Redis持久化机制-RDB
1. AOF数据恢复存在的问题
- AOF方法每次执行记录的是操作命令,需要持久化的数据量不大
- 但是也因为记录的是操作命令,而不是实际数据,所以用AOF方法进行故障恢复的时候,需要逐一把操作日志都执行一遍
- 如果操作日志很多,Redis的恢复就会很缓慢,可能影响到正常
2. 内存快照Overview
- 内存快照可以解决上述的问题
- 内存快照指的是记录下内存中的数据在某一时刻的状态
- 将某一时刻的状态以文件的形式写到磁盘上 这样即使宕机,快照文件也不会丢失,数据的可靠性也就有了保证
- 快照文件称为RDB文件,RDB — Redis DataBase
- RDB特征
- 记录的是某一个时刻的数据,并不是操作
- 因此在数据恢复的时候,我们可以将RDB文件直接读入内存,很快完成恢复
- 什么时候会实现RDE的载入?
- 只要Redis服务器在启动的时候检测到RDB文件存在,就会自动载入RDB文件
- 如果服务器开启了AOF持久化功能,因为AOF文件更新频率一般比RDB高很多,所以服务器会优先使用AOF文件来还原数据库状态、
- 只有当AOF功能处于关闭状态的时候,服务器才会使用RDB文件来还原数据库状态
- 如何工作的
- 我们可以设置一系列规则,被保存在saveparams里面
- seconds
- changes
- —> 当在xx秒里 有超过xxx更新数量的时候会触发RDB
- dirty计数器
- 记录在上次成功执行了SAVE或者BGSAVE命令之后,服务器对数据库状态进行了多少次修改
- lastsave属性
- UNIX时间戳,记录了上次成功执行的时间
- Redis的serverCron函数默认每隔100ms执行一次,来维护服务器
- 其中一项工作就是检查save选项设置的保存条件是否满足
- 如果满足就执行BGSAVE命令
- 我们可以设置一系列规则,被保存在saveparams里面
2.1 给哪些数据做快照?
- Redis的数据都在内存当中,为了提供所有数据的可靠性保证,其执行的是全量快照
- 即将内存中的所有数据都记录到磁盘当中
- 与之一起来的问题就是,当需要对内存的全量数据做快照的时候,将其全部写入磁盘会花费很多时间
- 而且全量数据越多,RDB文件就越大,往磁盘上写数据的时间开销就越大
- 而Redis的单线程模型决定了我们要尽量避免阻塞主线程的操作
- Redis生成RDB文件的命令
- save
- 在主线程中执行,会导致阻塞
- 在服务器进程阻塞期间,服务器不能处理任何命令请求
- bgsave
- 创建一个子进程,专门用于写入RDB文件,可以避免对于主线程的阻塞 — 是Redis RDB的文件生成的默认配置
- save
2.2 做快照的时候数据是否能够被增删改?
