of the db at different points in time
- — named as multi version concurrency control — MVCC
If a database only needed to provide read committed isolation, but not snapshot isolation, it would be sufficient to keep two versions of an object:
- the committed version and the overwritten-but-not-yet-committed version.
However, storage engines that support snapshot isolation typically use MVCC for their read committed isolation level as well.
- A typical approach is that read committed uses a separate snapshot for each query, while snapshot isolation uses the same snapshot for an entire transaction.
4.2.4 Visibility rules for observing a consistent snapshot
- Transaction IDs are used to decide which objects it can see and which are invisible
- Rules
- At the start of each transaction, the database makes a list of all the other transactions that are in progress (not yet committed or aborted) at that time. Any writes that those transactions have made are ignored, even if the transactions subsequently commit.
- Any writes made by aborted transactions are ignored.
- Any writes made by transactions with a later transaction ID (i.e., which started after the current transaction started) are ignored, regardless of whether those transactions have committed.
- All other writes are visible to the application’s queries.
4.3 Preventing Lost Updates
4.3.1 Issues
The lost update problem can occur if an application reads some value from the database, modifies it, and writes back the modified value (a read-modify-write cycle). If two transactions do this concurrently, one of the modifications can be lost, because the second write does not include the first modification. (We sometimes say that the later write clobbers the earlier write.) This pattern occurs in various different scenarios:
- Incrementing a counter or updating an account balance (requires reading the current value, calculating the new value, and writing back the updated value)
- Making a local change to a complex value, e.g., adding an element to a list within a JSON document (requires parsing the document, making the change, and writing back the modified document)
- Two users editing a wiki page at the same time, where each user saves their changes by sending the entire page contents to the server, overwriting whatever is currently in the database
4.3.2 Solution 1: Atomic Write Operations
- Using atomic update provided by database,
UPDATE counters SET value = value + 1 WHERE key = 'foo';- Atomic operations are usually implemented by taking an exclusive lock on the object when it is read so that no other transaction can read it until the update has been applied
- Also, we could force all atomic operations to be executed on a single thread
4.3.3 Solution 2: Explicit Locking
- Explicitly lock objects that are going to be updated
- then the application can perform a read modify write cycle
- if any other transaction tries to concurrently read the same object, it is forced to wait until the first read-modify-write cycle has completed
BEGIN TRANSACTION;
SELECT * FROM figures
WHERE name = 'robot' AND game_id = 222
// For Update will let databse take a lock o
FOR UPDATE; 1
-- Check whether move is valid, then update the position
-- of the piece that was returned by the previous SELECT.
UPDATE figures SET position = 'c4' WHERE id = 1234;
COMMIT;4.3.4 Solution 3: Automatically detecting lost updates
- Atomic operations and locks are ways of preventing lost updates by forcing the read-modify-write cycles to happen sequentially.
- An alternative is to allow them to execute in parallel and, if the transaction manager detects a lost update, abort the transaction and force it to retry its read-modify-write cycle.
- Lost update detection is great because it doesn’t require application code to use any special database features, you could forget to use a lock or an atomic operation, but lost update detection happens automatically and thus less error prone
4.3.5 Solution 4: Compare and set
- Avoid lost updates by allowing an update to happen only if the value has not changed since you last read it
UPDATE wiki_pages SET content = 'new content'
WHERE id = 1234 AND content = 'old content';- But notice the compare and set operation is possible to be unsafe if db by default read from the old snapshot
4.3.6 Solution 5: Conflict resolution and replication
In multi leader or leaderless replication system, a common approach in such replicated databases is to allow concurrent writes to create several conflicting versions of a value (also known as siblings), and to use application code or special data structures to resolve and merge these versions after the fact.
