B+树
B+树
1. 什么时候会用到?
1.1 数据库索引
工作中为了加快数据库中数据的查找速度,我们常用的处理思路是对表中数据创建索引,而数据库的索引底层就使用了B+树的结构
对于数据库,我们希望通过索引实现查询数据的效率的提升;同时不要消耗太多的内存空间。而数据库索引查找的过程当中,其特点是:
- 需要进行直接查找
- 需要支持按照一定区间的快速查找
1.2 Overview
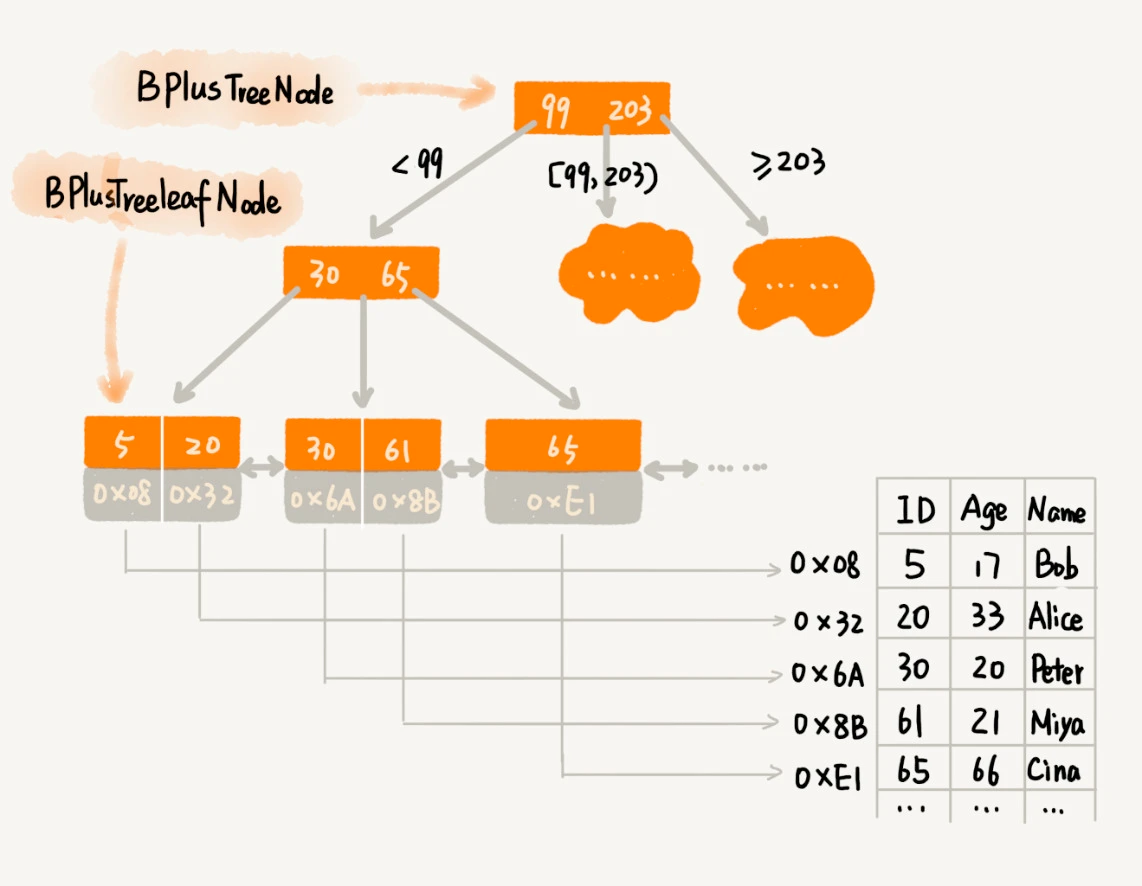
- B + 树特征
- 每个节点中子节点的个数不能超过 m,也不能小于 m/2;
- 根节点的子节点个数可以不超过 m/2,这是一个例外;
- m 叉树只存储索引,并不真正存储数据,这个有点儿类似跳表;
- 通过链表将叶子节点串联在一起,这样可以方便按区间查找;
- 一般情况下,根节点会被存储在内存中,其他节点存储在磁盘中
- B树
- 节点中存储数据
- 叶子节点并没有使用链表来串联
- 是一个每个节点的子节点个数不少于m/2的m叉树
2. 为什么在数据库索引的时候会使用到B+树呢?
2.1 使用二叉查找树来实现索引?