我们需要使系统在进行快照的时候仍然能够接受修改请求,要不然会严重影响系统的执行效率
Redis会借助操作系统提供的写时复制技术 — copy on write,在执行快照的同时,正常处理写操作
copy on write
copy operation is deferred until the first write,
could significantly reduce the resource consumption of unmodified copies, while adding a small overhead to resource-modifying operations
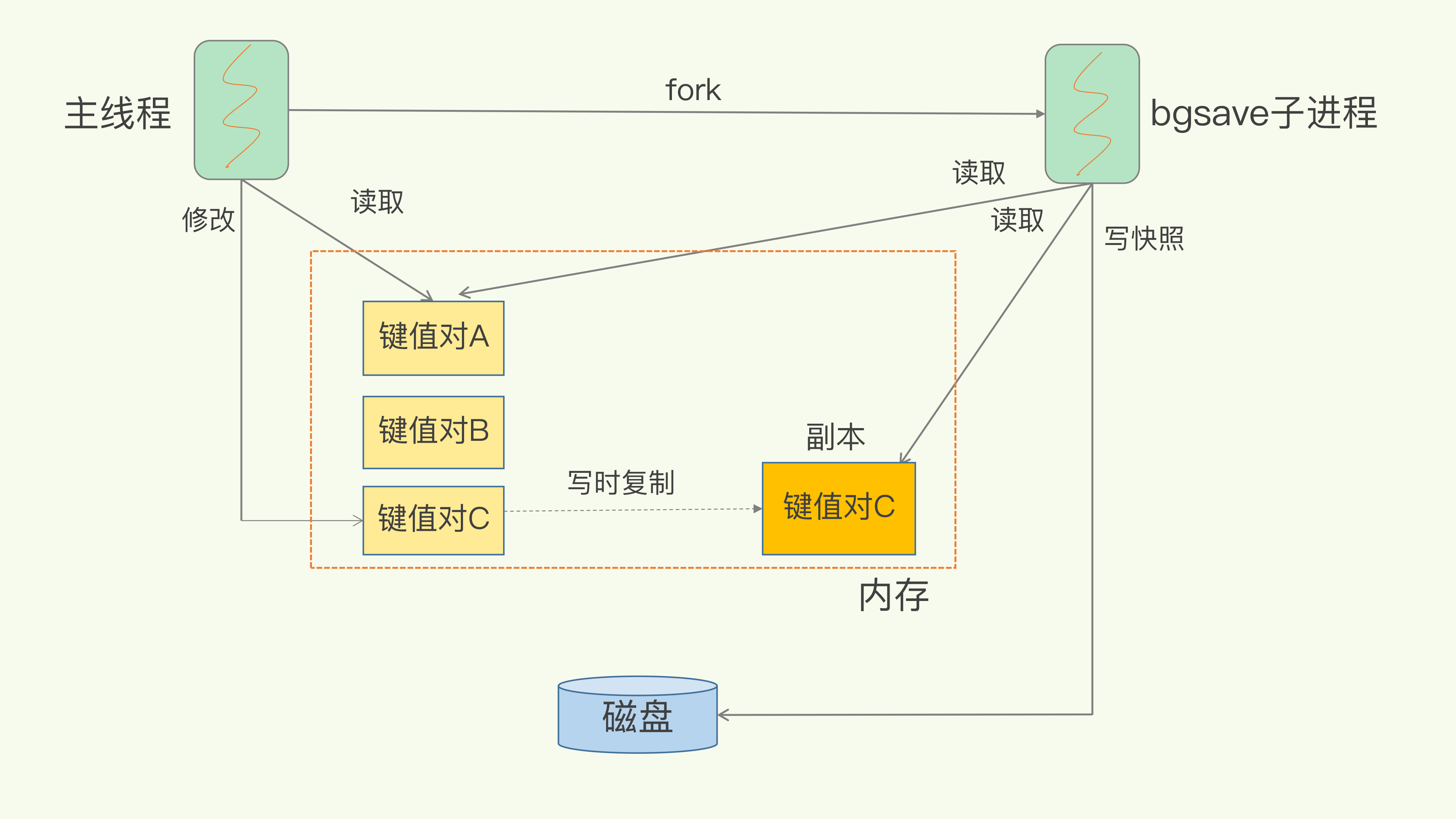
Copy on Write实现
例图当中键值对C发生了改变,那么bgsave子进程还会对原键值对C 进行snapshot,然后过程当中的写操作会被写到副本里面
2.3 多久做一次快照?