4.4 Write Skew and Phantoms
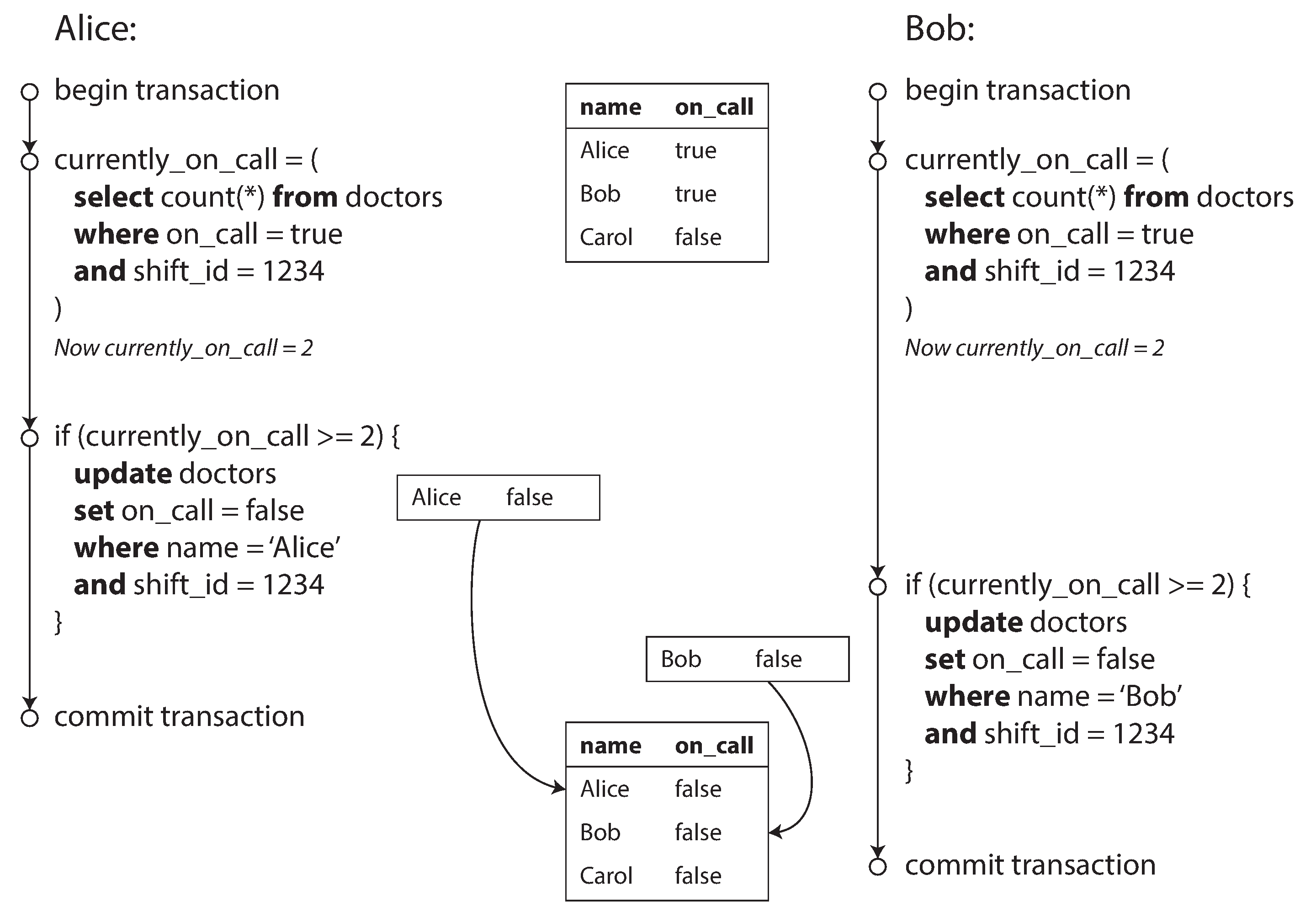
- In each transaction, we first check that two or more doctors are currently on call,
- since db is using snapshot isolation, both checks return 2, so both of them proceed to the next stage
- Write Skew
- it’s neither a dirty write nor a lost update, because the two transactions are updating two different objects
- But it’s a race condition as the anomalous behavior was only possible because the transactions ran concurrently
- You can think of write skew as a generalization of the lost update problem.
- Write skew can occur if two transactions read the same objects, and then update some of those objects (different transactions may update different objects).
