AWS essentials(3) - Core Services
- 1. AWS global infrastructure
- 2. Virtual Private Cloud (VPC)
- 3. AWS Security
- 4. Compute Services
- 5 Application Load Balancer
- 6. Elastic Load Balancer - classic load balancer
- 7. Auto Scaling
- 8. Amazon Elastic Block Store(EBS)
- 9. Amazon Simple Storage Service
- 10. Amazon Glacier
- 11. Amazon Relational Database Service (Amazon RDS)
- 12. Amazon DynamoDB
- 13. Redshift
- 14. Amazon Aurora
1. AWS global infrastructure
1.1 Regions
AWS Regions provide multiple, physically separated and isolated Availability Zones which are connected with low latency, high throughput, and highly redundant networking.
1.2 Availability Zones
These Availability Zones offer AWS customers an easier and more effective way to design and operate applications and databases, making them more highly available, fault tolerant, and scalable than traditional single datacenter infrastructures or multi-datacenter infrastructures.
Collection of data centers within a region.
isolate - protect from failures
AZs are pyhsically and logically seperated within a region. Own their own:
- uninterruptible power supply
- cooling equipment
- networking connectivity
- backup generators
1.3 Edge Locations
Content Delivery Network —- Amazon CloudFront
Deliver content to customers
When a user requests content that you’re serving with CloudFront, the user is routed to the edge location that provides the lowest latency (time delay), so that content is delivered with the best possible performance.
1.4 Local Regions
An AWS Local Region is a single datacenter designed to complement an existing AWS Region. Like all AWS Regions, AWS Local Regions are completely isolated from other AWS Regions.
2. Virtual Private Cloud (VPC)
2.1 Introduction
Amazon VPC enables you to launch AWS resources into a virtual network that you’ve defined. This virtual network closely resembles a traditional network that you’d operate in your own data center, with the benefits of using the scalable infrastructure of AWS.Consists of such features:
- A private, virtual network in the AWS Cloud
- Uses same concepts as on premise networking
- Allows complete control of network configuration
- Ability to isolate and expose resources inside VPC
- Offers several layers of security controls
- Ability to allow and deny specific internet and internal traffic
- Other AWS services deploy into VPC
- Services inherent security built into network
2.2 Features
Build upon high availabilty of AWS regions and availability zones
- Amazon VPC lives within a region
- Multiple VPCs per account
Subnets
- Used to divide Amazon VPC
- Allow Amazon VPC to span multiple Azs
- seperate public and private network
Route tables
- Control traffic going out of the subnets
Internet Gateway (IGW)
- Allows private subnet resources to access internet
Network Access Control Lists(NACL)
- Control access to subnets; stateless
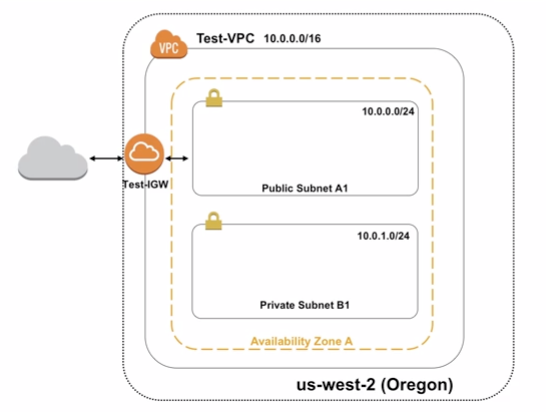
2.3 Subnets
A subnet is a range of IP addresses in your VPC. You can launch AWS resources into a specified subnet. Use a public subnet for resources that must be connected to the internet, and a private subnet for resources that won’t be connected to the internet.
3. AWS Security
3.1 AWS security groups
Filter traffic to your instances
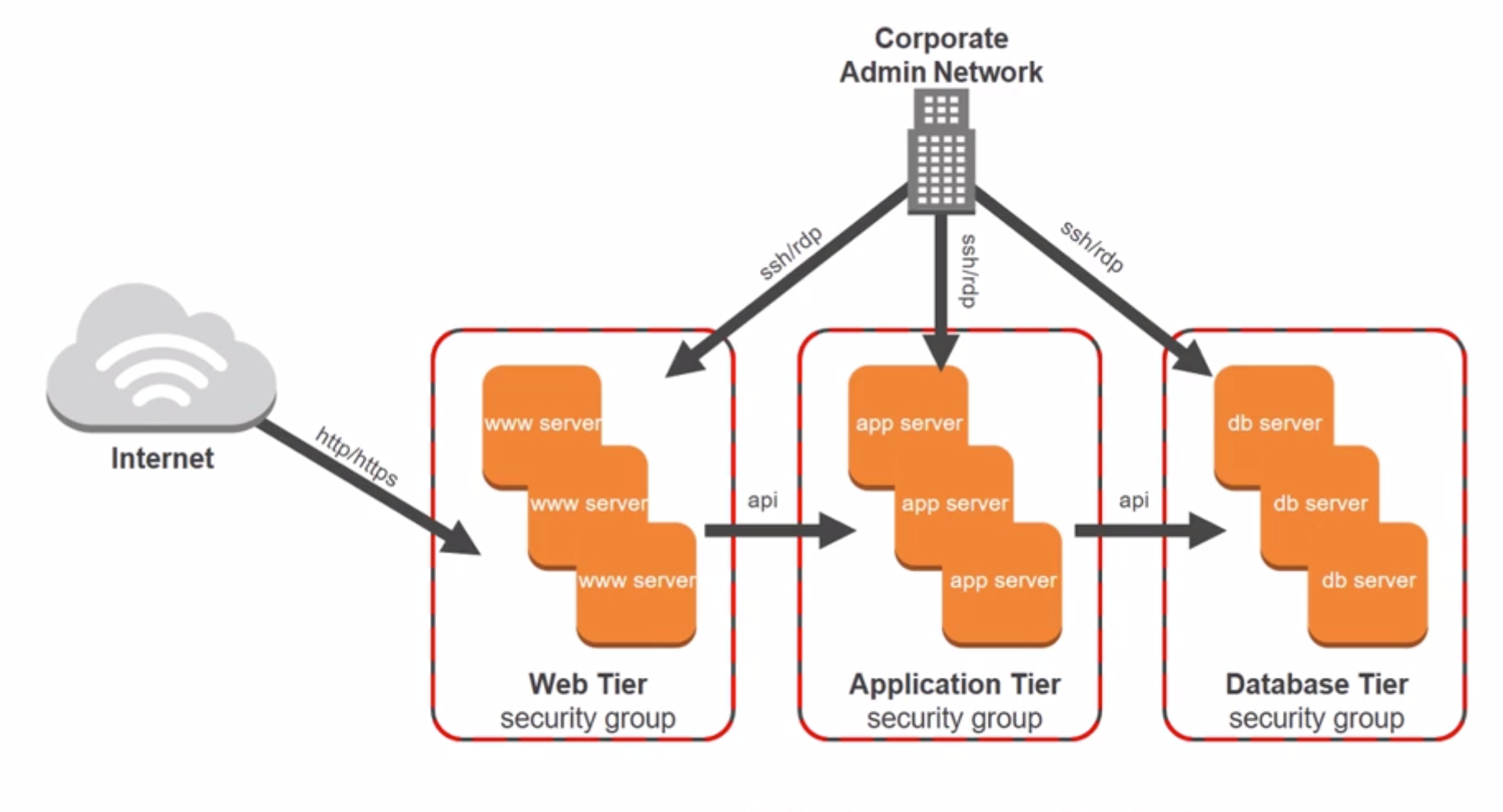
Can configure the security rules, have multi rules. Web tier - application tier - database tier.