- 尽管bgsave执行时不阻塞主线程,但是频繁的执行全量快照,会带来两方面的开销
- 磁盘带宽压力
- 频繁将全量数据写入磁盘,会给磁盘带来很大的压力
- 多个快照竞争有限的磁盘贷款,前一个快照还没有做完,后一个又开始做了,容易造成恶性循环
- fork操作的阻塞
- bgsave子进程需要通过fork操作从主线程创建出来
- fork创建过程本身会阻塞主线程,而且主线程的内存越大,阻塞时间就越长
- 磁盘带宽压力
2.4 RDB文件结构
- 一个RDB文件分成以下几个部分
- REDIS
- 用来检测载入的文件是否为RDB文件
- db_version
- 记录RDB文件的版本号
- databased
- 包含任意多个数据库,以及每个数据库中的键值对数据
- EOF
- 1字节
- 标志着RDB文件正文部分的结束
- check_sum
- 通过对上面四个部分的内容进行计算得出的
- 载入RDB文件的时候,会将载入数据所计算出来的校验和与check_sum所记录的进行对比
- REDIS
3. AOF和RDB混用模式
- 为什么要混用
- AOF执行速度会比较慢
- RDB的全量复制频率难以把控,太低,会容易丢失数据;太高,系统开销会很大
- 如何实现的
- RDB以一定的频率来执行
- 在两次快照之间,使用AOF日志记录这期间所有的命令操作
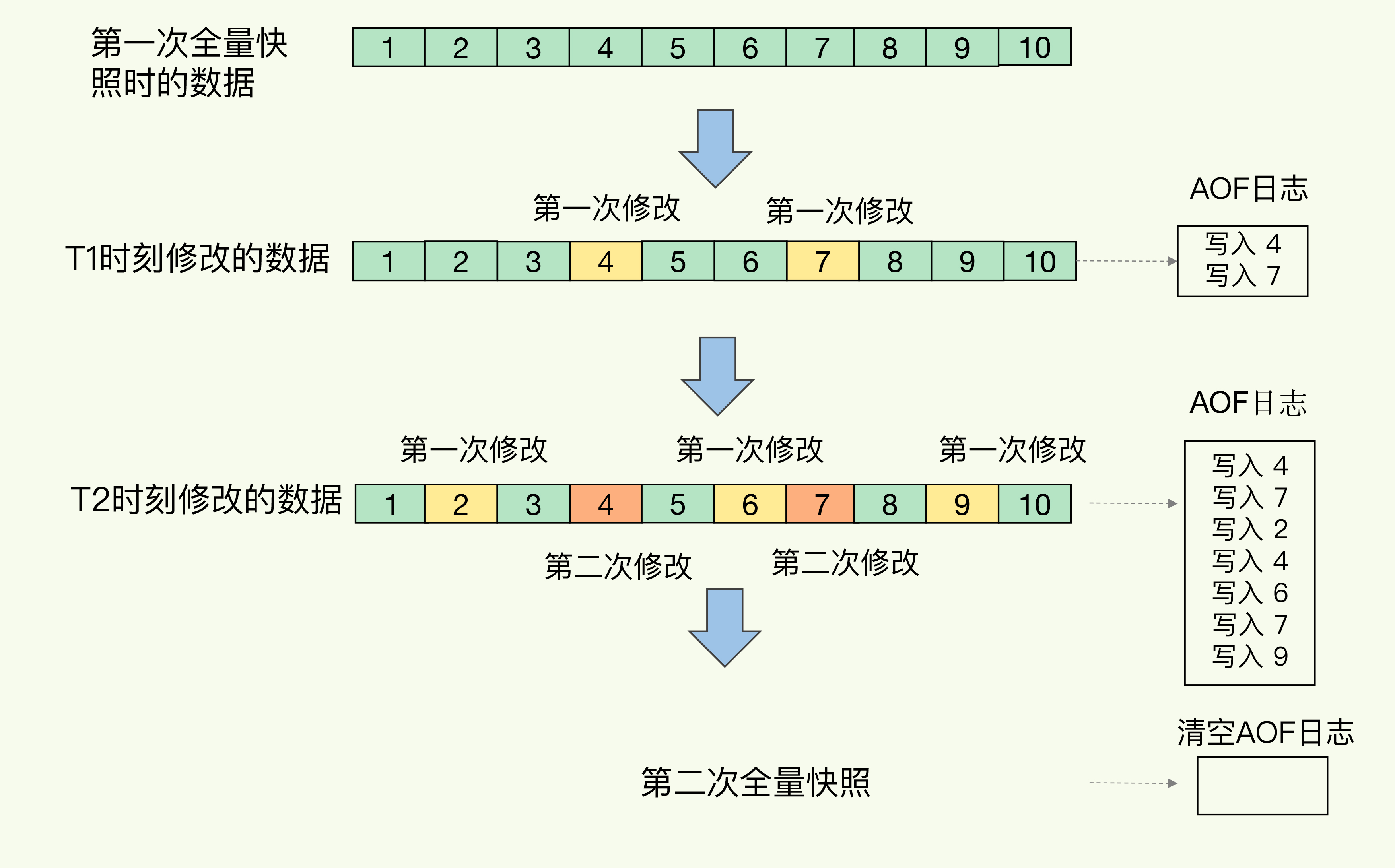
AOF & RDB Mix
- 如上图所示,到了第二次做全量快照的时候,就可以清空AOF日志,因为所有的操作都已经保存到了第二次的全量快照当中了
4. 实际场景探究
我们使用一个 2 核 CPU、4GB 内存、500GB 磁盘的云主机运行 Redis,Redis 数据库的数据量大小差不多是 2GB,我们使用了 RDB 做持久化保证。当时 Redis 的运行负载以修改操作为主,写读比例差不多在 8:2 左右,也就是说,如果有 100 个请求,80 个请求执行的是修改操作。你觉得,在这个场景下,用 RDB 做持久化有什么风险吗?
- 内存资源风险
- Redis fork子进程做RDB持久化,由于写的比例为80%,那么在持久化过程中,“写实复制”会重新分配整个实例80%的内存副本,大约需要重新分配1.6GB内存空间,这样整个系统的内存使用接近饱和,