- In the special case where different transactions update the same object, you get a dirty write or lost update anomaly (depending on the timing).
4.4.2 Solution
- We need to explicitly lock the rows as solution in isolation snapshot works for one object, now the case come to be multiple objects, so that comes to be different
BEGIN TRANSACTION;
SELECT * FROM doctors
WHERE on_call = true
AND shift_id = 1234 FOR UPDATE; 1
UPDATE doctors
SET on_call = false
WHERE name = 'Alice'
AND shift_id = 1234;
COMMIT;4.4.3 Phantoms
All of these examples follow a similar pattern:
A
SELECTquery checks whether some requirement is satisfied by searching for rows that match some search condition (there are at least two doctors on call, there are no existing bookings for that room at that time, the position on the board doesn’t already have another figure on it, the username isn’t already taken, there is still money in the account).Depending on the result of the first query, the application code decides how to continue (perhaps to go ahead with the operation, or perhaps to report an error to the user and abort).
If the application decides to go ahead, it makes a write (
INSERT,UPDATE, orDELETE) to the database and commits the transaction.The effect of this write changes the precondition of the decision of step 2. In other words, if you were to repeat the
SELECTquery from step 1 after committing the write, you would get a different result, because the write changed the set of rows matching the search condition (there is now one fewer doctor on call, the meeting room is now booked for that time, the position on the board is now taken by the figure that was moved, the username is now taken, there is now less money in the account).
The steps may occur in a different order. For example, you could first make the write, then the SELECT query, and finally decide whether to abort or commit based on the result of the query.
In the case of the doctor on call example, the row being modified in step 3 was one of the rows returned in step 1, so we could make the transaction safe and avoid write skew by locking the rows in step 1 (SELECT FOR UPDATE). However, the other four examples are different: they check for the absence of rows matching some search condition, and the write adds a row matching the same condition. If the query in step 1 doesn’t return any rows, SELECT FOR UPDATE can’t attach locks to anything.
This effect, where a write in one transaction changes the result of a search query in another transaction, is called a phantom [3]. Snapshot isolation avoids phantoms in read-only queries, but in read-write transactions like the examples we discussed, phantoms can lead to particularly tricky cases of write skew.
4.4.4 Materializing conflicts for Phantoms
- Pre create all rows in the db, thus phantoms problems could be converted to the doctor appointment problem we discussed before
4.4.5 Predicate Locks
- We could use a predicate lock for booking case, works similarly to the shared/ exclusive lock, but rather than belong to a particular object, it belongs to all objects that match some search condition
SELECT * FROM bookings
WHERE room_id = 123 AND
end_time > '2018-01-01 12:00' AND
start_time < '2018-01-01 13:00';- If transaction A wants to read objects matching some condition, like in that
SELECTquery, it must acquire a shared-mode predicate lock on the conditions of the query. If another transaction B currently has an exclusive lock on any object matching those conditions, A must wait until B releases its lock before it is allowed to make its query. - If transaction A wants to insert, update, or delete any object, it must first check whether either the old or the new value matches any existing predicate lock. If there is a matching predicate lock held by transaction B, then A must wait until B has committed or aborted before it can continue.
4.5 Serializability
- There are a lot of different isolation levels, and each db declare their isolation level slightly different,
- We could use serializable isolation to simplify it
- Serializable isolation
- Strongest isolation level
- without any concurrency
- Serializable Mechanism
- Literally executing transactions in a serail order
- Two Phase Locking
- Optimistic concurrency control techniques such as serializable snapshot isolation
4.5.1 Actual Serial Execution
We could try to only execute one transaction at a time, in serial order, on a single thread
This comes to be realistic recently around 2007 because
- RAM became cheap enough, thus it’s now feasible to keep the entire active dataset in memory
- OLTP transactions are usually short and only make a small number of reads and writes
- by contrast, long running analytic queries are typically read only, so they can be run on a consistent snapshot outside of the serial execution loop
This approach is implemented in VoltDB/ Hstore, Redis, and Datomic
Notice
- A system designed for a single threaded execution can sometimes perform better than a system that supports concurrency, because it can avoid the coordination overhead of locking
4.5.2 Encapsulating transactions in stored procedures
Philosophy
- Keep transactions short by avoiding interactively waiting for a user within a transaction
- means a transaction is committed within the same HTTP request,
IN the interactive style of transaction, network and db will take a lot time, we need to make sure we could handle enough throughput, we need to process multiple transactions concurrently in order to get reasonable performance.
