Redis IO 模型
Redis IO 模型
为什么单线程的Redis会那么快?
1. Overview
这里的单线程主要指Redis的网络IO和键值对读写是由一个线程来完成的,而Redis的其他功能,比如持久化,异步删除,集群数据同步等,是由额外的线程执行的。
2. 为什么要使用单线程?
使用多线程的开销
使用多线程,一定程度上可以增加系统的吞吐率/ 拓展性
但是值得注意的是多线程本身有开销,并不是线程增多吞吐率会线性增长的。达到了某个线程数之后,系统吞吐率的增长就会开始迟缓了,有时甚至会出现下降的情况
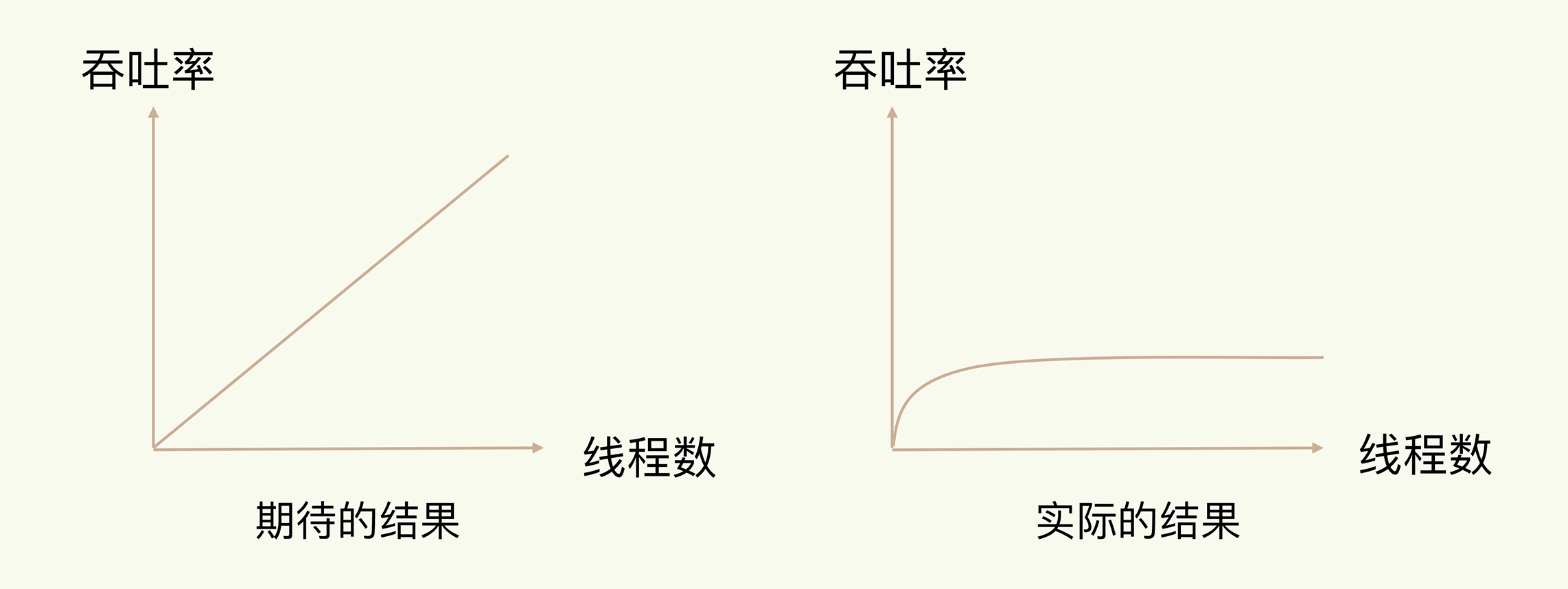
吞吐率随着线程数增长的变化
出现这种情况的原因在于
- 系统中通常会存在被多线程同时访问的共享资源 — 比如一个共享的数据结构
- 当有多个线程要修改这个共享资源的时候,为了保证共享资源的正确性,就需要有额外的机制进行保证。这会带来额外的开销
Redis采用单线程就是希望能够避免这种共享资源放锁的情况
- 而且CPU往往不是Redis的瓶颈,瓶颈很可能是机器内存或者网络带宽
3. 单线程Redis是如何实现低延时的
- High Level Takeaway
- 内存上完成操作
- 高效的数据结构
- 多路复用机制 — 网络IO能够并发处理大量的客户端请求
3.1 基本IO模型和阻塞点
以前面的SimpleKV为例,为了处理一个Get请求,数据库需要:
- 监听客户端请求(bind/ listen)
- 和客户端建立连接 (accept)
- 从socket中读取请求(recv)
- 解析客户端发送请求(parse)
- 根据请求类型读取键值数据(get)
- 从客户端返回结果,即向socket中写回数据(send)
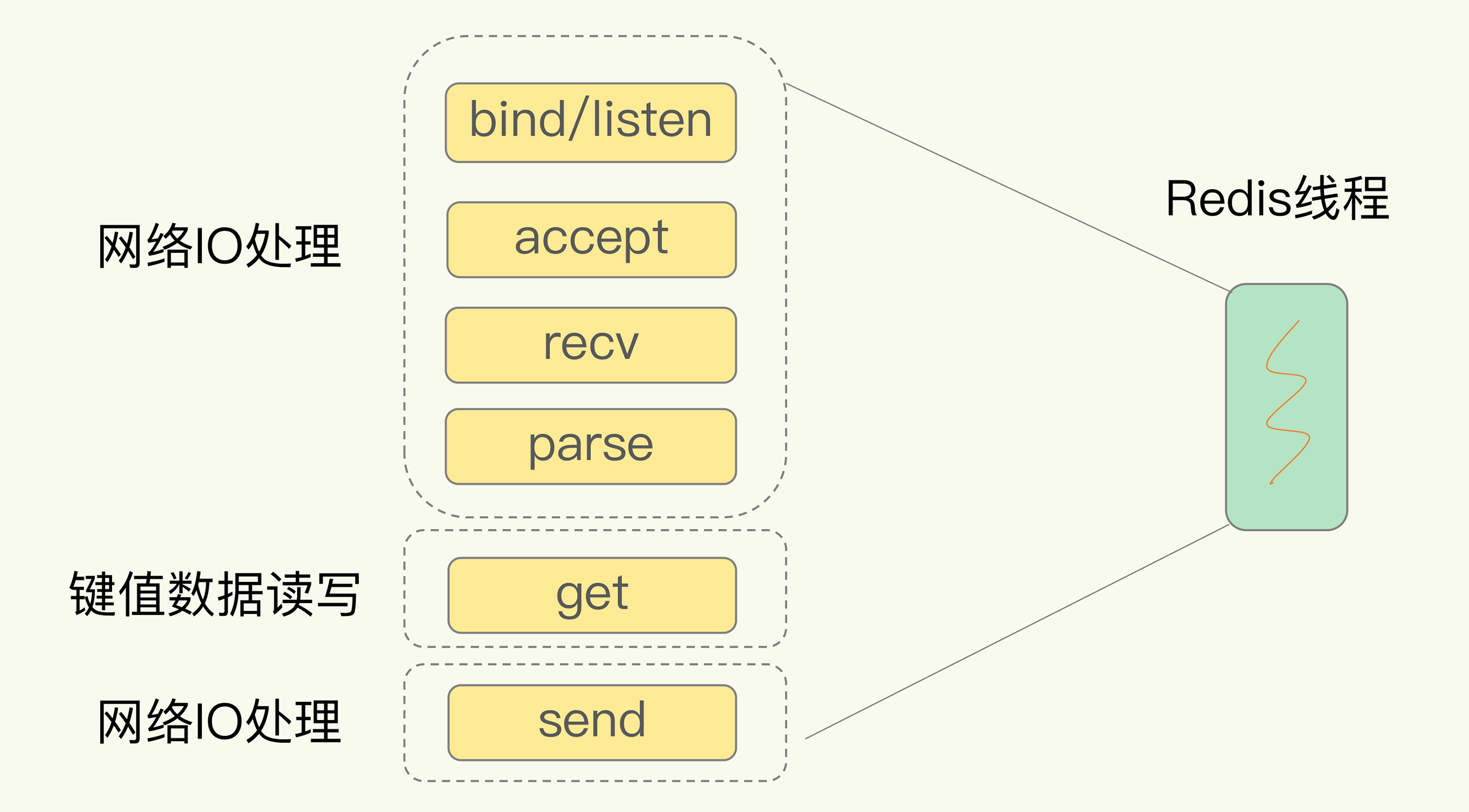
Get请求处理示意图
在上述的整个过程当中,如果Redis监听到客户端请求,但没有成功建立连接的时候,会阻塞在accept函数上,导致其他的客户端无法建立连接。这种基本IO模型效率会非常低,因为是阻塞式的,任何一个请求出现了任何一个问题,都会导致其他的请求无法成功完成。
