Real time data’s unifying abstraction
Real time data’s unifying abstraction
1. Overview
- Logs play a key role in distributed data systems and real time application architectures.
- write ahead log
- commit log
- transaction logs
2. What is a log?
2.1 Some Concepts
- Storage abstraction
- append only
- totally ordered sequence of records ordered by time
- Records
- appended to the end of the log
- read from left to right
- each entry has a unique sequential log entry number
- Log
- record what happened and when
- for distributed system, that’s the very heart of the problem
- types
- text logs
- meant primarily for humans to read
- journal/ data logs
- built for programmatic access
- text logs
2.2 Log in different scenario
2.2.1 Logs in DB
- Function 1: Authoritative source for restoring data
- DB need to keep in sync the variety of data structures and indexes in the presense of crashes
- To make this atomic and durable, a db uses a log to write out information about the records they will be modifying, before applying the changes to all the various data structures it maintains
- Since the log is immediately persisted it is used as the authoritative source in restoring all other persistent structures in the event of a crash.
- Function 2: Replicating data between DBs
- Oracle, MySQL and Postgres SQL include log shipping protocols to transmit portions of log to replica databases which act as slaves
2.2.2 Logs in distributed systems
- Log Centric Approach
- we could reduce the problem of making multiple machines all do the same thing to the problem of implementing a distributed consistent log to feed these processes input
- squeeze all the non-determinism out of the input stream to ensure that each replica processing this input stays in sync.
- time stamps that index the log now act as the clock for the state of the replicas—you can describe each replica by a single number, the timestamp for the maximum log entry it has processed.
3. Log Types
- What we could put in log
- log the incoming requests to a service
- the state changes the service undergoes in response to request
- the transformation commands it executes.
- For DB usage
- physical logging
- log the contents of each row that is changed
- logical logging
- log not the changed rows but the SQL commands that lead to the row chagnes
- physical logging
- For Distributed Systems to process and replicate
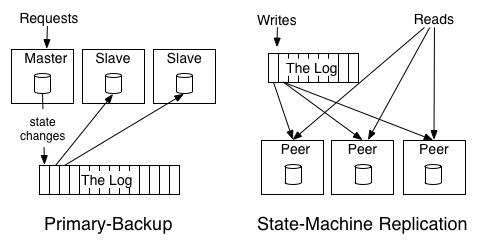
- Primary Backup
- elect one replica as the leader
- allow this leader to process requests in the order they arrive
- log out the changes to its state from processing the requests.
- The other replicas apply in order the state changes the leader makes so that they will be in sync and ready to take over as leader should the leader fail.
- backup will copy the result from the primary, no logical action to walk through all action primary did
- Primary Backup
- State Machine Replication
- active-active model where we keep a log of the incoming requests and each replica processes each request
- **each machine will do real execution, do the logical stuff**
4. Changelog in Database
- duality between a log of changes and a table
- The log is similar to the list of all credits and debits and bank processes;
- a table is all the current account balances.
- If you have a log of changes, you can apply these changes in order to create the table capturing the current state.
- if you have a table taking updates, you can record these changes and publish a “changelog” of all the updates to the state of the table. This changelog is exactly what you need to support near-real-time replicas.
- Table support data at rest and logs capture changes
5. Data Integration
Make all of an organization’s data easily available in all its storage and processing systems
5.1 Expected workflow for data integration
- Definition in author’s scope: Making all the data an organization has available in all its services and systems.
- Effective Use of Data
- Capture all relevant data
- Put it together in an applicable processing env
- real time query system
- text files
- python scripts, etc.
- Infra to process data
- mapReduce
- Real time query systems
- Good data models and consistent well understood semantics
- Sophisticated processing
- visualization
- reporting
- algorithmic processing and prediction
5.2 Problem1: The event data firehose
- Event data rising
- google’s fortune is actually generated by a relevance pipeline built on clicks and impressions — events
- that would be huge amount of data,
5.3 Problem 2: The explosion of specialized data systems
- Explosion of specialized data systems
- The combination of more data of more varieties and a desire to get this data into more systems leads to a huge data integration problem.