A security group acts as a virtual firewall for instances to control inbound and outbound traffic. Security group act at the instance level , not the subnet level. For each security group, you add rules that control the inbound traffic to instances, and a separate set of riles that control the outbound traffic.
4. Compute Services
4.1 Amazon EC2
Flexible configuration and control
maintain complete control of envs
EC2 overview
4.1.1 What is EC2
Compute: different thing you can do with servers
- Application server
- Web server
- Database server
- Game server
- Mail server
- Media server
- Catalog server
- File server
- Computing server
- Proxy server
4.1.2 Amazon EC2 instances instructions
need to select AMI(Amazon Machine Image), present for software choices
Select instance type(hard ware)
Configure network, storage, key pairs (Use key value pair to access the instance)
4.1.3 Features of EC2
- virtual computing env. known as instances
- various comfigurations of CPU, memory, and networking capacity for your instances
- secure login information for your instances using key pairs(AWS stores the public key, and you store the private key)
- Sotrage volumes(temporory) and persistent storage volumes – Amazon Elastic Block Store
- Firewall that enables you to specify the protocols, ports and source IP ranges that can reach your instances using security groups
- static IPv4 addresses for dynamic cloud computing, known as Elastic IP adddresses
- metadata, known as tags, that you can create and assign to your Amazon EC2 resources
- Virtual networks you can create that are logically isolated from the rest of the AWS cloud
4.1.4 Security best practices
- Use AWS identiry and access Management(IAM) to control access to AWS resources, including instances. You can create IAM users and groups under your AWS account, assign security credentials to each, and control the access that each has to resources and services in AWS.
- Restrict access by only allowing trusted hosts or networks to access ports on your instance. For example, you can restrict SSH access by restricting incoming traffic on port 22.
4.1.5 Instance types
Instance type you specify determines the hardware of the host computer used for your instance. Each instance is provided with a consistent and predictable amount of CPU capacity, memory, storage.
- general purpose
- compute optimized
- memory optimized
- storage optimized
- accelerated computing
4.2 Lambda
4.2.1 Overviews