- 如果此时父进程又有大量新key写入,很快机器内存就会被吃光,如果机器开启了Swap机制,那么Redis会有一部分数据被换到磁盘上,当Redis访问这部分在磁盘上的数据时,性能会急剧下降,已经达不到高性能的标准(可以理解为武功被废)。如果机器没有开启Swap,会直接触发OOM,父子进程会面临被系统kill掉的风险。
- swap 机制
- 将一块磁盘或者一个本地文件当做内存来使用
- 换入
- 当进程再次访问内存的时候,从磁盘读取数据到内存当中
- 换出
Linux系统的swap机制_囚牢-峰子的博客-CSDN博客- 将进程暂时不用的内存数据保存到磁盘上,再释放内存给其他进程使用
- 当进程再次访问内存的时候,从磁盘读取数据到内存中
- 换入
- 将一块磁盘或者一个本地文件当做内存来使用
- swap 机制
- CPU资源风险
- 虽然子进程在做RDB持久化,但生成RDB快照过程会消耗大量的CPU资源,
- 虽然Redis处理处理请求是单线程的,但Redis Server还有其他线程在后台工作,例如AOF每秒刷盘、异步关闭文件描述符这些操作。
- 由于机器只有2核CPU,这也就意味着父进程占用了超过一半的CPU资源,此时子进程做RDB持久化,可能会产生CPU竞争,导致的结果就是父进程处理请求延迟增大,子进程生成RDB快照的时间也会变长,整个Redis Server性能下降。
Reference
- 极客时间
- Redis设计与实现
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:Redis持久化机制-RDB
文章字数:2k
本文作者:Leilei Chen
发布时间:2021-07-05, 06:17:10
最后更新:2021-07-05, 06:18:28
原始链接:https://www.llchen60.com/Redis%E6%8C%81%E4%B9%85%E5%8C%96%E6%9C%BA%E5%88%B6-RDB/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