Systems with single threaded serial transaction processing could receive the entier transaction code to db ahead of time , as a stored procedure
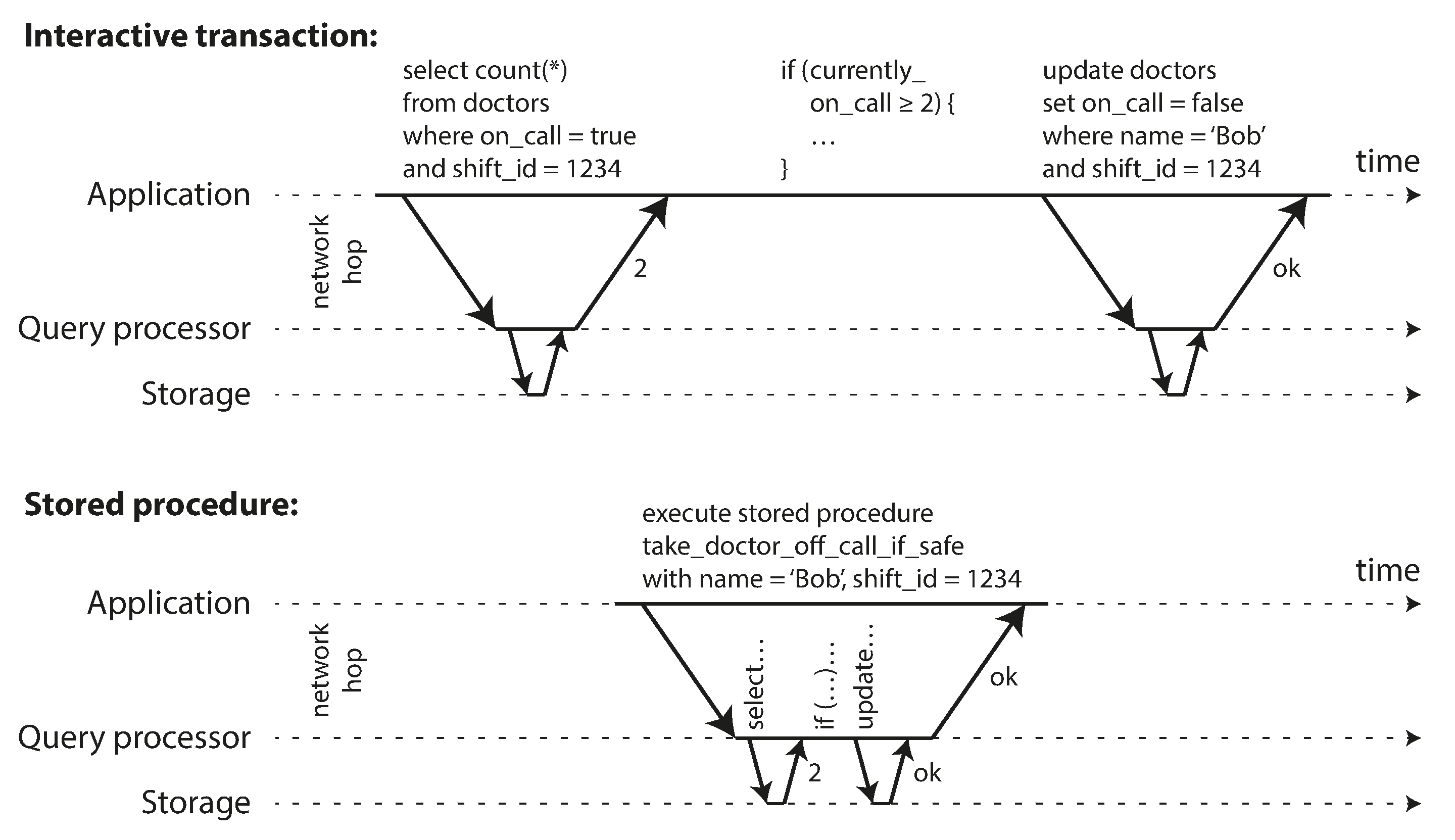
- Pros and Cons
- Each db has its own language for stored procedures
- Code running in db is difficult to manage, more awkward to keep in version control and deploy
- db is often much more performance sensitive,because a single db instance is often shared by a lot of application servers. A bad written stored procedure can cause much more trouble than equivalent badly written code in an application server
4.5.3 Partitioning
- Partition data to scale to multiple CPU cores, and multiple nodes.