AWS Lambda is a compute service that lets you run code without provisioning or managing servers. Pay for the compute time you consume. AWS Lambda runs your code on a high-availability compute infrastructure and performs all of the administration of the compute resources, including server and operating system maintenance, capacity provisioning and automatic scaling, code monitoring and logging.
fully managed serverless compute
event driven execution, respond to event
sub second metering
4.2.2 benefits :
- Lambda manages the compute fleet that offers a balance of memory, CPU, network and other resources.
4.2.3 Use cases
- Run code in response to events, such as changes to data in an Amazon S3 bucket or an DynamoDB table
- Run code in response to HTTP requests using Amazon API gateway
- Invoke code using API calls made using AWS SDKs
- Build serverless applications composed of functions that are triggered by events and automatically deploy them using AWS CodePipeline and AWS CodeBuild.
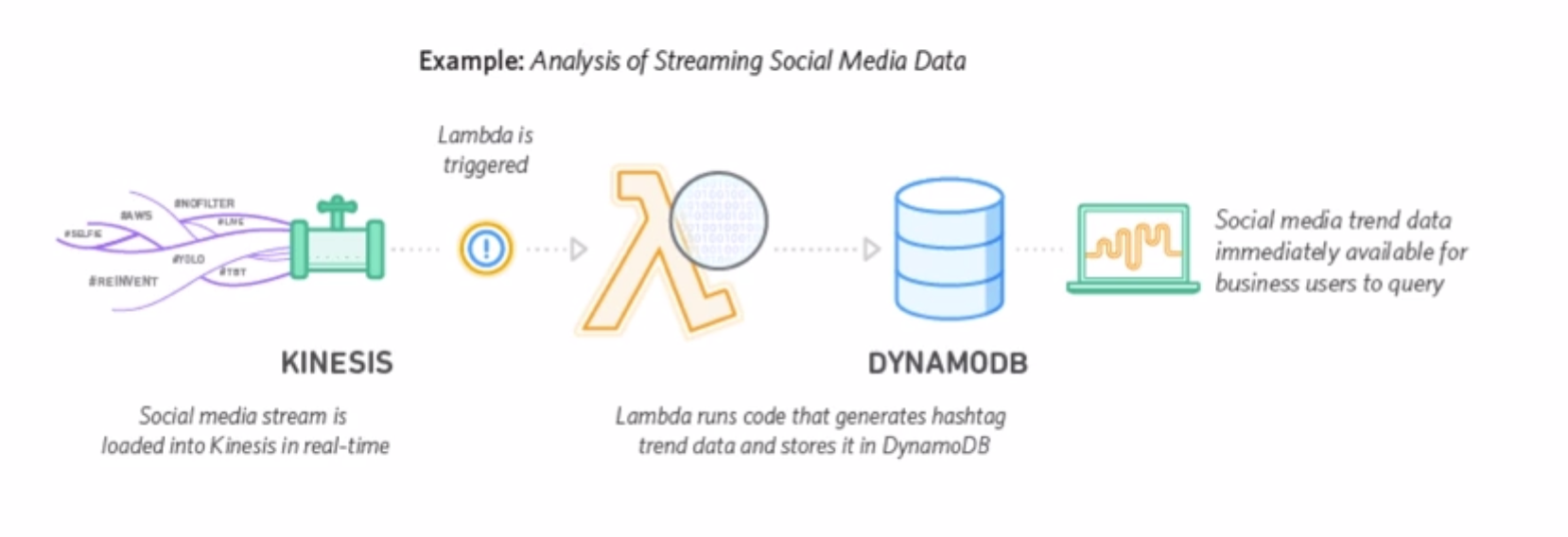
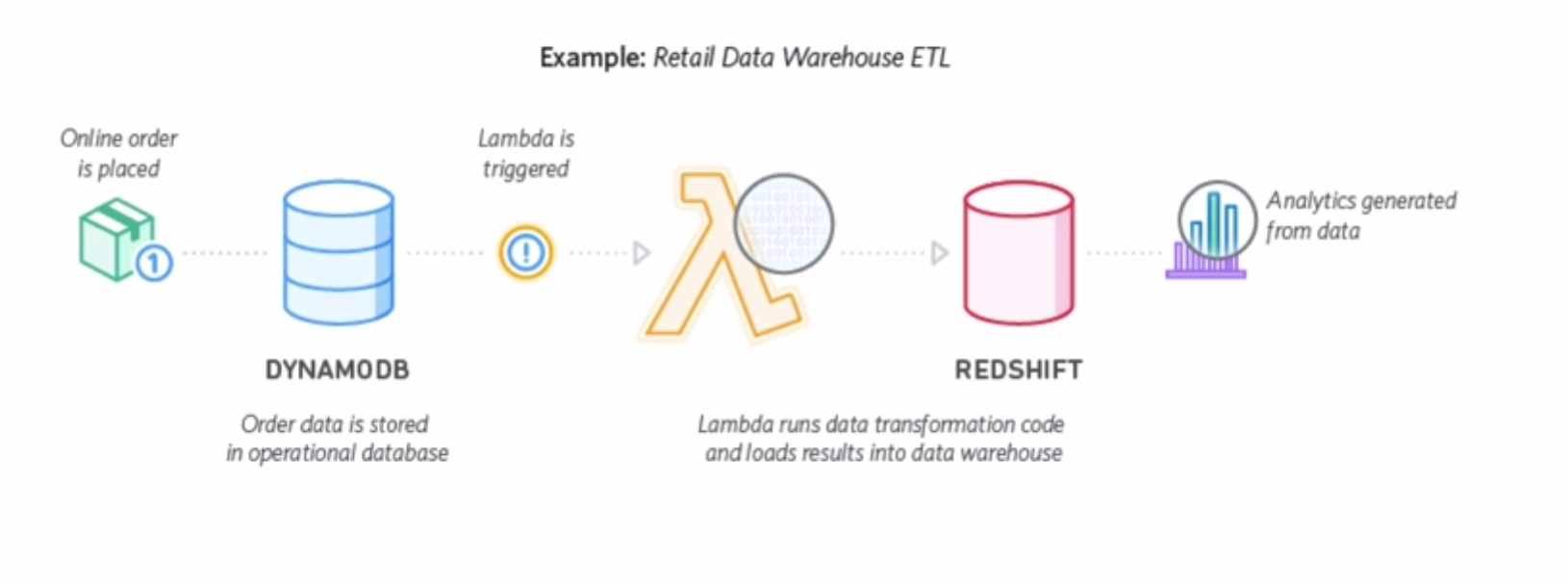
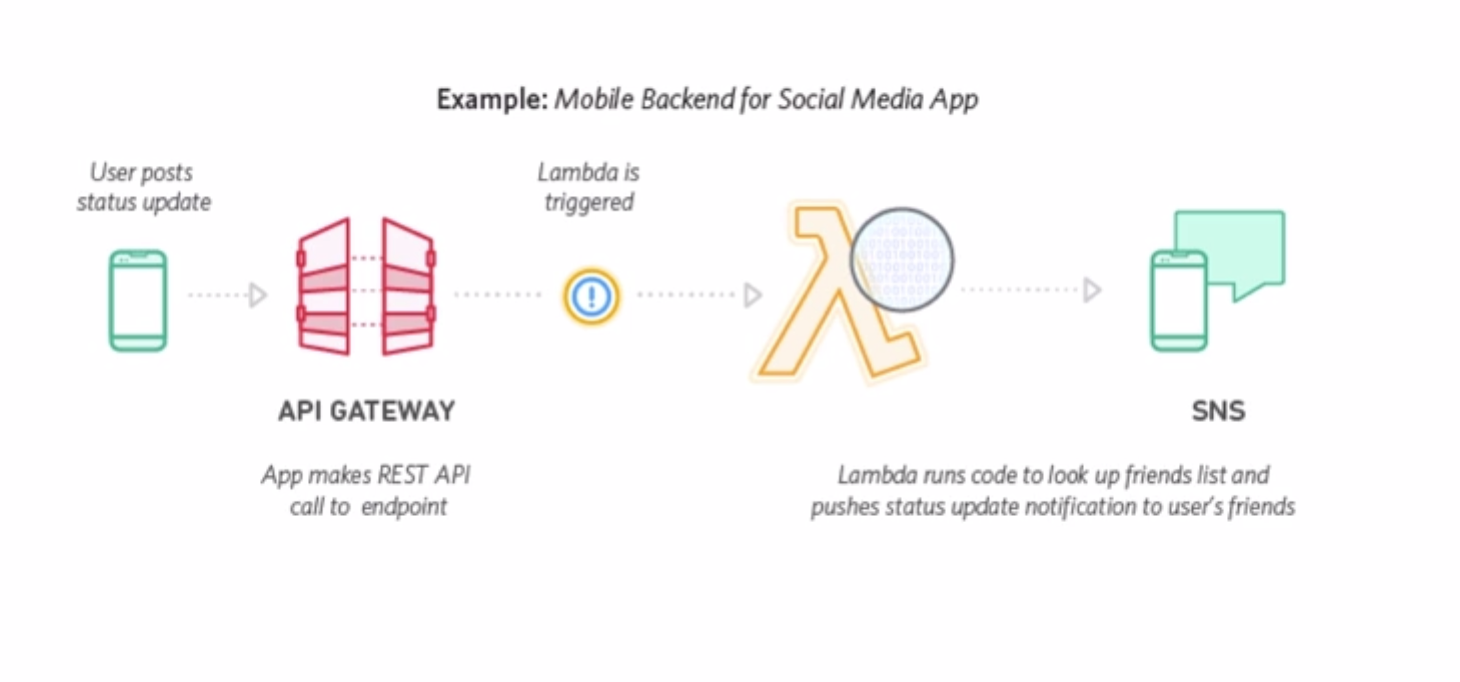
4.2.4 Lambda Applications
An AWS Lambda application is a combination of Lambda functions, event sources, and other resources that work together to perform tasks. You can use AWS CloudFormation and other tools to collect your application’s components into a single package that can be deployed and managed as one resource.
4.2.5 Work with AWS Lambda Functions
- Concurrent Executions limit: 1000
- function timeout: 15 minutes
- execution threads: 1024
- [Building Lambda Functions]
- Lifecycle for an AWS lambda-based application
- authoring code
- programing model - the format of the code
- deploying code
- Package code and dependencies in a deployment package
- upload the package to AWS Lambda to create Lambda function
- monitoring
- CloudWatch
- troubleshooting
- authoring code
4.2.6 Lambda Concepts
- Function - A script or program that runs in AWS Lambda. Lambda passes invocation events to your function. The function processes an event and returns a response.
- Runtimes – Lambda runtimes allow functions in different languages to run in the same base execution environment. You configure your function to use a runtime that matches your programming language. The runtime sits in-between the Lambda service and your function code, relaying invocation events, context information, and responses between the two. You can use runtimes provided by Lambda, or build your own.