5.4 Log Structured Data Flow
5.4.1 How the flow work
- Recipe: Take all the organization’s data and put it into a central log for real time subscription
- How the flow works
- Each logical data source can be modeled as its own log
- A data source could be an application that logs out events, or a db table that accepts modifications
- each subscribing system reads from this log as quickly as it can, applied each new record to its own store, and advances its position in the log
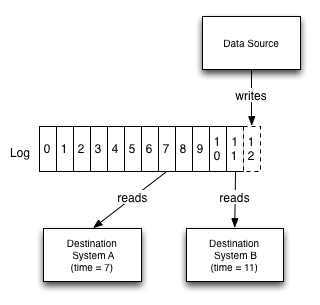
Log gives a logical clock for each change against which all subscriber can be measured
- Consider a case where there is a database and a collection of caching servers
- log provides a way to synchronize the updates to all these systems and reason about the point of time of each of these systems
- Let’s say we write a record with log entry X and then need to do a read from the cache. If we want to guarantee we don’t see stale data, we just need to ensure we don’t read from any cache which has not replicated up to X.
Log also acts as a buffer that makes data production asynchronous from data consumption
- satisfy different requirements like
- A batch system such as Hadoop or a data warehouse may consume only hourly or daily,
- A real-time query system may need to be up-to-the-second.
- satisfy different requirements like
Consumer only need to know about the log and not any details of the system of origin
What values most from author perspective
- The pipeline they built for process data, though a bit of a mess, were actually extremely valuable . Just the process of makeing data available in a new processing system (Hadoop) unblocked a lot of possibilities
- Many new products and analysis just came from putting together multiple pieces of data that had previously been locked up in specialized systems
- The pipeline they built for process data, though a bit of a mess, were actually extremely valuable . Just the process of makeing data available in a new processing system (Hadoop) unblocked a lot of possibilities
LinkedIn Went Through from O(N^2) to O(2N)
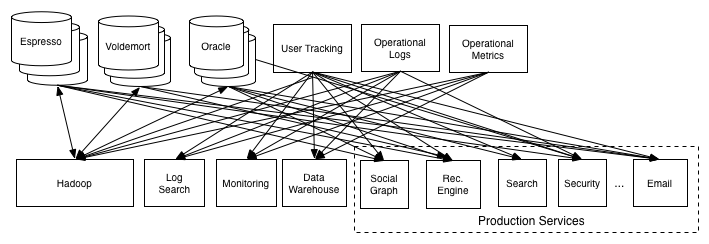
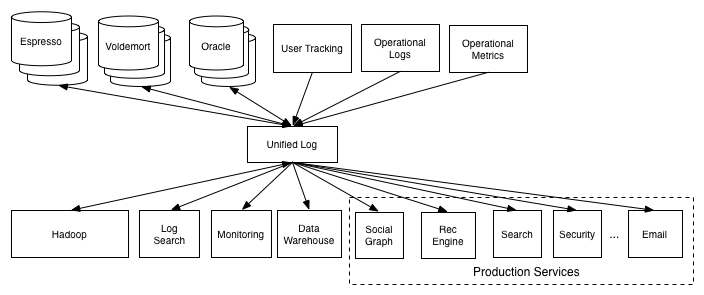
- Actions for the migration
- Isolate each consumer from the source of the data
- Create a new data system to be both a data source and a data destination
- Here LinkedIn create Kafka
- Kinesis is similar to Kafka as AWS use it to connects all different distributed systems as a piping
5.4.2 Relationship to ETL and the Data Warehouse
Data Warehouse
- target
- A repository of the clean, integrated data structured to support analysis
- what be involved
- periodically extracting data from source databases
- munging it into some kind of understandable form
- loading it into a central data warehouse
- Problems
- coupling the clean integrated data to the data warehouse.