- However, for any transaction that needs to access multiple partitions, the database must coordinate the transaction across all the partitions that it touches. The stored procedure needs to be performed in lock-step across all partitions to ensure serializability across the whole system.
5. Two Phase Locking
5.1 Concepts
- Several transactions are allowed to concurrently read the same object as long as nobody is writing to it
- But as soon as anyone wants to write(modify or delete) an object, exclusive access is required
- Writes not only block other writers, it also block all readers
5.2 Implementation
- If a transaction wants to read an object, it must first acquire the lock in shared mode. Several transactions are allowed to hold the lock in shared mode simultaneously, but if another transaction already has an exclusive lock on the object, these transactions must wait.
- If a transaction wants to write to an object, it must first acquire the lock in exclusive mode. No other transaction may hold the lock at the same time (either in shared or in exclusive mode), so if there is any existing lock on the object, the transaction must wait.
- If a transaction first reads and then writes an object, it may upgrade its shared lock to an exclusive lock. The upgrade works the same as getting an exclusive lock directly.
- After a transaction has acquired the lock, it must continue to hold the lock until the end of the transaction (commit or abort). This is where the name “two-phase” comes from: the first phase (while the transaction is executing) is when the locks are acquired, and the second phase (at the end of the transaction) is when all the locks are released.
5.3 Performance
- transaction throughput and response times of queries are significantly worse under two-phase locking than under weak isolation.
- overhead of acquiring and releasing all those locks, but more importantly due to reduced concurrency.
6. Serializable Snapshot Isolation
- It provides full serializability, but has only a small performance penalty compared to snapshot isolation
- Snapshot + Serializable
- optimistic concurrency control mechanism
- It performs badly if there is high contention (many transactions trying to access the same objects), as this leads to a high proportion of transactions needing to abort. If the system is already close to its maximum throughput, the additional transaction load from retried transactions can make performance worse.
- to achieve serialization, db need to know if the query result has been changed within the transaction
- Detecting reads of a stale MVCC object version (uncommitted write occurred before the read)
- Detecting writes that affect prior reads (the write occurs after the read)
6.1 Detecting stale MVCC reads
In order to prevent this anomaly, the database needs to track when a transaction ignores another transaction’s writes due to MVCC visibility rules. When the transaction wants to commit, the database checks whether any of the ignored writes have now been committed. If so, the transaction must be aborted.