- Layers – Lambda layers are a distribution mechanism for libraries, custom runtimes, and other function dependencies. Layers let you manage your in-development function code independently from the unchanging code and resources that it uses. You can configure your function to use layers that you create, layers provided by AWS, or layers from other AWS customers.
A layer is a ZIP archive that contains libraries, a custom runtime or other dependencies. With layers, you can use libraries in your function without needing to include them in your deployment package. Layers let you keep your deployment package small, which makes development easier.
- Event source – An AWS service, such as Amazon SNS, or a custom service, that triggers your function and executes its logic.
- Downstream resources – An AWS service, such as DynamoDB tables or Amazon S3 buckets, that your Lambda function calls once it is triggered.
- Log streams – While Lambda automatically monitors your function invocations and reports metrics to CloudWatch, you can annotate your function code with custom logging statements that allow you to analyze the execution flow and performance of your Lambda function to ensure it’s working properly.
- AWS SAM – A model to define serverless applications. AWS SAM is natively supported by AWS CloudFormation and defines simplified syntax for expressing serverless resources.
4.3 AWS Elastic Beanstalk
4.3.1 Overview
Quick get application into the cloud
Platform as a service
You can simply upload your code and Elastic Beanstalk automatically handles the deployment, from capacity provisioning, load balancing, auto-scaling to application health monitoring. At the same time, you retain full control over the AWS resources powering your application and can access the underlying resources at any time.
Allow quick deployment of your applications
Elastic Beanstalk provides:
- Application service
- HTTP service
- Operating system
- Language interpreter
- Host
5 Application Load Balancer
5.1 Service Introduction
A load balancerr serves as the single point of contact for clients. The load balancer distributes incoming application traffic across multiple targets, such as EC2 instances in multiple Availability Zones.
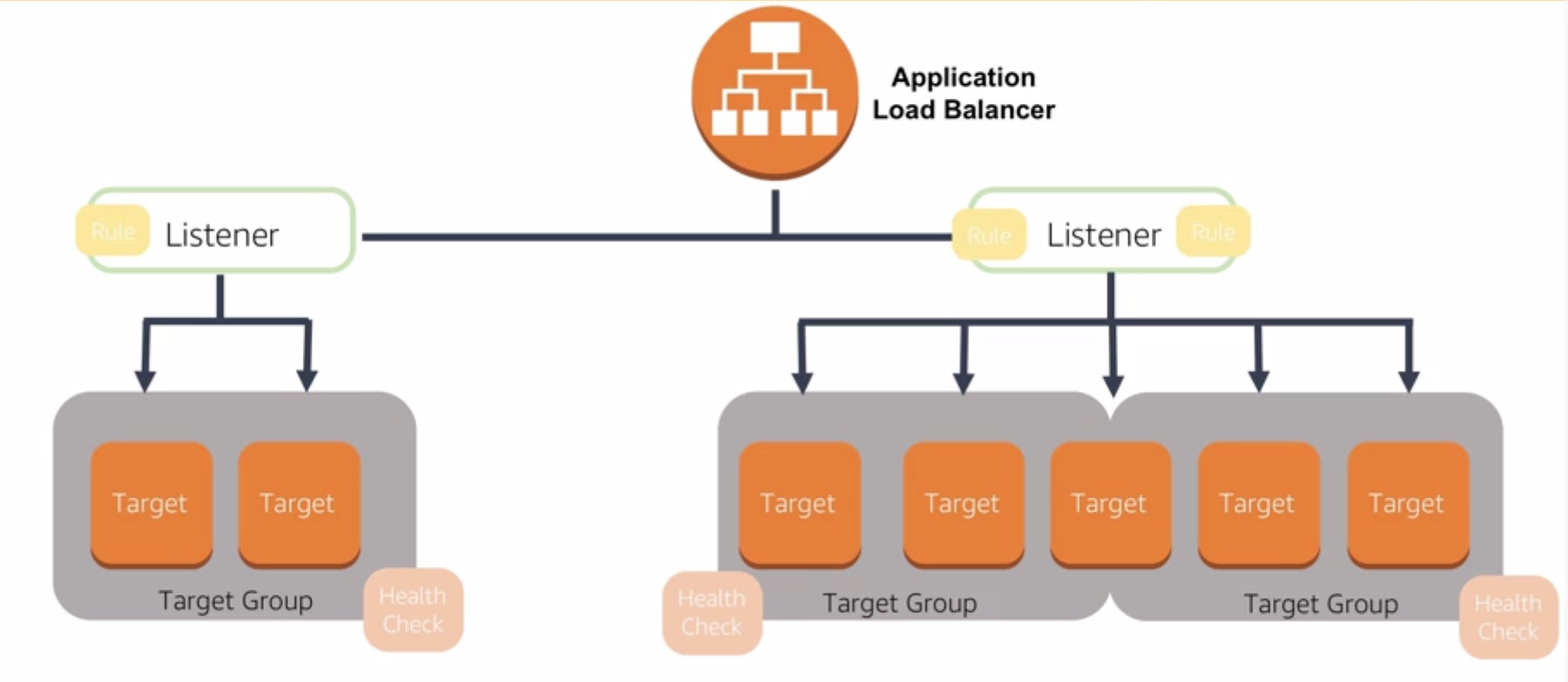
A listener checks for connection requests from clients, using the protocol and port that you configure, and forwards requests to one or more target groups, based on the rules that you define. Each rule specifies a target group, condition, and priority. When the condition is met, the traffic is forwarded to the target group. You must define a default rule for each listener, and you can add rules that specify different target groups based on the content of the request
Each target group routes requests to one or more registered targets, such as EC2 instances, using the protocol and port number that you specify. You can register a target with multiple target groups. You can configure health checks on a per target group basis. Health checks are performed on all targets registered to a target group that is specified in a listener rule for your load balancer.
An Application Load Balancer functions at the application layer, the seventh layer of the Open Systems Interconnection (OSI) model. After the load balancer receives a request, it evaluates the listener rules in priority order to determine which rule to apply, and then selects a target from the target group for the rule action. You can configure listener rules to route requests to different target groups based on the content of the application traffic. Routing is performed independently for each target group, even when a target is registered with multiple target groups.