- cannot get real time feed
- organization perspective
- The incentives are not aligned: data producers are often not very aware of the use of the data in the data warehouse and end up creating data that is hard to extract or requires heavy, hard to scale transformation to get into usable form.
- the central team never quite manages to scale to match the pace of the rest of the organization, so data coverage is always spotty, data flow is fragile, and changes are slow.
- coupling the clean integrated data to the data warehouse.
- target
ETL
- tasks
- extraction and data cleanup process, liberating data locked up in a variety of systems in the organization and removing an system-specific non-sense
- data is restructured for data warehousing queries (i.e. made to fit the type system of a relational DB, forced into a star or snowflake schema, perhaps broken up into a high performance column format,
- problems
- still, we need such data in real time as well for low latency processing as well as indexing in real time storage systems
- tasks
A better approach as ETL and Data Warehouse substitution
Have a central pipeline, the log, with a well defined API for adding data
Responsibility Classification
Producer of the data feed: integrating with this pipeline and providing a clean, well-structured data feed
Datawarehouse team now only care about loading structured feeds of data from the central log and carrying out transformation specific to their system
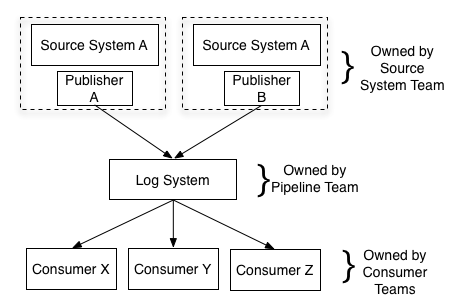
5.4.3 Log Files and Events
- Current structure also enables decoupled and event driven systems
5.4.4 How to build scalable logs
- Need a log system that’s fast, cheap, scalable enough to make this practical at scale
- LinkedIn in 2013 actually has already support 60 billion unique message writes through Kafka per day
- Kafka achieve such high throughput via
- Partitioning the log
- each partition is a totally ordered log, but there is no global ordering between partitions
- Assignment of the messages to a particular partition is controllable by the writer, with most users choosing to partition by some kind of key
- Replication
- Each partition is replicated across a configurable number of replicas
- At any time, a single one of them will act as the leader, if the leader fails, one of the replicas will take over as leader
- Order Guarantee
- each partition is order preserving, and Kafka guarantees that appends to a particular partition from a single sender will be delivered in the order they are sent.
- Optimizing throughput by batching reads and writes
- occurs when
- sending data
- writes to disk
- replication between servers
- data transfer to consumers
- acknowledging committed data
- occurs when
- Avoiding needless data copies
- Use a simple binary format that is maintained between in memory log, on disk log and in network data transfers
- Thus we could make use of numerous optimizations including zero copy data transfer https://en.wikipedia.org/wiki/Zero-copy
- Partitioning the log
6. Real Time Data Processing
Computing derived data streams
6.1 Definition of Stream Processing
- Infrastructure for continuous data processing
- computational model can be general like MapReduce or other distributed processing frameworks,
- need the ability to produce low latency results
- Instead of batch get and process, we could do continuous changes
- it is just processing which includes a notion of time in the underlying data being processed and does not require a static snapshot of the data so it can produce output at a user-controlled frequency instead of waiting for the “end” of the data set to be reached. In this sense, stream processing is a generalization of batch processing, and, given the prevalence of real-time data, a very important generalization
- Log role
- making data available in real-time multi-subscriber data feeds.
6.2 Stateful Real Time Processing
- Stateful real time processing means some more sophisticated operations, like counts, aggregations, or joins over windows in the stream
- We need to maintain certain state in such case
- Strategies for that
- Keep state in memory
- cons
- if the process crash, it would lose its intermediate state
- if the state is only maintained over a window, the process could fall back to the point where the window began
- cons
- Store all state in a remote storage system, and join over the network to that store
- cons
- no locality of data and lots of network round trips
- cons
- Duality of tables and logs
- a stream processor can keep its state in a local table or index — a bdb, leveldb
- the contents of this store is fed from its input streams
- it could journal out a changelog for this local index it keeps to allow it to restore its state in the event of a crash and restart
- This mechanism allows a generic mechanism for keeping co-partitioned state in arbitrary index types local with the incoming stream data.
