Cassandra
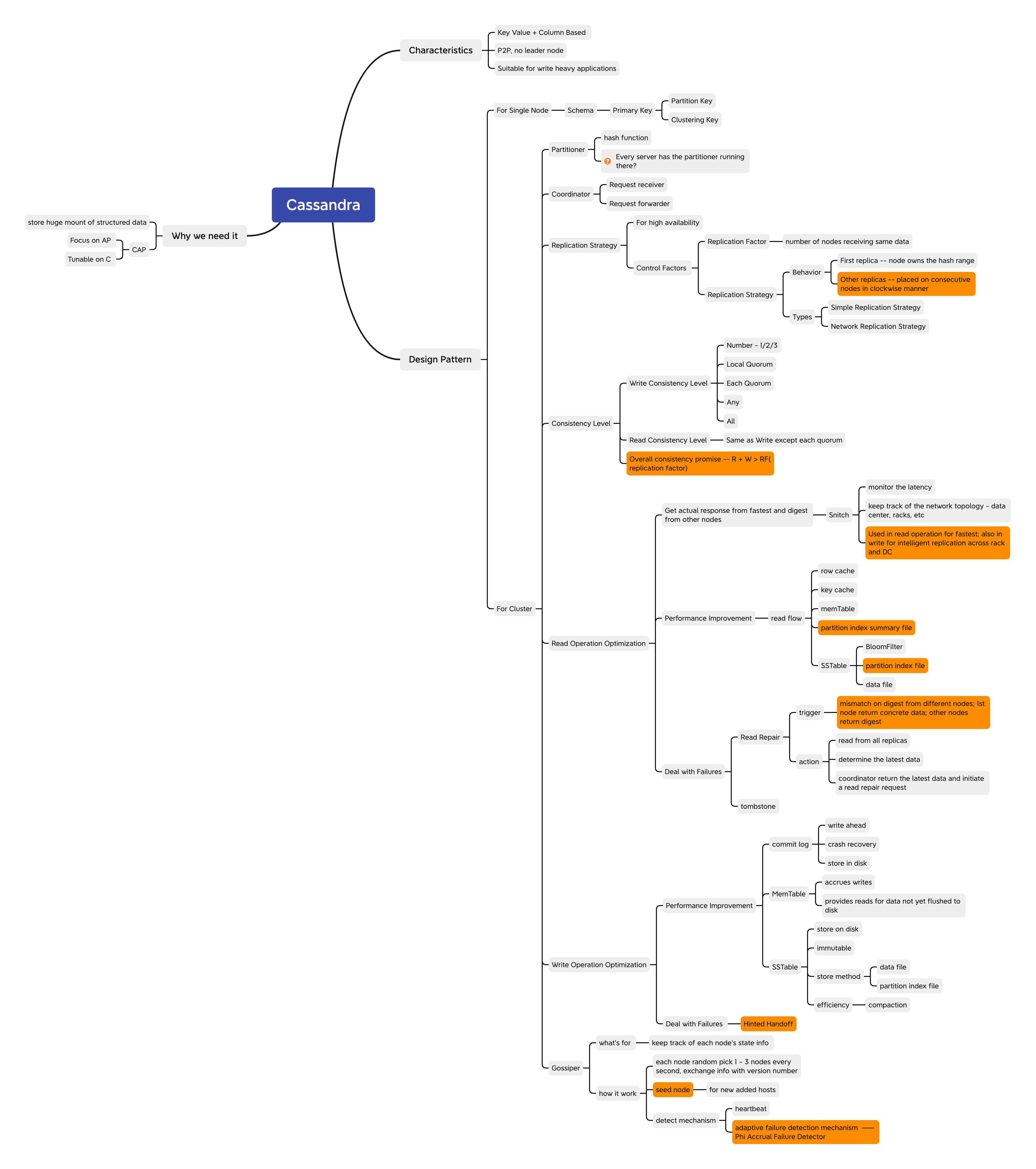
1. Introduction
1.1 Background
- We wanna have a distributed and scalable system that can store a huge amount of structured data, which is indexed by a row key where each row can have an unbounded number of columns.
- Cassandra was originally developed at Facebook in 2007 for index search feature. It’s designed to provide scalability, availability, and reliability to store large amounts of data.
- It combines nature of Dynamo which is a key value store and the data model of Bigtable which is a column based data store
- Cassandra is in favor of availability and partition tolerance, it could be tuned with replication factor and consistency levels to meet strong consistency requirements, and of course with a performance cost.
- It uses peer to peer architecture, with each node connected to all other nodes
- Each Cassandra node performs all database operations and can serve client requests without the need for any leader node.
