Redis基本架构
Redis基本架构
1. Overview
为什么需要Redis
- key value内存数据库
- 支持丰富的数据结构,
- 性能非常高,可以支持很高的TPS
在使用Redis过程中可能遇到的一些问题
- CPU使用方面的问题
- 数据结构的复杂度
- 跨CPU核的访问
- 内存使用方面
- 主从同步和AOF的内存竞争
- 存储持久化方面
- SSD上做快照的性能抖动
- 网络通信方面
- 多实例时的异常网络丢包
- CPU使用方面的问题
如何进行学习 — 需要系统化
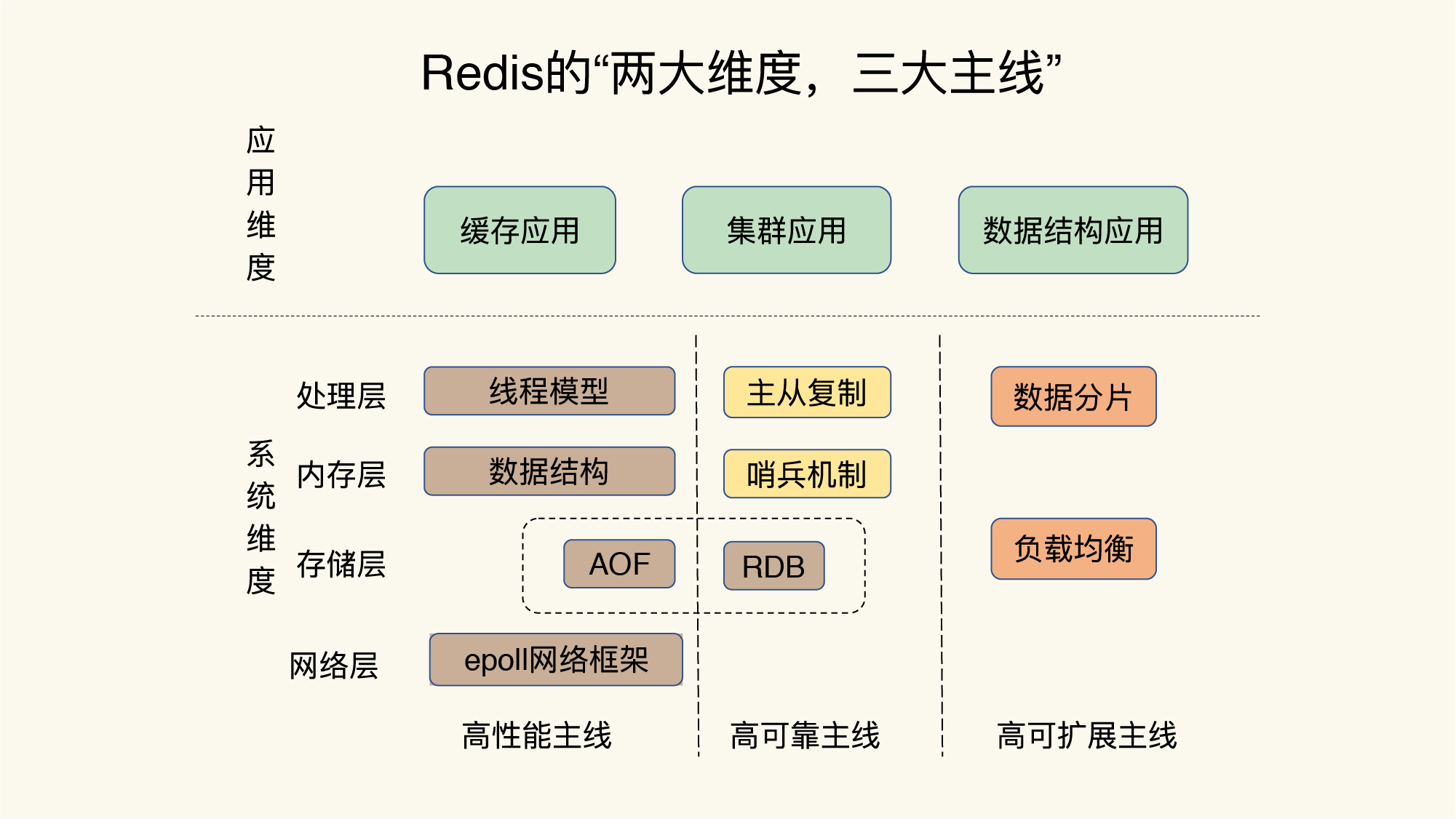
从应用维度和系统维度进行研究
分别看其在以下三个方面的表现
高性能
- 线程模型
- 数据结构
- 持久化
- 网络框架
高可靠
- 主从复制
- 哨兵机制
高可扩展性
数据分片
负载均衡
2. 如何构建一个键值数据库
- 目标
- 创建一个叫做SimpleKV的数据库
- 几个需要思考的问题
- 问题
- 里面会存什么样的数据 (数据模型)
- 需要对数据做什么样的操作 (操作接口)
- 为什么需要思考这种问题?