Part of the elastic load balancer service. Add some important features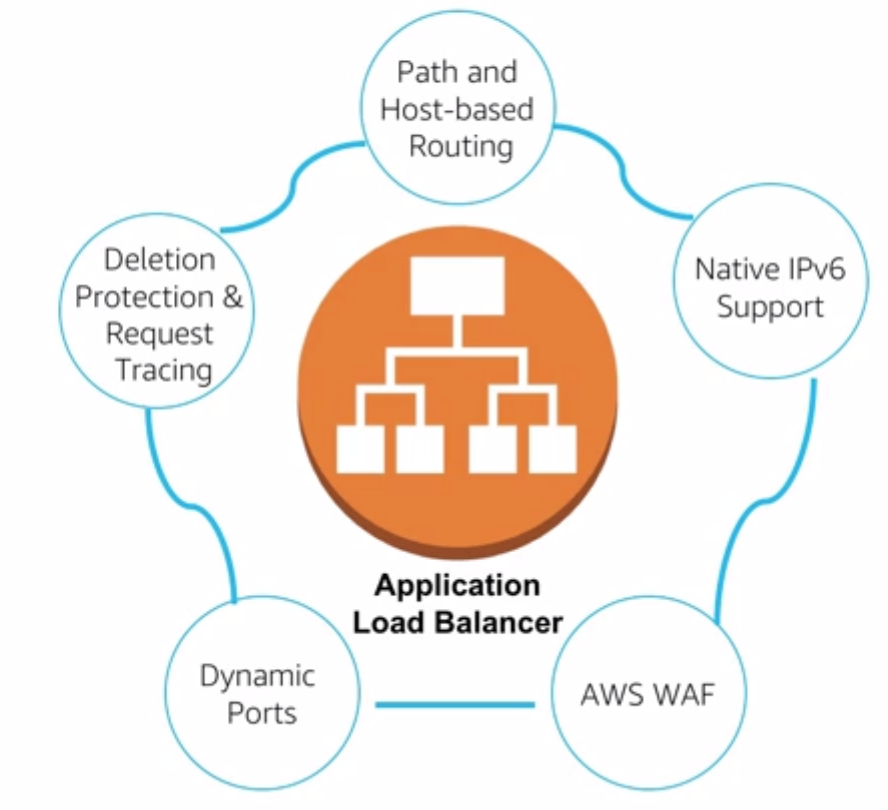
- Support more protocols HTTP HTTPS HTTP/2
- cloudWatch Metrics
- Access logs
- Health Checks
5.2 Key Concepts
- Listeners: a process that cehcks for connection requests, using the protocol and port that you configure. Rules that you define for a listener determine how the load balancer routes requests to the targets in one or more target groups.
- Target: A target is a destination for traffic based on the established listener rules
- Target group: each target group routes requests to one or more registered targets using the protocol and port number specified.
5.3 Benefits of using Application load balancer instead of classic load balancer
- Support for path-based routing. You can configure rules for your listener that forward requests based on the URL in the request. This enables you to structure your application as smaller services, and route requests to the correct service based on the content of the URL.
- Support for host-based routing. You can configure rules for your listener that forward requests based on the host field in the HTTP header. This enables you to route requests to multiple domains using a single load balancer.
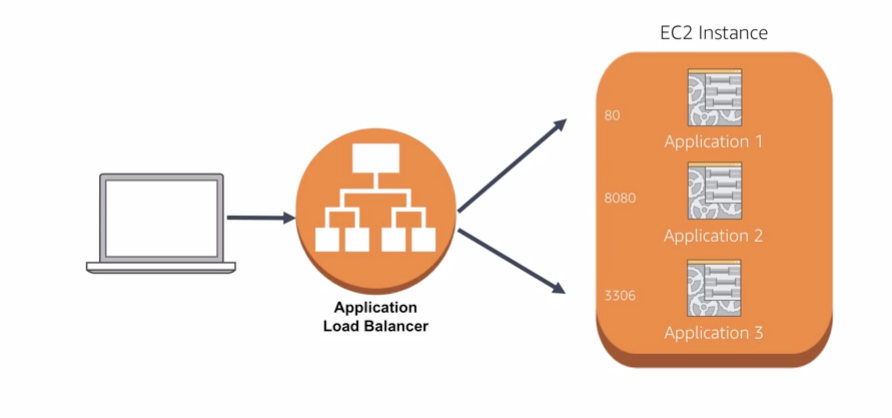
- Support for routing requests to multiple applications on a single EC2 instance. You can register each instance or IP address with the same target group using multiple ports.
- Support for redirecting requests from one URL to another
5.4 Use Cases
- route request to different ports within a single instance.
6. Elastic Load Balancer - classic load balancer
6.1 Overview
A load balancer distributes workloads across multiple compute resources, such as virtual servers. Using a load balancer increases the availability and fault tolerance of your applications.
You can add and remove compute resources from your load balancer as your needs change, without disrupting the overall flow of requests to your applications.
You can configure health checks, which are used to monitor the health of the compute resources so that the load balancer can send requests only to the healthy ones. You can also offload the work of encryption and decryption to your load balancer so that your compute resources can focus on their main work.
Mainly consists of there types of load balancer:
- Application Load Balancer
- Network Load Balancer
- Classic Load Balancer
The comparison among those three
6.2 How does it work?
A load balancer accepts incoming traffic from clients and routes requests to its registered targets. It also monitors the health of its registered targets and ensures that it routes traffic tonly to healthy targets. You configure your load balancer to accept incoming traffic by specifying one or more listeners. A listener is a process that checks for connection requests. It is configured with a protocol and port number for connections from clients to the load balancer and a protocol and port number for connections from the load balancer to the targets.
6.2.1 Cross zone load balancing
The nodes for your load balancer distribute requests from clients to registered targets. When cross-zone load balancing is enabled, each load balancer node distributes traffic across the registered targets in all enabled Availability Zones. When cross-zone load balancing is disabled, each load balancer node distributes traffic across the registered targets in its Availability Zone only.
6.2.2 Request Routing
Before a client sends a request to your load balancer, it resolves the load balancer’s domain name using a Domain Name System (DNS) server. The DNS entry is controlled by Amazon, because your load balancers are in the amazonaws.com domain. The Amazon DNS servers return one or more IP addresses to the client, which are the IP addresses of the load balancer nodes for your load balancer. With Network Load Balancers, Elastic Load Balancing creates a network interface for each Availability Zone you enable. Each load balancer node in the Availability Zone uses this network interface to get a static IP address. You can optionally associate one Elastic IP address with each network interface when you create the load balancer.
As traffic to your application changes over time, Elastic Load Balancing scales your load balancer and updates the DNS entry. Note that the DNS entry also specifies the time-to-live (TTL) as 60 seconds, which ensures that the IP addresses can be remapped quickly in response to changing traffic.