1.2 Use cases
- Store key value data with high availability
- Time series data model
- Due to its data model and log structured storage engine, cassandra benefits from high performing write operations, This also make it well suited for storing and analyzing sequentially captured metrics
- Write Heavy Applications
- Suited for write intensive applications such as time series streaming services, sensor logs, and IoT applications
2. High Level Architecture
2.1 Common Terms
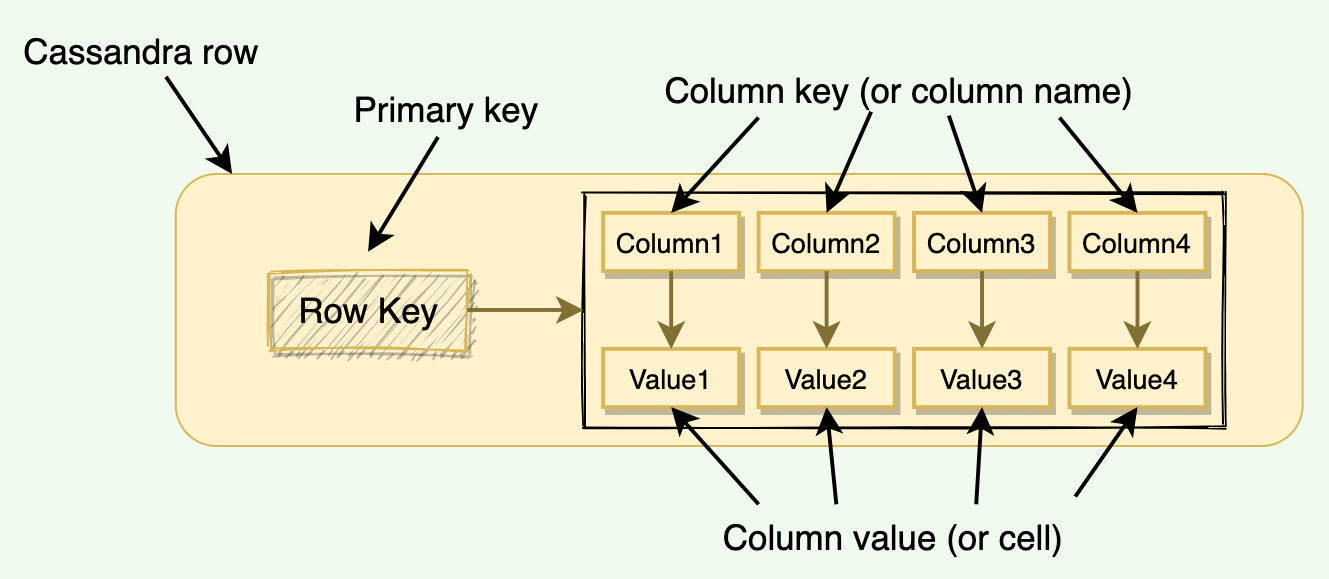
- Column
- A key value pair and is the most basic unit of data structure
- Column Key: Uniquely identifies a column in a row
- Column Value: Store a value or a collection of values
- Row
- A container for columns referenced by primary key. Cassandra does not store a column that has a null value, this saves a lot of space
- Table
- A container of rows
- Keyspace
- A container for tables that span over one or more Cassandra nodes
- Cluster
- Container of Keyspace
- Node
- A computer system running an instance of Cassandra,
- Can be a physical host, a machine instance in the cloud or even a docker container
2.2 Data Partitioning
- Cassandra use consistent hashing as DynamoDB does
2.3 Primary Key
- The primary key consists of two parts: E.G Primary Key as (city_id, employee_id)
- Partition Key
- Decides how data is distributed across nodes
- city_id is the primary key, means the data will be partitioned by the city_id field, all rows with the same city_id will reside on the same node
- Clustering Key
- Decides how data is stored within a node
- We could have multiple clustering keys, clustering columns specify the order that the data is arranged on a node.
- employee_id is the clustering key. Within each node, the data is stored in sorted order according to the employee_id column.
- Partition Key
2.4 Partitioner
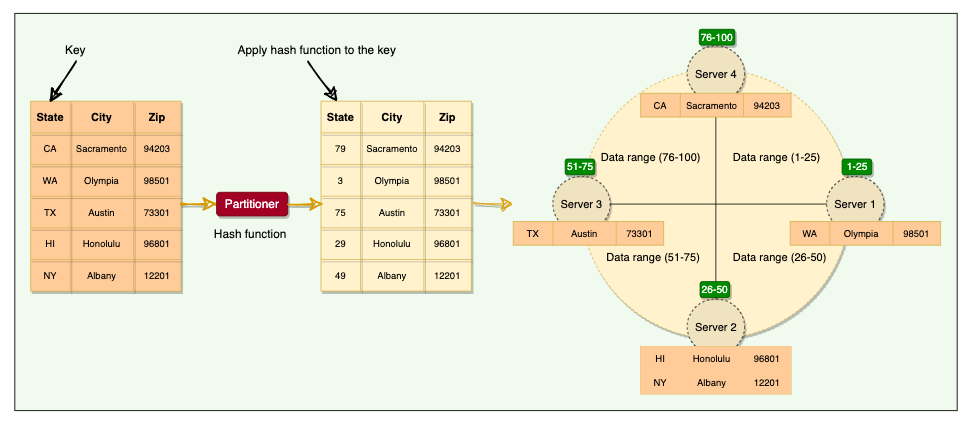
- Responsible for determining how data is distributed on the consistent hash ring.