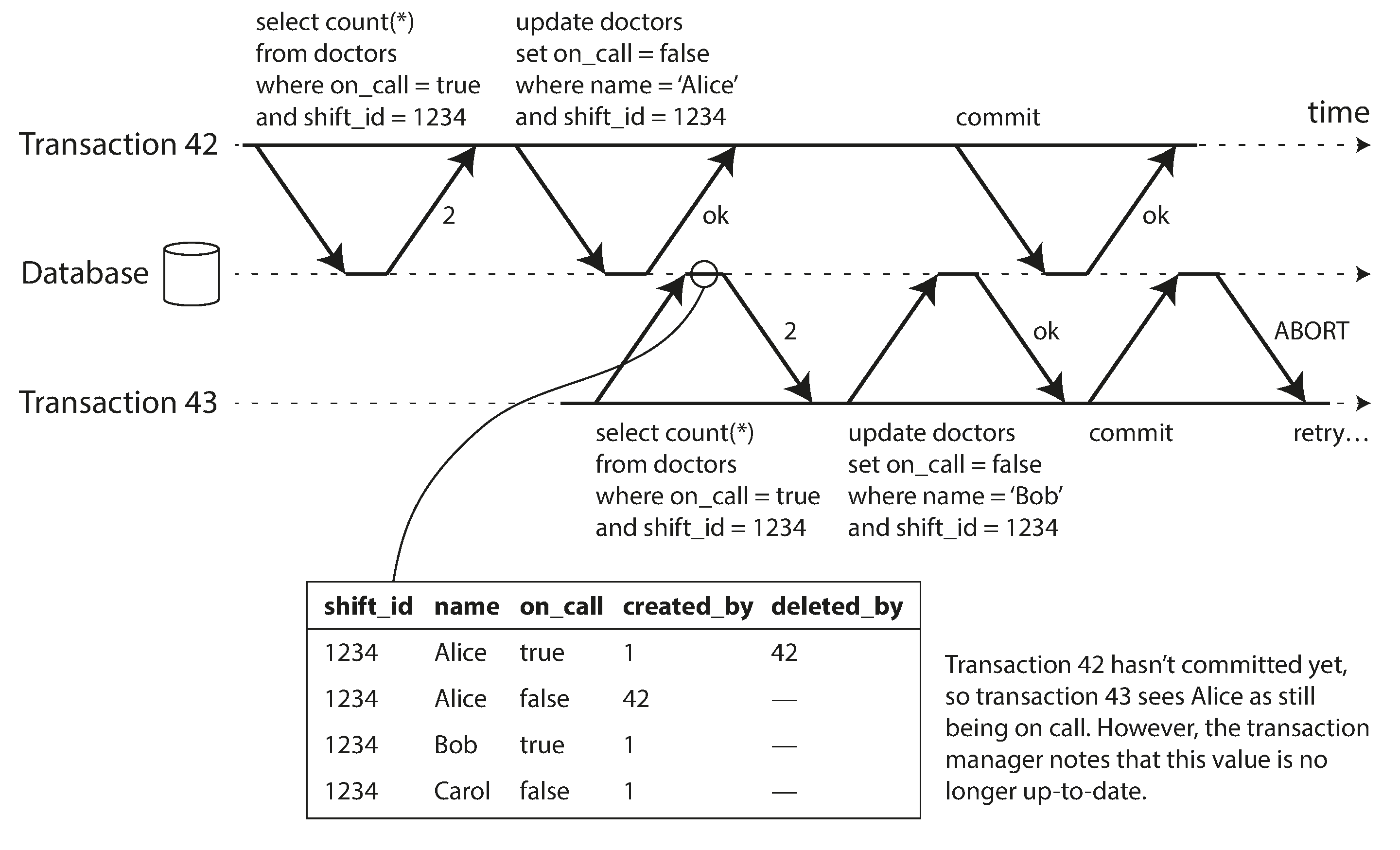
6.2 Detecting writes that affect prior reads
When a transaction writes to the database, it must look in the indexes for any other transactions that have recently read the affected data. This process is similar to acquiring a write lock on the affected key range, but rather than blocking until the readers have committed, the lock acts as a tripwire: it simply notifies the transactions that the data they read may no longer be up to date.
6.3 Performance
Compared to two-phase locking, the big advantage of serializable snapshot isolation is that one transaction doesn’t need to block waiting for locks held by another transaction. Like under snapshot isolation, writers don’t block readers, and vice versa. This design principle makes query latency much more predictable and less variable. In particular, read-only queries can run on a consistent snapshot without requiring any locks, which is very appealing for read-heavy workloads.
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:Transaction Understanding
文章字数:4.3k
本文作者:Leilei Chen
发布时间:2022-03-25, 11:16:10
最后更新:2022-03-25, 21:52:19
原始链接:https://www.llchen60.com/Transaction-Understanding/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