- 这影响到你认为这个数据库到底能做什么
- 譬如如果支持集合,那么对于存储用户信息的一个关系型数据库,我们也可以将用户Id作为Key,剩余信息作为一个集合存储到我们的键值数据库当中
- 这个点很有意思,可以直接将Redis当成一个数据库来使用
- 接口的定义确定了我们希望使用这个数据库做什么,是简单的get, put操作,还是说相对复杂的聚合型的操作
- 问题
- 脉络
- 访问框架
- 操作模块
- 内存空间分配 — 分配器
- 持久化
- 索引模块
2.1 可以存哪些数据?
- 基本数据类型 Key - Value
- 希望Value能够支持复杂类型
- memcache只支持String
- Redis支持String, HashMap, 列表,集合等
- 值得注意的点是不同的数据结构在实际使用的时候会有在性能,空间效率等方面的差异,从而导致不同的value操作之间也会存在差异
2.2 可以对数据做什么操作?
- PUT/ SET
- 新写入或者更新一个KV对
- GET
- 根据KEY读取相应的VALUE值
- DELETE
- 根据KEY删除整个KV对
- SCAN
- 根据一段Key的范围返回相应的value值
- Tips
- 当一个键值数据库的value类型多样的时候,也需要包含相应的操作接口的
2.3 数据库存储位置
- 可选方案
- 内存
- 读写非常快
- 访问速度在百ns级别
- 潜在风险是一旦断电,所有的数据都会丢失
- 外存
- 可以避免数据的丢失,但是受限于磁盘的慢速读写(几个ms)键值数据库的整体性能会被拉低
- 内存
- 考量的因素
- 主要应用场景
- 缓存场景
- 需要能够快速访问但允许丢失 — 可以采用内存保存键值数据
- memcache 和Redis都属于内存键值数据库
- 缓存场景
- 主要应用场景
2.4 数据库基本组件
- 一个基本的内部结构需要包括
- 访问框架
- 动态库访问
- 网络访问框架
- 操作模块
- 上述的一系列操作 DELETE/PUT/SCAN etc
- 索引模块
- 存储模块
- 访问框架
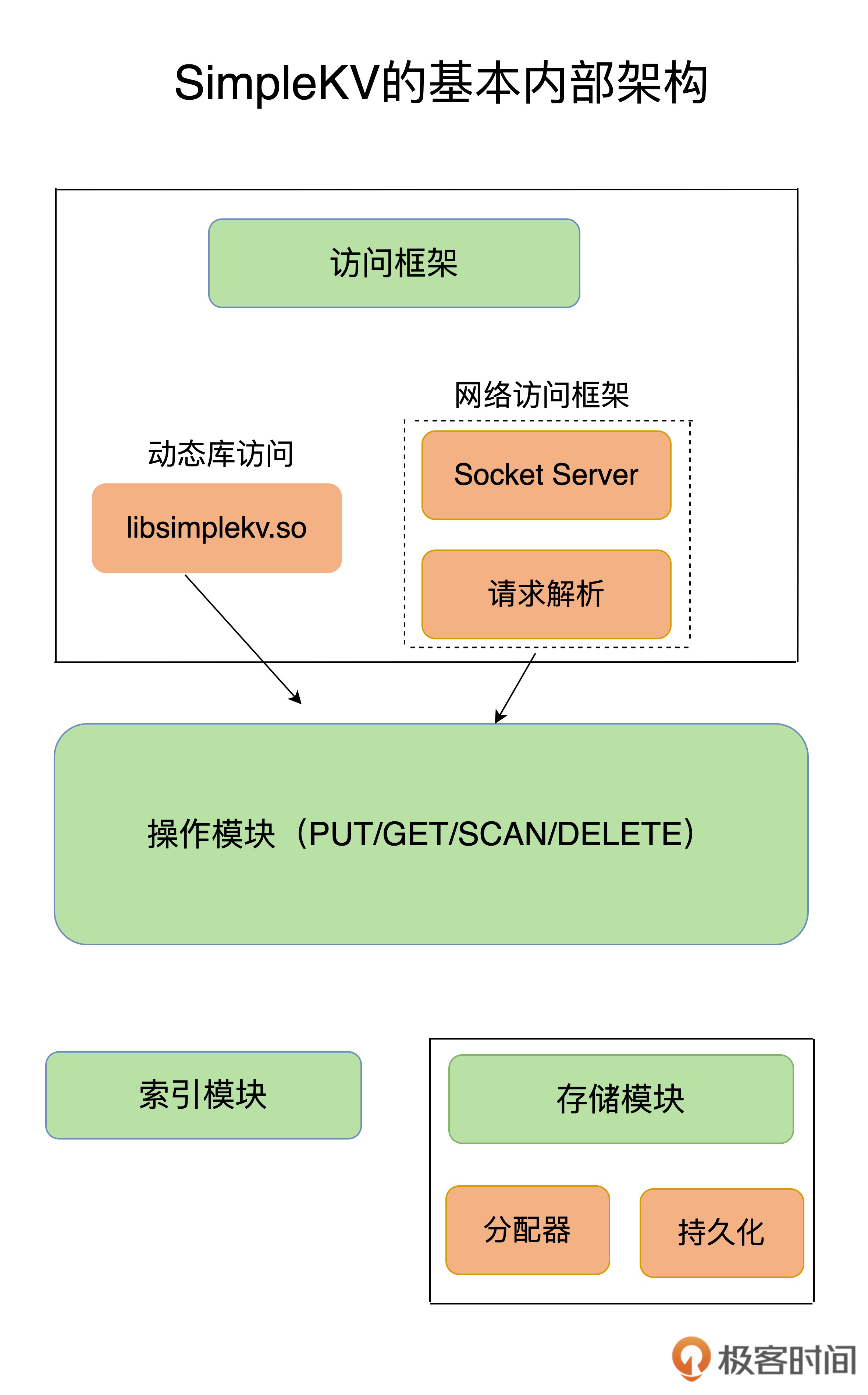
SimpleKV 内部架构
- 采用什么访问模式?— 连接层
- 通过函数库调用的方式供外部应用使用
- 比如图片当中的