- Cassandra use Murmur3 hashing function — which will always produce the same hash for a given partition key
- All Cassandra nodes learn about the token assignments of other nodes through gossip. This means any node can handle a request for any other node’s range. The node receiving the request is called the coordinator, and any node can act in this role. If a key does not belong to the coordinator’s range, it forwards the request to the replicas responsible for that range.
2.5 Coordinator Node
- A client may connect to any node in the cluster to initiate a read or write query. This node is known as the coordinator node, the coordinator identifies the nodes responsible for the data that is being written or read and forwards the queries to them
3. Low Level Architecture
3.1 Replication Strategy
Each node in Cassandra serves as a replica for a different range of data.
It stores multiple copies of data and spreads them across various replicas.
The replication behavior is controlled by two factors
Replication Factor
- Decides how many replicas the system will have
- This represents the number of nodes that will receive the copy of the same data
- Each keyspace in cassandra can have a different replication factor
Replication Strategy
Decides which nodes will be responsible for the replicas
The node that owns the range in which the hash of the partition key falls will be the first replica
All the additional replicas are placed on the consecutive nodes
Cassandra places the subsequent replicas on the next nodes in a clockwise manner
Two kinds of replication strategies
Simple Replication Strategy
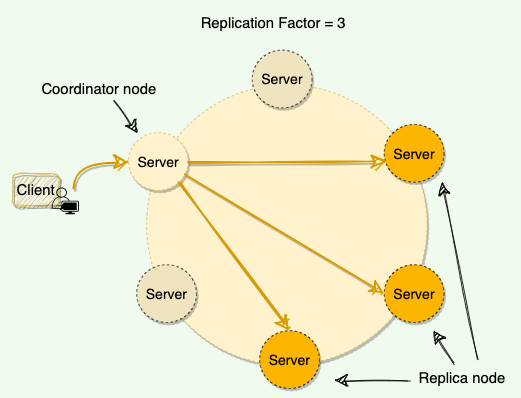
- Used for a single data center cluster
- Cassandra places the first replica on a node determined by the partitioner and the subsequent replicas on the next node in a clockwise manner
Network Topology Strategy
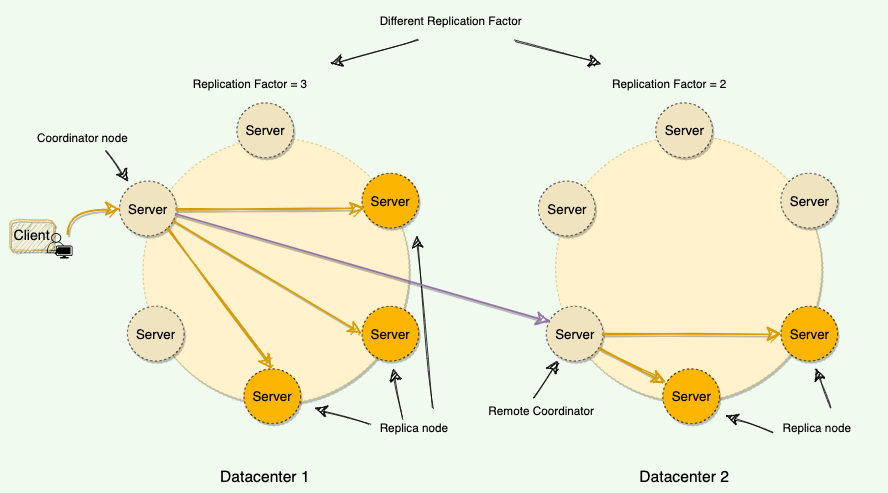
- Used for multiple data centers
- We can specify different replication factors for different data centers. We could then specify how many replicas will be placed in each data center
- Additional replicas, in the same data center, are placed by walking the ring clockwise until reaching the 1st node in another rack. This is done to guard against a complete rack failure, as nodes in the same rack(or similar physical grouping) tend to fail together due to power, cooling or network issues.
3.2 Consistency Levels
- Definition
- Minimum number of nodes that must fulfill a read or write operation before the operation can be considered successful
- It allows use to specify different consistency levels for read and write
- It also has tunable consistency level
- Tradeoff between consistency and response time
- As a higher consistency level means more nodes need to respond to a read or write query, giving user more assurance that the values present on each replica are the same
3.2.1 Write Consistency Levels
- Consistency Levels specify how many replica nodes must respond for the write to be reported as successful to the client
- Level is specified per query by the client
- Cassandra is eventually consistent, updates to other replica nodes may continue in the background
- How does Cassandra perform a write operation?