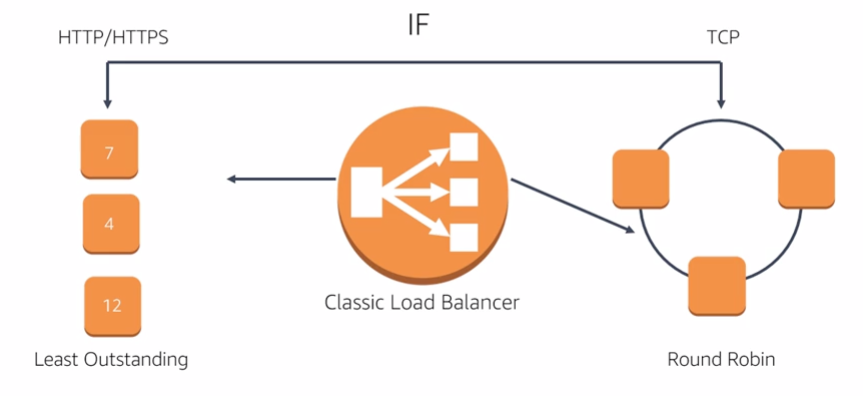
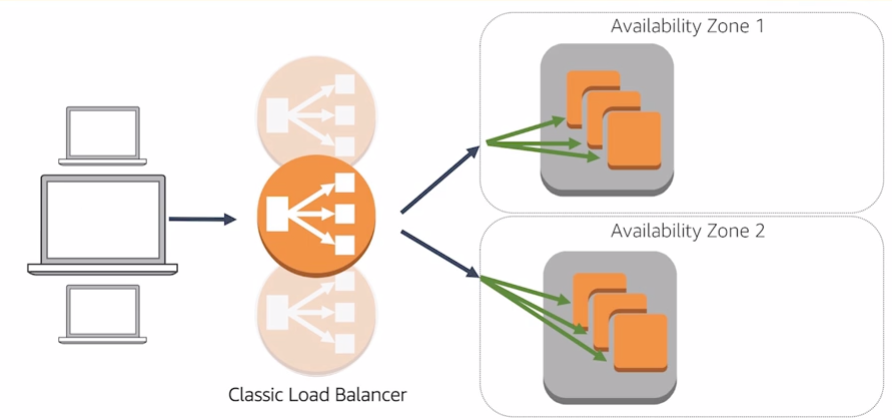
Internet facing load balancers: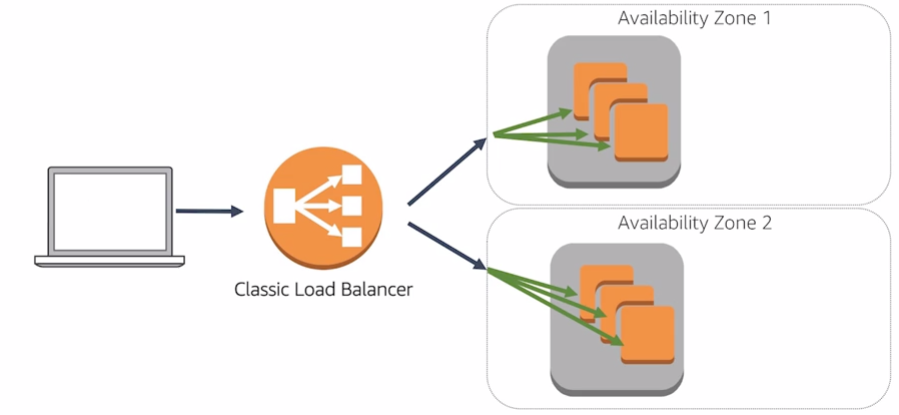
Internal Load Balancers: have DNS name only resolve private nodes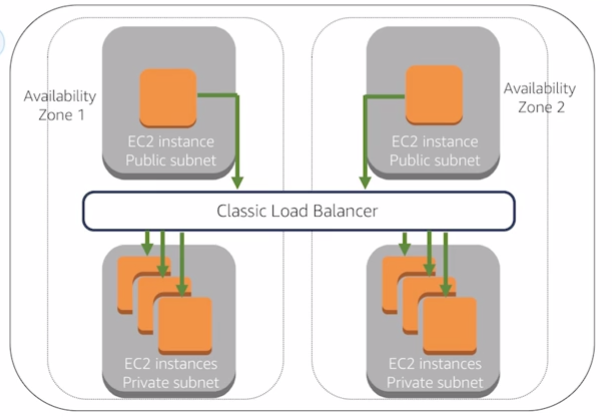
6.2.3 HTTP Connections
Classic Load Balancers use pre-open connections but Application Load Balancers do not. Both Classic Load Balancers and Application Load Balancers use connection multiplexing. This means that requests from multiple clients on multiple front-end connections can be routed to a given target through a single back-end connection. Connection multiplexing improves latency and reduces the load on your applications. To prevent connection multiplexing, disable HTTP keep-alives by setting the Connection: close header in your HTTP responses.
6.3 Use cases
- Access through single point
- Decouple appliation environment
- Provide high availability and fault tolerance
- Increase elasticity and scalability
7. Auto Scaling
7.1 Service Introduction
Auto scaling helps you ensure you have the correct number of EC2 instances available to handle the load for your application.
Using cloudWatch to monitor
7.1.1 Scaling out and scaling in
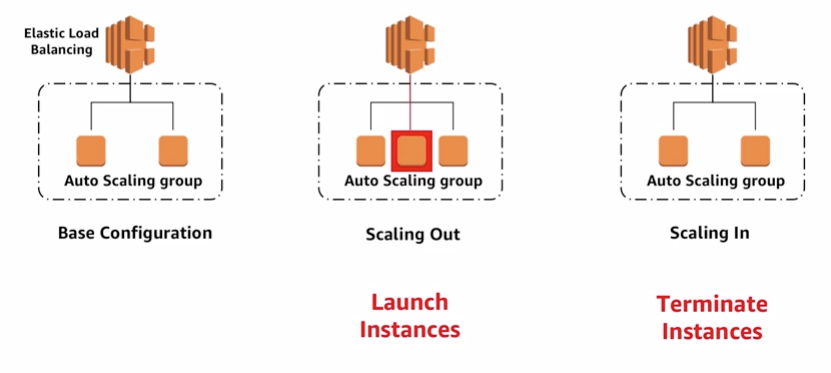
- Auto scaling components
- launch configuration
- auto scaling group
- VPC and subnets
- load balancer
- minimum instances
- maximum instances
- desired capacity
- auto scaling policy
- scheduled
- on demand
- scale out policy
- scale in policy
7.1.2 Dynamic auto scaling
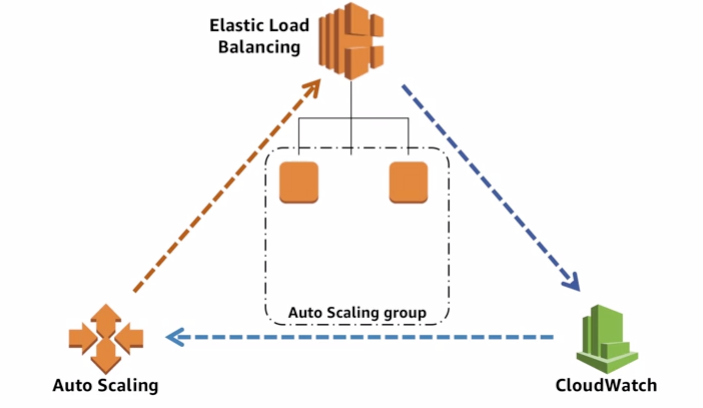
CloudWatch detect the metrics and trigger auto scaling events.
8. Amazon Elastic Block Store(EBS)
Amazon Elastic Block Store (Amazon EBS) provides block level storage volumes for use with EC2 instances. EBS volumes are highly available and reliable storage volumes that can be attached to any running instance that is in the same Availability Zone.