libsimplekv.so就是通过动态链接库的形式链接到我们的程序当中,来提供键值存储功能- 在运行的时候载入的包,而不是像静态库一样在编译的时候就和目标代码进行连接
- 这样做可以减少对于空间的浪费,解决了静态库对程序的更新,部署和发布带来的麻烦
- https://www.zhihu.com/question/20484931
- 比如图片当中的
- 通过网络框架以Socket通信的形式对外提供键值对操作
- 系统设计上的问题 — 单线程,多线程还是多个进程来进行交互?IO模型的选择
- 网络连接的处理
- 网络请求的解析
- 数据存取的处理
- 系统设计上的问题 — 单线程,多线程还是多个进程来进行交互?IO模型的选择
- 通过函数库调用的方式供外部应用使用
- 如何定位键值对的位置?
- 需要依赖于键值数据库的索引模块
- 让键值数据库能够根据key找到相应value的存储位置,进而执行操作
- 索引类型
- 哈希表
- B+树
- 字典树
- Redis选用的是哈希表,是因为保存在内存中,内存的高性能随机访问特性可以很好地与哈希表O(1)的操作复杂度匹配
- 关于Redis值得注意的是它的value支持多种类型,当我们通过索引找到一个key对应的value后,仍然需要从value的复杂结构中进一步找到我们实际需要的数据
- 这个的复杂度取决于具体的数据类型
- Redis采用一些高效索引结构作为某些value类型的底层数据结构,可以为Redis实现高性能访问提供良好的支撑
- 索引类型
- 让键值数据库能够根据key找到相应value的存储位置,进而执行操作
- 需要依赖于键值数据库的索引模块
- 不同操作的具体逻辑是?
- 对于GET/SCAN 操作而言,根据value的存储位置返回value的值即可
- 对于PUT操作,需要为新的键值对分配内存空间
- —> 如何分配内存空间呢?
- 比较重要,当我们的value能支持多种类型的时候,那么如何高效使用内存空间就变得尤为重要了
- 对于DELETE操作,需要删除键值对,并释放相应的内存空间,这个过程由分配器完成
- 内存分配器
- 采用内存分配器glibc的malloc和free
- 但是键值对因为通常大小不一,glibc分配器在处理随机大小的内存块分配时表现会不太好。一旦保存的键值对数据规模过大,就可能造成较为严重的内存碎片的问题
- 采用内存分配器glibc的malloc和free
- 如何实现重启后快速提供服务?