- Coordinator node contacts all replicas, as determined by the replication factor , and consider the write successful when a number of replicas equal to the consistency level acknowledge the write
- Write Consistency Levels List:
- One/ Two/ Three
- The data must be written to at least the specified number of replica nodes before a write is considered successful
- Quorum
- Data must be written to at least a quorum of replica nodes
- Quorum is defined as
floor(RF/2 + 1)RF represents replication factor
- All
- ensures the data is written to all replica nodes
- provides the highest consistency but lowest availability as writes will fail if any replica is down
- Local Quorum
- Ensure that data is written to a quorum of nodes in the same datacenter as the coordinator
- Does not wait for the response from the other data centers
- Each Quorum
- Ensures that the data is written to a quorum of nodes in each datacenter
- Any
- The data must be written to at least one node
- In the extreme case, when all replica nodes for the given partition key are down, the write can still succeed after a hinted handoff (see 3.2.4 section) has been written.
- In this case, an any write could succeed with hinted handoff, but it will not be readable until the replica nodes for that partition has recovered and the latest data is written on them
- One/ Two/ Three
3.2.2 Read Consistency Levels
Read Query Consistency Level specify how many replica nodes must respond to a read request before returning the data
It has the same consistency levels for read operations as that of write operations exception Each_Quorum cause it’s too expensive
To achieve strong consistency, we need to do
R + W > RFR represents read replica count, W represents write replication count, RF represents replication factor- All client reads will see the most recent write in this scenario, and we will have strong consistency
How does Cassandra perform a read operation?
Coordinator always sends the read request to the fastest node
- E.G for quorum=2, the coordinator sends the requests to the fastest node and the digest of the data from the second fastest node
- digest is the checksum of the data, we use this to save network bandwidth
- E.G for quorum=2, the coordinator sends the requests to the fastest node and the digest of the data from the second fastest node
if the digest doesn’t match, means some replica do not have the latest version of data
Coordinator then reads the data from all the replicas to determine the latest data
Then coordinator returns the latest data to the client and initiates a read repair request
The read repair request will help push the newer version of data to nodes with the older version
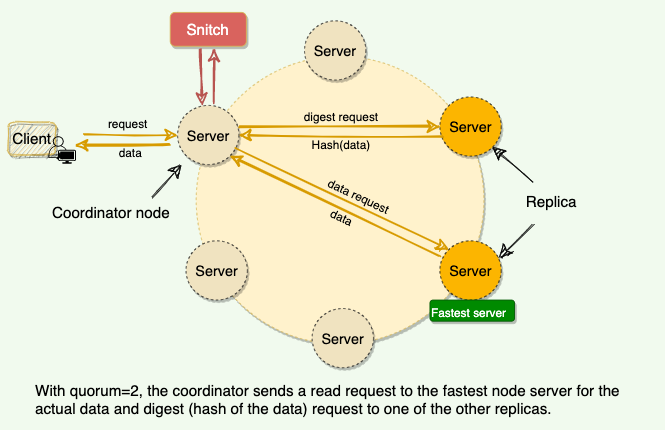
latest write timestamp is used as a mark for the correct version of data, read repair operation is performed only in a portion of the total reads to avoid performance degradation
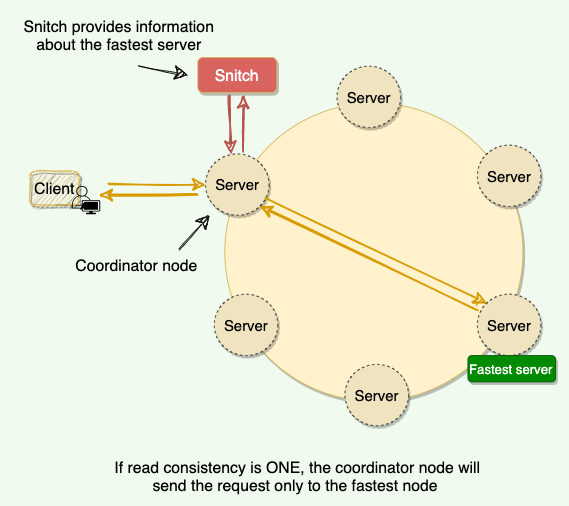
3.2.3 Snitch
Functions
- Application that determines the proximity of nodes within the ring, also tells which nodes are faster — monitor the read latencies
- It keeps track of the network topology of Cassandra nodes, determines which data centers and racks nodes belong to
- Replication strategy use this information provided by the Snitch to spread the replicas across the cluster intelligently. It could do its best by not having more than one replica on the same rack
Cassandra nodes use this info to route read/ write requests efficiently
3.2.4 Hinted Handoff
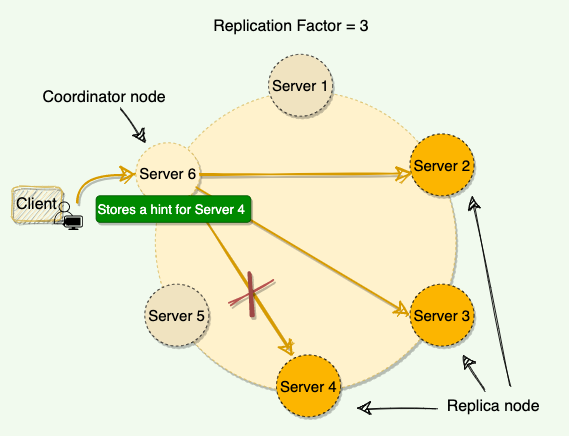
- To let Cassandra still serve write requests even when nodes are down
- When a node is down, the coordinator nodes writes a hint in a text file on local disk
- Hint contains the data itself along with information about which node the data belongs to
- Recover from gossiper — When the coordinator node discovers from the gossiper that a node for which it holds hints has recovered, it forwards the write request for each hint to the target
- Recover from routine call — each node every ten minutes checks to see if the failing node, for which it is holding any hints, has recovered
- With consistency level ‘Any,’
- if all the replica nodes are down, the coordinator node will write the hints for all the nodes and report success to the client.