Amazon EBS is recommended when data must be quickly accessible and requires long-term persistence. EBS volumes are particularly well-suited for use as the primary storage for file systems, databases, or for any applications that require fine granular updates and access to raw, unformatted, block-level storage.
you can launch your EBS volumes as encrypted volumes.
There are three types of volumes in Amazon EBS. To understand the difference, you need to know what IOPS is. “IOPS” stands for input/output operations per second or, put it simply, the maximum amount of read/write operations you are able to perform per second. To choose the right Amazon EBS volume type you need to know IOPS requirements for your application.
8.1 General Purpose Volumes
Designed for a broad range of tasks, General Purpose Volumes are backed with Solid State Drive (SSD). The baseline performance of 3 IOPS/GB and a possibility to burst up to 10,000 IOPS makes them a good fit for AWS databases that need a lot of read and write operations, like PostgreSQL, MS SQL or Oracle databases.
8.2 Provisioned IOPS (SSD) Volumes
By expanding the bandwidth bottleneck, Provisioned IOPS Volumes allow buying read/write operations on demand regardless of the volume capacity. This type of EBS volumes is backed with the same SSD but designed for heavy workloads from 30 IOPS/GB up to 20,000 IOPS. Multiple Provisioned IOPS volumes can be striped thus ensuring up to 48,000 IOPS or 800 MBps of throughput.
8.3 Magnetic Volumes
The best way to think of the Magnetic Volumes type is as of a low-cost volume that can be used with testing and development environments on Amazon EC2. It can also be used with applications that don’t require a lot of read/write operations. Instead of SSD, this type is based on magnetic HDD drives, thus the IOPS baseline is within the range of 100 up to hundreds of IOPS. Magnetic Volumes can also become a starting point in working with Amazon EC2 — once you understand your IOPS demands, you can select the type of volume that fits best.
9. Amazon Simple Storage Service
9.1 Introduction
No need to manage any infrastructure yourself. S3 help you manage your storage, it can store unlimited number of objects, access any time, from anywhere; rich security controls.
Amazon Simple Storage Service (Amazon S3) is storage for the Internet. You can use Amazon S3 to store and retrieve any amount of data at any time, from anywhere on the web. You can accomplish these tasks using the AWS Management Console, which is a simple and intuitive web interface.
9.1.1 steps
- create a bucket
- add an object to a bucket
- view an object
- move an object
- delete an object and bucket
9.1.2 bucket
S3 stores data as objects within buckets. An object consists of a file and optionally any metadata that describes the file.
To store an object in Amazon S3, you upload the file you want to store to a bucket. When you upload a file, you can set permissions on the object as well as any metadata.
Buckets are the containers for objects. You can have one or more buckets. For each bucket, you can control access to it (who can create, delete, and list objects in the bucket), view access logs for it and its objects, and choose the geographical region where Amazon S3 will store the bucket and its contents.
Need a bucket to hold the data
associate in region, will make duplicate
disigned for seamless scaling
9.2 Use cases
- store application assets
- static web hosting
- backup and disaster recovery
- staging area for big data
10. Amazon Glacier
10.1 Overview
Data archiving solition
long tern storage at low cost
access limited by vault polocies
for data not accessed frequently
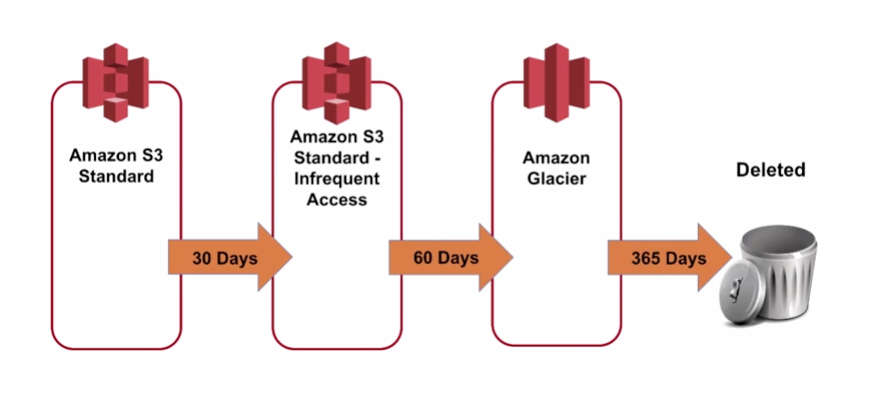
It can take a really long time to retrieve data from glacier. bulk, standard, expedited.
Amazon Simple Storage Service Glacier (Amazon S3 Glacier) is a storage service optimized for infrequently used data, or “cold data.” The service provides durable and extremely low-cost storage with security features for data archiving and backup. With Amazon S3 Glacier, you can store your data cost effectively for months, years, or even decades. Amazon S3 Glacier enables you to offload the administrative burdens of operating and scaling storage to AWS, so you don’t have to worry about capacity planning, hardware provisioning, data replication, hardware failure detection and recovery, or time-consuming hardware migrations.
10.2 Details
10.2.1 archive
An archive can be any data such as a photo, video, or document and is a base unit of storage in glacier.
10.2.2 vault
Container to store archive. When creating a vault, you specify a name and choose an AWS region where you want to create the vault. Within a Region, an account must use unique vault names. An AWS account can create same-named vaults in different Regions.
10.2.3 access policy
who can access
10.2.4 Job
Glacier jobs can perform a select query on an archive, retrieve an archive, or get an inventory of a vault. When performing a query on an archive, you initiate a job providing a SQL query and list of Glacier archive objects. Glacier Select runs the query in place and writes the output results to Amazon S3.
10.3 use cases
- archive database snapshots and log files
- low cost enables more comprehensive backups
- archive older documents, audio, video
11. Amazon Relational Database Service (Amazon RDS)
11.1 Overview
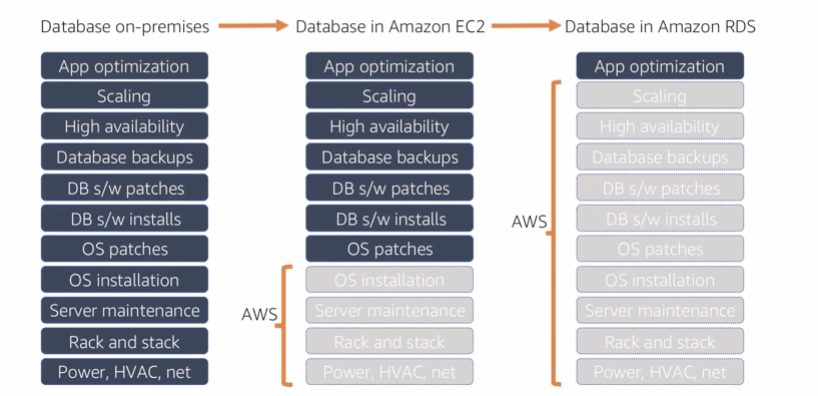
11.1.1 Chanllenges of relational databases
- server maintenance and energy footprint
- software install and patches
- database backups and high availability
- limits on scalability
- data security
- os install and patches
11.1.2 RDS intro
Amazon RDS is a managed service that sets up and operates a relational database in the cloud.