- 持久化功能
- 采用文件形式,将键值数据通过调用本地文件系统的操作接口保存在磁盘上
- 需要考虑什么时候,什么间隔来做从内存到文件的键值数据的保存工作
- 也可以每一个键值对都进行持久化
- 坏处是因为每次都要写到磁盘里面,性能会受到很大影响
- 好处是能确保所有数据更新都会在磁盘里
- 可以周期性的将内存中的键值数据保存到文件当中,这样就可以避免频繁写盘操作的性能影响
- 潜在的风险就是数据仍然有可能丢失
- 采用文件形式,将键值数据通过调用本地文件系统的操作接口保存在磁盘上
- 持久化功能
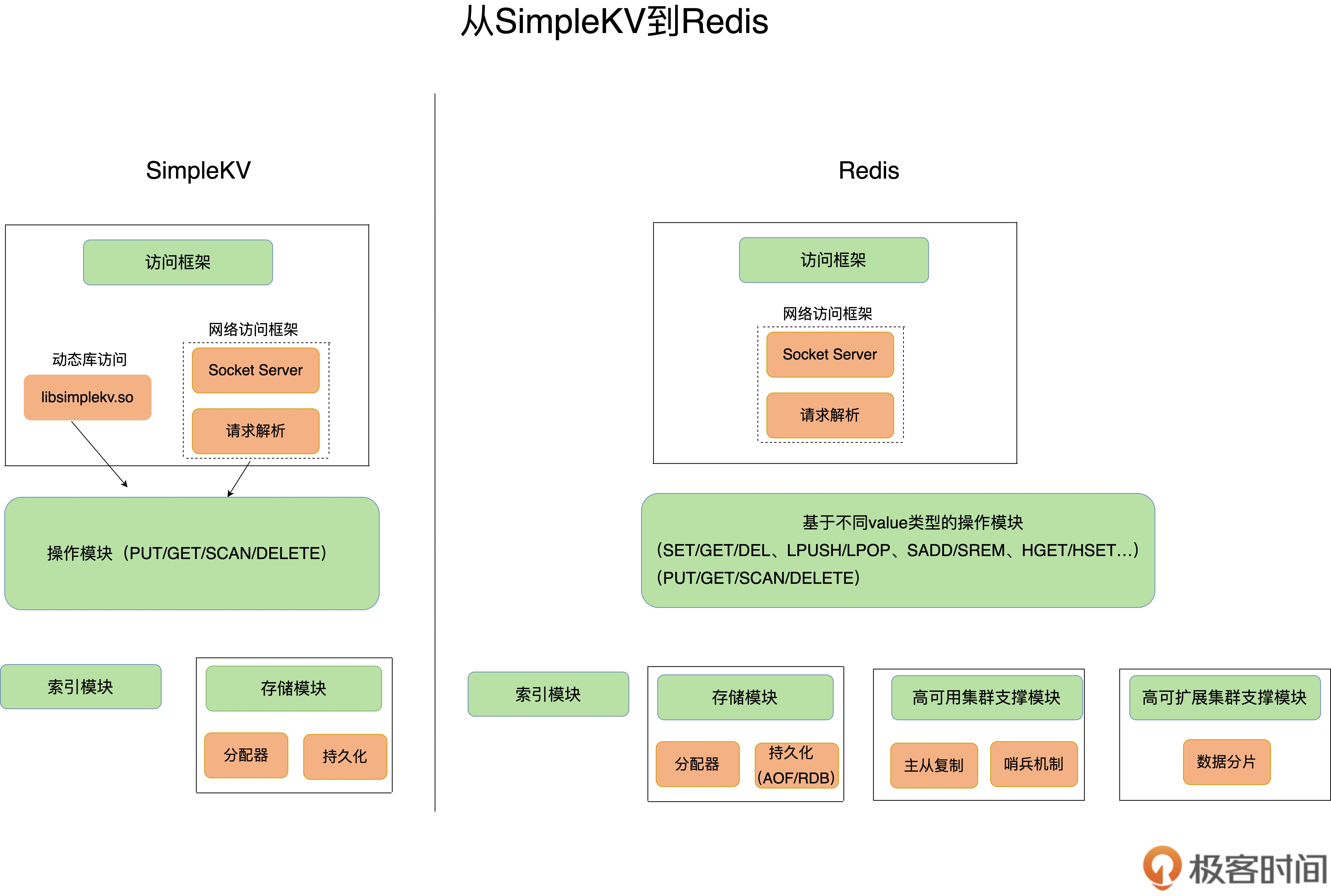
SimpleKV vs Redis
- SimpleKV和Redis的对比
- Redis通过网络访问,可以作为一个基础性的网络服务来进行访问
- value类型丰富,就带来了更多的操作接口
- 面向列表的LPush/ LPop
- 面向集合的SADD
- Redis持久化模块支持日志(AOF)和快照(RDB)两种模式
- Redis支持高可靠集群和高可扩展集群
Reference
- HiKV: A Hybrid Index Key-Value Store for DRAM-NVM Memory Systems
- 极客时间 - Redis核心技术与实战
- https://www.zhihu.com/question/20484931
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:Redis基本架构
文章字数:1.8k
本文作者:Leilei Chen
发布时间:2021-07-02, 08:10:44
最后更新:2021-07-03, 01:28:59
原始链接:https://www.llchen60.com/Redis%E5%9F%BA%E6%9C%AC%E6%9E%B6%E6%9E%84/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