- However, this data will not reappear in any subsequent reads until one of the replica nodes comes back online, and the coordinator node successfully forwards the write requests to it.
- This is assuming that the coordinator node is up when the replica node comes back.
- This also means that we can lose our data if the coordinator node dies and never comes back. For this reason, we should avoid using the ‘Any’ consistency level
- For node offline for quite long
- Hints can build up considerably on other nodes
- When it back online, other nodes tend to flood that node with write requests
- It would cause issues on the node, as it is already trying to come back after a failure
- To address this, Cassandra limits the storage of hints to a configurable time window
- By default, set the time window to 3 hours. Post that, older hints will be removed — now the recovered nodes will have stale data
- The stale data would be fixed during the read path, it will issue a read repair when it sees the stale data
- When the cluster cannot meet the consistency level specified by the client, Cassandra fails the write request and does not store a hint .
3.3 Gossiper
3.3.1 How does Cassandra use Gossip Protocol?
- What’s for?
- Cassandra uses gossip protocol that allows each node to keep track of state information about the other nodes in the cluster.
- It’s a Peer to Peer communication mechanism in which nodes periodically exchange state information about themselves and other nodes they know about
- How it works?
- Each node initiates a gossip round every second to exchange state info about themselves with one to three other random nodes
- Each gossip message has a version associated with it, so during a gossip exchange, older info is overwritten with the most current state for a particular node
- Generation number
- Each node stores a generation number which will be incremented every time a node restart
- Node receiving the gossip message can compare the generation number it knows and the gossip message’s generation number
- If the generation number in the gossip message is higher, it knows the node was restarted
- Seed nodes
- For node starting up for the first time
- Assist in gossip convergence, thus guarantee schema/ state changes propagate regularly
3.3.2 Node Failure Detection
- Disadvantages for heartbeat
- outputs a boolean value telling us if the system is alive or not;
- there is no middle ground.
- Heartbeating uses a fixed timeout, and if there is no heartbeat from a server, the system, after the timeout, assumes that the server has crashed.
- If we keep the timeout short, the system will be able to detect failures quickly but with many false positives due to slow machines or faulty networks.
- On the other hand, if we keep the timeout long, the false positives will be reduced, but the system will not perform efficiently for being slow in detecting failures.
- Use adaptive failure detection mechanism —— Phi Accrual Failure Detector
- Use historical heartbeat information to make the threshold adaptive
- It outputs the suspicion level about a server
- As a node’s suspicion level increases, the system can gradually decide to stop sending new requests to it
- It makes the distributed system efficient as it takes into account fluctuations in the network env and other intermittent server issues before declaring a system completely dead
3.4 Anatomy of Cassandra’s Write Operation
Cassandra stores data both in memory and on disk to provide both high performance and durability. Every write includes a timestamp, write path involves a lot of components:
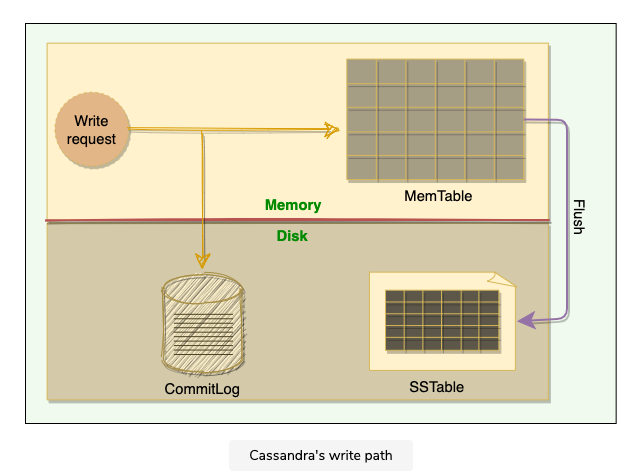
- Each write is appended to a commit log, which is stored on disk
- It is then written to Memtable in memory
- Periodically, MemTables are flushed to SSTables on the disk
- Periodically, compaction runs to merge SSTables
3.4.1 Commit Log
- When a node receives a write request, it immediately writes data to a commit log
- Commit log is a write ahead log stored on disk
- Used as a crash recovery mechanism to support Cassandra’s durability goals
- A write will not be considered successful on the node until it’s written to the commit log
- This ensures if a write operation does not make it to the in-memory store, it will still be possible to recover the data
- If we shut down the node or it crashes unexpectedly, the commit log can ensure that data is not lost; that’s because if the node restart, the commit log gets replayed
3.4.2 MemTable
- After written to the commit log, the data is written to a memory resident data structure called memTable
- Each node has a MemTable in memory for each Cassandra table
- Each MemTable contains data for a specific Cassandra table, and it resembles that table in memory
- Each MemTable accrues writes and provides reads for data not yet flushed to disk
- Commit log stores all the writes in sequential order, with each new write appended to the end; whereas MemTable stores data in the sorted order of partition key and clustering columns
- After writing data to the commit log and MemTable, the node sends an acknowledgement to the coordinator that the data has been successfully written
3.4.3 SStable
- When the number of objects stored in the MemTable reaches a threshold, the contents of the MemTable are flushed to disk in a file called SSTable
- At this point, a new MemTable is created to store subsequent data
- The flush is non blocking operation
- Multiple Memtables may exist for a single table
- One current, and the rest waiting to be flushed
- When the MemTable is flushed to SStables, corresponding entries in the commit log are removed
- SStable —Sorted String Table
- Once a MemTable is flushed to disk as an SStable, it is immutable and cannot be changed later
- Each delete or update is considered as a new write operation
- The current data state of a Cassandra table consists of its MemTables in memory and SSTables on the disk.