AWS help you manage:
- OS installation and patches
- database software install and patches
- database backups
- high availability
- scaling
- power and rack & stack
- server maintenance
It support mainstream relation databases:
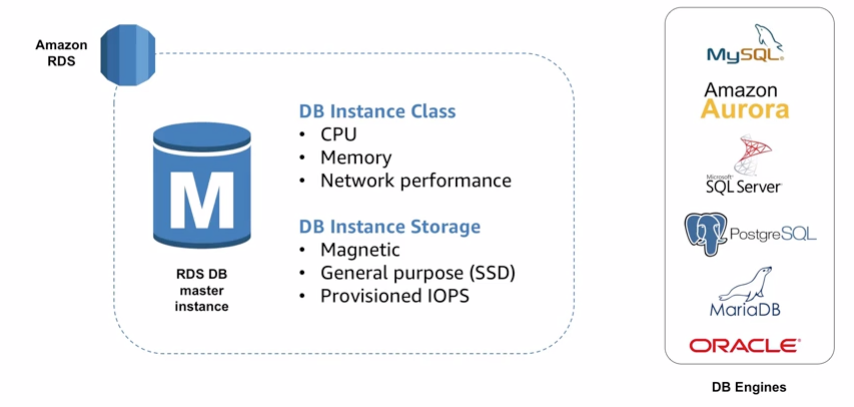
11.2 Use cases
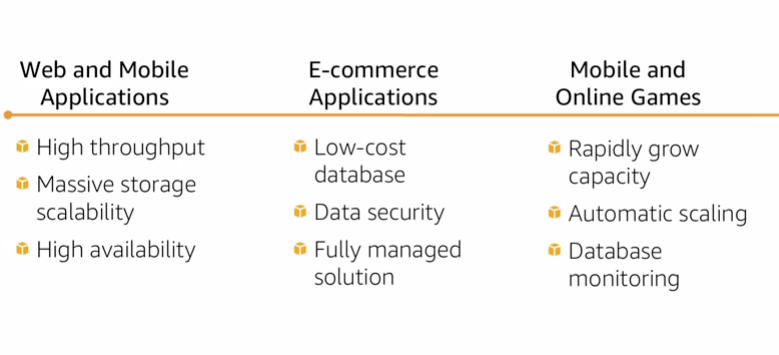
12. Amazon DynamoDB
12.1 Overview
12.1.1 Features
- NoSQL databse tables as a service
- store as many items as you want
- items may have differing attributes
- low latency queries
- scalable read/ write throughput
12.1.2 Partitioning
as table grows, table partitioned by key
query by key to find items efficiently
scan to find items by any attribute, less efficient
12.2 Use cases
- web
- mobile apps
- internet of things
- ad tech
13. Redshift
13.1 Redshift introduction
- data warehouse, to analyze the data with query.
- parallel processing architecture
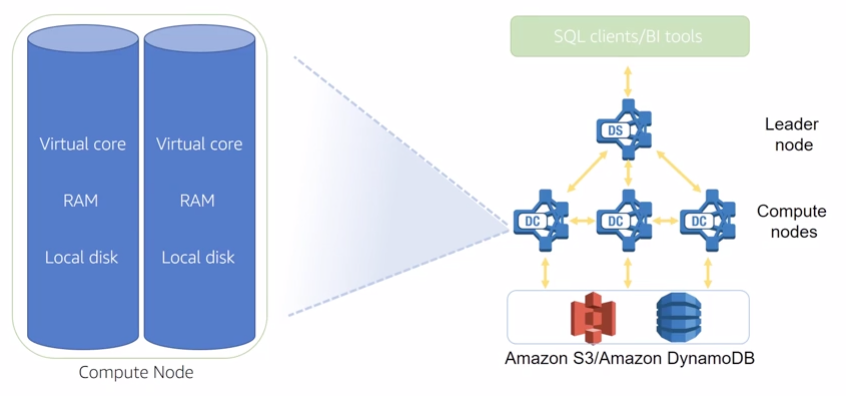
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse service that makes it simple and cost-effective to efficiently analyze all your data using your existing business intelligence tools. It is optimized for datasets ranging from a few hundred gigabytes to a petabyte or more and costs less than $1,000 per terabyte per year, a tenth the cost of most traditional data warehousing solutions.
13.2 Overview
13.2.1 Cluster management
A cluster is a set of nodes, which consists of a leader node and one or more compute nodes, The type and number of compute nodes that you need depends on the size of your data, the number of queries you will execute, and the query execution performance that you need.
13.3 use cases
Enterprise Data Warehouse (EDW)
Big Data
Saas
- scale the data warehouse capacity as demand grows
- add analytic functionality to applications
- reduce hardware and software costs by an order of magnitude
14. Amazon Aurora
14.1 Overview
mysql relational database
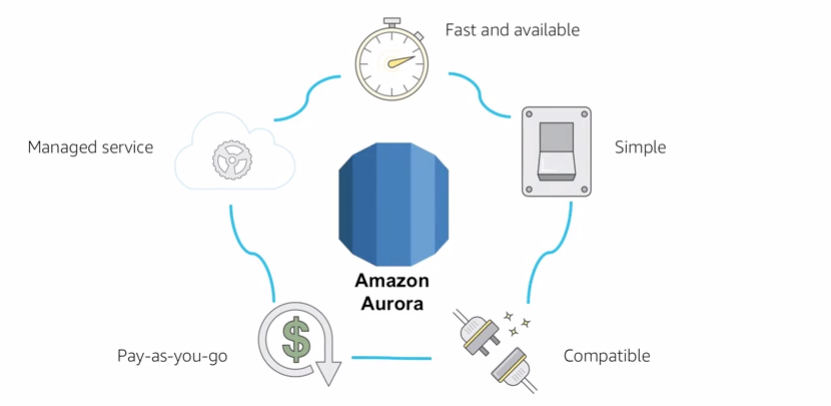
It is designed to deliver the speed and reliability of high-end commercial databases in a simple and cost-effective manner. Aurora is designed to be compatible with MySQL 5.6 and delivers five times the throughput of standard MySQL running on the same hardware. DBAs are able to save time on planning backup storage disks, as data is continuously backed up to AWS S3 in real time, with no performance impact to the end user.
14.2 benefits
15. Trused Advisor
Used to keep track of aws resources. – a dashboard for all the risks and warnings that you can take actions to save money
Detect your usage in four categories:
- cost optimization
- performance
- security
- fault tolerance
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:AWS essentials(3) - Core Services
文章字数:4.1k
本文作者:Leilei Chen
发布时间:2020-01-30, 12:48:08
最后更新:2020-02-02, 14:06:57
原始链接:https://www.llchen60.com/AWS-essentials-3-Core-Services/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