- 从二叉查找树开始说起 我们可以改一下
- 树中的节点不存储数据本身,只作为索引
- 每个叶子节点串在一条链表上
- 链表当中的数据从小到大有序
- 对于区间查找的支持程度
- 先在树中遍历,然后到叶子节点以后再顺着链表来往后遍历
- 直到链表当中的结点数据值大于区间的终止值为止
- 问题
- 占用的内存空间非常大
- 解决方案
- 放到硬盘上,但是访问速度会变慢很多了
- 内存访问速度在纳秒级别
- 硬盘访问速度在毫秒级别
- 解决方案的问题在于
- 磁盘IO操作的次数等于树的高度
- 我们需要尽可能的减少树的高度来减少磁盘IO的次数
- 解决方案
- 占用的内存空间非常大
2.2 使用m叉树来实现
- 使用m叉树的好处
- 减少了访问磁盘的IO次数
/**
* 这是B+树非叶子节点的定义。
*
* 假设keywords=[3, 5, 8, 10]
* 4个键值将数据分为5个区间:(-INF,3), [3,5), [5,8), [8,10), [10,INF)
* 5个区间分别对应:children[0]...children[4]
*
* m值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
* PAGE_SIZE = (m-1)*4[keywordss大小]+m*8[children大小]
*/
public class BPlusTreeNode {
public static int m = 5; // 5叉树
public int[] keywords = new int[m-1]; // 键值,用来划分数据区间
public BPlusTreeNode[] children = new BPlusTreeNode[m];//保存子节点指针
}
/**
* 这是B+树中叶子节点的定义。
*
* B+树中的叶子节点跟内部节点是不一样的,
* 叶子节点存储的是值,而非区间。
* 这个定义里,每个叶子节点存储3个数据行的键值及地址信息。
*
* k值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
* PAGE_SIZE = k*4[keyw..大小]+k*8[dataAd..大小]+8[prev大小]+8[next大小]
*/
public class BPlusTreeLeafNode {
public static int k = 3;
public int[] keywords = new int[k]; // 数据的键值
public long[] dataAddress = new long[k]; // 数据地址
public BPlusTreeLeafNode prev; // 这个结点在链表中的前驱结点
public BPlusTreeLeafNode next; // 这个结点在链表中的后继结点
}- m值的设定
- 操作系统是按页来读取数据的,一页通常大小为4KB
- 一次会读取一页的数据
- 如果要读取的数据量超过一页的大小,就会触发多次IO操作了
- 因此我们选定m大小的时候尽量让每个节点的大小等于一个页的大小
- 这样的话读取一个节点只需要一次磁盘IO操作即可
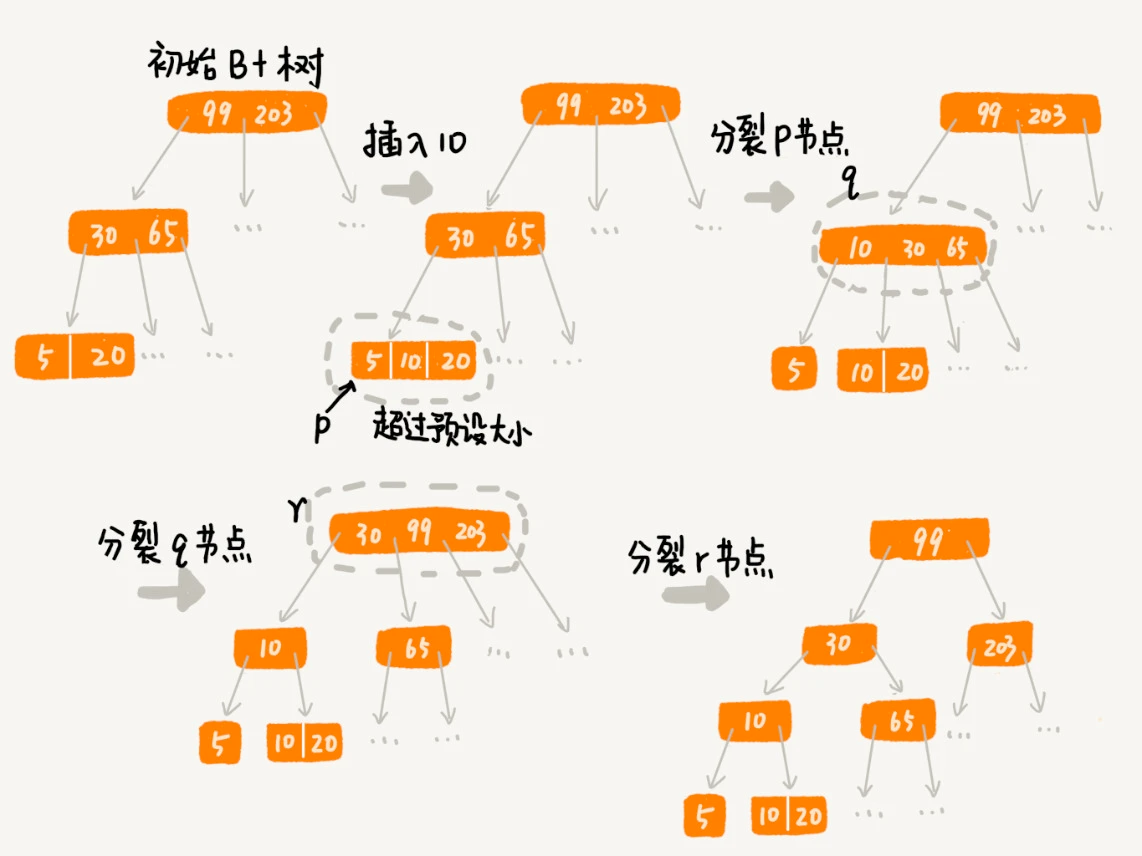
2.3 索引的问题 - 导致写入效率下降
- 数据写入过程,会涉及到索引的更新,这是导致索引写入变慢的主要原因
- 场景描述
- m值是提前计算好的
- 向数据库写入过程当中,有可能会使得索引当中某些节点的子节点的个数超过m
- 这个节点的大小超过一个页的大小,那么读取这样一个节点的时候,就会导致多次磁盘IO操作,这是我们极力避免的
- 解决方案
- 将这个节点分裂成两个节点
- 这个问题会向上传导,即上层父节点的子节点个数有可能超过m个了
- 因此我们就需要向上递归来重构这棵B+树了
- 正是因为我们需要保证B+树索引是一个m叉树,所以索引的存在会导致数据库写入速度降低
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:B+树
文章字数:1.3k
本文作者:Leilei Chen
发布时间:2021-07-11, 12:25:25
最后更新:2021-07-11, 12:27:41
原始链接:https://www.llchen60.com/B-%E6%A0%91/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