- Therefore, on reads, Cassandra will read both SSTables and MemTables to find data values, as the MemTable may contain values that have not yet been flushed to the disk.
- The MemTable works like a write-back cache that Cassandra looks up by key
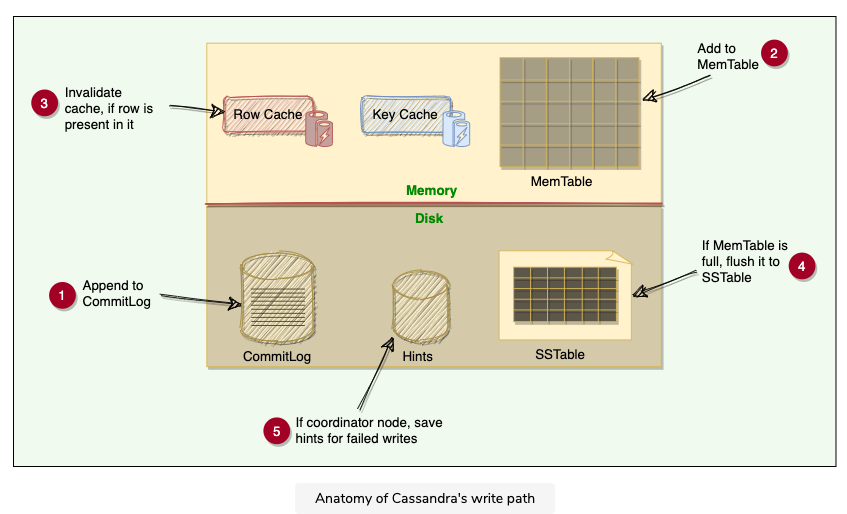
3.5 Anatomy of Cassandra’s Read Operation
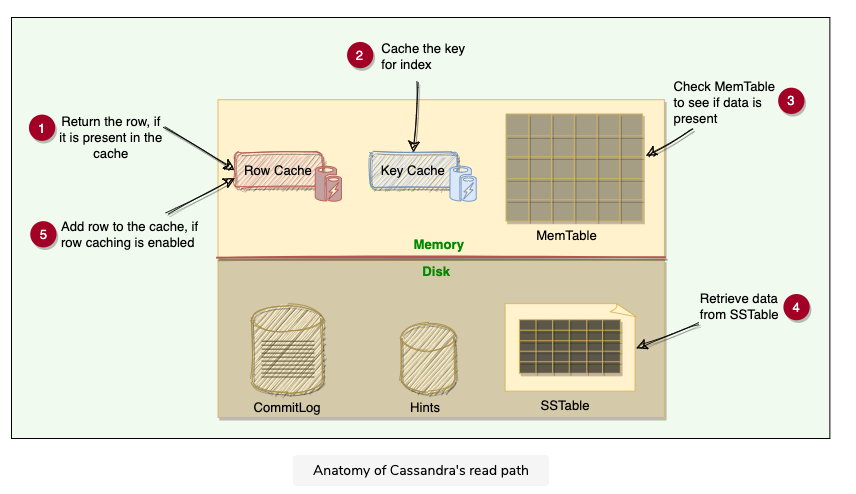
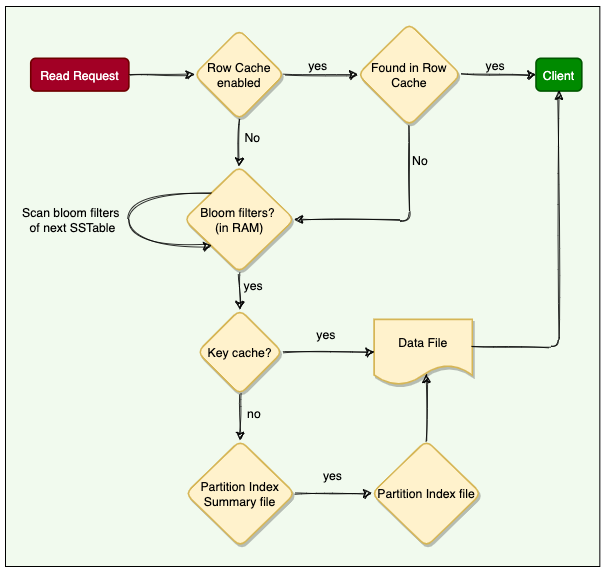
3.5.1 Caching
- Row Cache
- Cache frequently read/ hot rows
- Stores a complete data row, which can be returned directly to the client if requested by a read operation
- Could significantly speed up read access for frequently accessed rows, at the cost of more memory usage
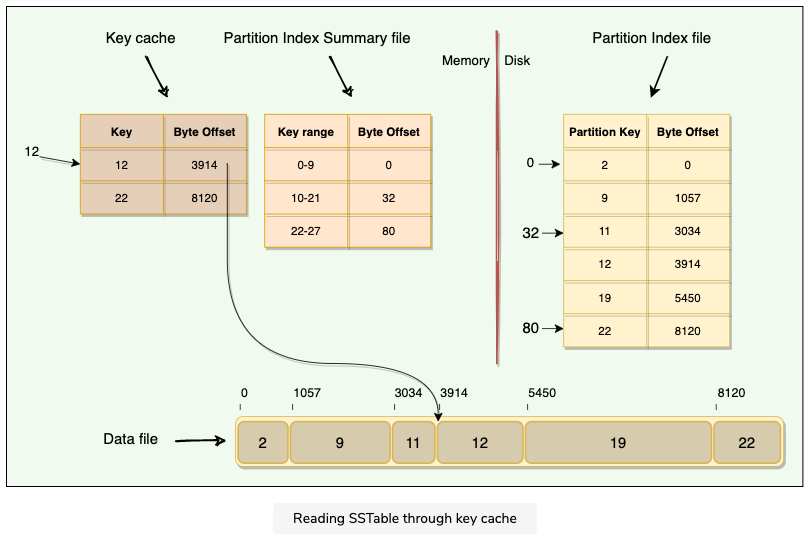
- Key Cache
- Stores a map of recently read partition keys to their SSTable offsets
- This facilitates faster read access into SSTables and improves the read performance
- Use less memory comparing with row cache and provides a considerable improvement for read operations