- when facing process fails
- recover its index from the changelog
- changelog itself is the transformation of the local state into a sort of incremental record at a time backup
- Keep state in memory
6.3 Log Compaction
- Log need to be cleaned up someway to save the space
- In Kafka, clean up has two options depending on whether the data contains keyed updates or event data
- for event data, supports just retain a window of data
- configured to be few days
- also could be configured as space
- for keyed data
- as the complete log give you ability to replay it to recreate the state of the source system
- but we could do log compaction by removing obsolete records — records whose primary key has a more recent update
- for event data, supports just retain a window of data
7. Distributed System Design
How practical systems can be simplified with a log centric design
7.1 Distributed system design thought
Log here is responsible for data flow, consistency and recovery
Directions
- Coalescing lots of little instances of each system into a few big clusters
Possibility 1
- separation of systems remains more or less as it is for a good deal longer.
- an external log that integrates data will be very important.
Possibility 2
- re-consolidation in which a single system with enough generality starts to merge back in all the different functions into a single uber-system.
- extremely hard
Possibility 3
- data infrastructure could be unbundled into a collection of services and application-facing system apis
- use open source, like in Java stacks
- zookeeper
- handle system coordination
- mesos and yarn
- process virtualization
- resource management
- netty, jetty
- handle remote communication
- protobuf
- handle serialization
- kafka and bookeeper
- provide a backing log
- zookeeper
- path towards getting the simplicity of the single system in a more diverse and modular world that continues to evolve. If the implementation time for a distributed system goes from years to weeks because reliable, flexible building blocks emerge, then the pressure to coalesce into a single monolithic system disappears.
7.2 Usage of log in system architecture
Usage of log in system architecture
- Handle data consistency (whether eventual or immediate) by sequencing concurrent updates to nodes
- Provide data replication between nodes
- Provide “commit” semantics to the writer (i.e. acknowledging only when your write guaranteed not to be lost)
- Provide the external data subscription feed from the system
- Provide the capability to restore failed replicas that lost their data or bootstrap new replicas
- Handle rebalancing of data between nodes.
What mentioned above is actually a large portion of what a distributed data system does. left over is mainly related with client facing query API and indexing strategy
System Look
- System is divided into two logical pieces
- log
- capture the state changes in sequential order
- serving layer
- store whatever index is required to serve queries
- log
- writes could go directly to the log or may be proxied by the serving layer
- writes to the log yields a logical timestamp, if the system is partitioned, then the log and serving nodes will have the same number of partitions, though they may have very different numbers of machines
- System is divided into two logical pieces
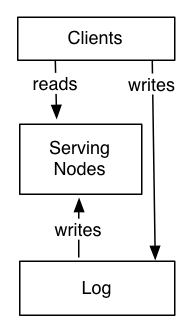
The client can get read-your-write semantics from any node by providing the timestamp of a write as part of its query—a serving node receiving such a query will compare the desired timestamp to its own index point and if necessary delay the request until it has indexed up to at least that time to avoid serving stale data.
For handling restoring failed nodes or moving partitions from node to node
- have the log retain only a fixed window of data and combine this with a snapshot of the data stored in the partition
- it’s possible for the log to retain a complete copy of data and garbage collect the log itself
Reference
- https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
- https://kafka.apache.org/documentation.html#design
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:Real time data’s unifying abstraction
文章字数:2.8k
本文作者:Leilei Chen
发布时间:2022-01-29, 10:14:20
最后更新:2022-01-29, 10:20:03
原始链接:https://www.llchen60.com/Real-time-data%E2%80%99s-unifying-abstraction/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