- Chunk Cache
- Chunk Cache is used to store umcompressed chunks of data read from SSTable files that are accessed frequently
3.5.2 Read From MemTable
- When a read request come in, node performs a binary search on the partition key to find the required partition and then return the row
3.5.3 Read From SSTable
Bloom Filters
- Each SSTable has a Bloom Filter associated with it, which tells if a particular key is present in it or not
- Used to boost performance of read operations
- It’s a very fast, non deterministic algorithms for testing whether an element is a member of a set
- It’s possible to get a false positive but never a false negative
- Theory
- It works by mapping the values in a data set into a bit array and condensing a larger data set into a digest string with a hash function
- Filters are stored in memory and are used to improve performance by reducing the need for disk access on key lookups
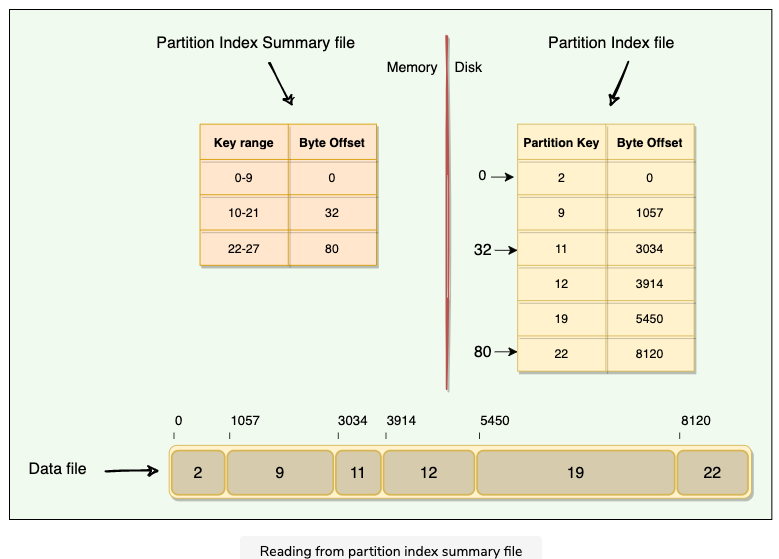
How are SSTables stored on the disk?
Consists of two files
Data File
- Actual data is stored here
- It has partitions and rows associated with those partitions
- Partitions are in sorted order
Partition Index File
Stored on disk, partition index file stores the sorted partition keys mapped to their SSTable offsets
Enable locating a partition exactly in an SSTable rather than scanning data
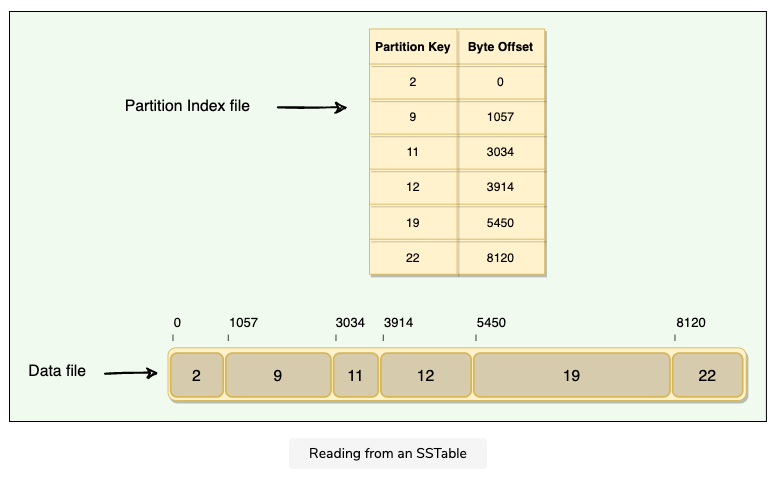
Partition Index Summary File
It’s stored in memory, stores the summary of the partition index file for performance improvement
Two level index, e.g, search for key=19
in partition index summary file, it lays to key range 10 - 21
then we could go to byte offset 32,
in partition index file , we start from 32, to find partition key 19, and then we could go to 5450
Read from KeyCache
As the Key Cache stores a map of recently read partition keys to their SSTable offset, it’s the fastest way to find the required row in the SSTable
Overall workflow
3.6 Compaction
3.6.1 Why we need compaction? And How it Works?
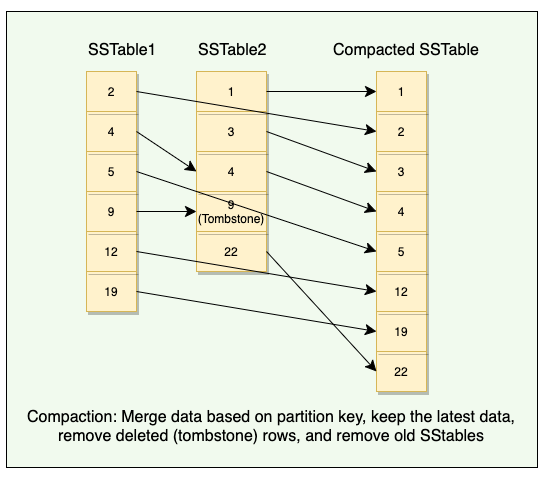
- SSTables are immutable, which helps Cassandra achieve high write speeds
- And flushing from MemTable to SSTable is a continuous process, which means we could have a large number of SSTables lying on the disk
- It’s tedious to scan all these SSTables while reading
- We need compaction thus we could merge multiple related SSTables into a single one to improve reading speed
- During compaction, the data in SSTables is merged, keys are merged, columns are combined, obsolete values are discarded, and a new index is created
3.6.2 Compaction Strategies
- SizeTiered Compaction Strategy
- Suitable for insert-heavy and general workloads
- Triggered when multiple SSTables of a similar size are present
- Leveled Compaction Strategy
- Optimize read performance
- Groups SSTables into levels, each of which has a fixed size limit which is ten times larger than the previous level
- Time Window Compaction Strategy
- Work on time series data
- Compact SSTables within a configured time window
- Ideal for time series data which is immutable after a fixed time interval
3.6.3 Sequential Writes
- Main reason that writes perform so well in Cassandra
- No reads or seeks of any kind are required for writing a value to Cassandra because all writes are append operations
- Compaction is intended to amortize the reorganization of data, but it uses sequential I/O to do so, which makes it efficient
3.7 Tombstones
3.7.1 What are Tombstones?
- Scenario
- We delete some data for a node that is down or unreachable, it would miss a delete
- When the node com back online later and a repair occurs, the node could resurrect the data due to re-sharing it with other nodes
- To prevent deleted data from being reintroduced, Cassandra used a concept of a Tombstone
- Tombstone
- Similar to the idea of soft delete from the relational database
- When we delete, Cassandra does not delete it right away, instead, it associated a tombstone with it, with Time to Expiry
- It’s a marker to indicate data that has been deleted
- When we execute a delete operation, data is not immediately deleted
- Instead, it’s treated as an update operation that places a tombstone on the value
- Default Time to Expiry is set to 10 days
- If the node is down longer than this value, it should be treated as failed and replaced
- Tombstones are removed as part of compaction
3.7.2 Common problems associated with Tombstones
- Takes storage space
- When a table accumulates many tombstones, read queries on that table could become slow and can cause serious performance problems like timeouts.
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:Cassandra
文章字数:3.6k
本文作者:Leilei Chen
发布时间:2021-09-17, 21:05:55
最后更新:2021-09-17, 21:41:43
原始链接:https://www.llchen60.com/Cassandra/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