3.2 非阻塞模式
Socket网络模型的非阻塞模式体现在不同操作调用后会返回不同的套接字类型。socket() 方法会返回主动套接字,然后调用 listen() 方法,将主动套接字转化为监听套接字,此时,可以监听来自客户端的连接请求。最后,调用 accept() 方法接收到达的客户端连接,并返回已连接套接字。
这样子可以实现非阻塞,值得注意的是我们需要一些机制来监听套接字,有数据到达的时候再通知数据库线程
3.3 基于多路复用的高性能I/O模型
- 是什么
- 指让一个线程能够处理多个IO流
- select epoll机制
- 在内核中,存在多个监听套接字和已连接套接字
- 内核会一直监听这些套接字上的连接请求或者数据请求
- 为什么使用I/O多路复用这种技术
- 解决单线程下阻塞操作的问题
- 如何实现的
- select epoll方法同时监控多个文件描述符FD的读写情况,当某些FD可读/ 可写的时候,该方法就会返回可读/ 写的FD个数
IO多路复用:Redis中经典的Reactor设计模式- 将用户Socket对应的FD注册进epoll,然后epoll告诉那些需要进行读写操作的socket,只处理那些活跃的,有变化的socket FD
- select epoll方法同时监控多个文件描述符FD的读写情况,当某些FD可读/ 可写的时候,该方法就会返回可读/ 写的FD个数
https://draveness.me/redis-io-multiplexing/
https://cloud.tencent.com/developer/article/1639569
https://blog.csdn.net/u014590757/article/details/79860766
一个线程处理多个IO流 — select / epoll机制
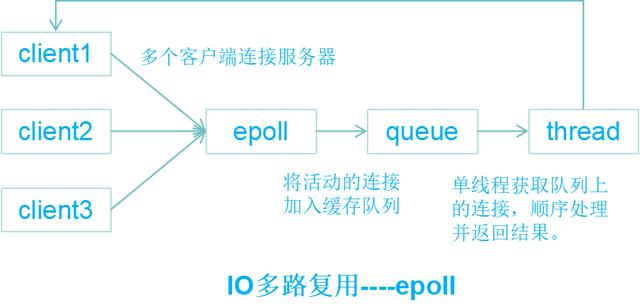
epoll机制
允许内核中,同时存在多个监听套接字和已连接套接字
内核会一直监听这些套接字上的连接请求或数据请求
一旦有请求到达,就会交给Redis线程处理
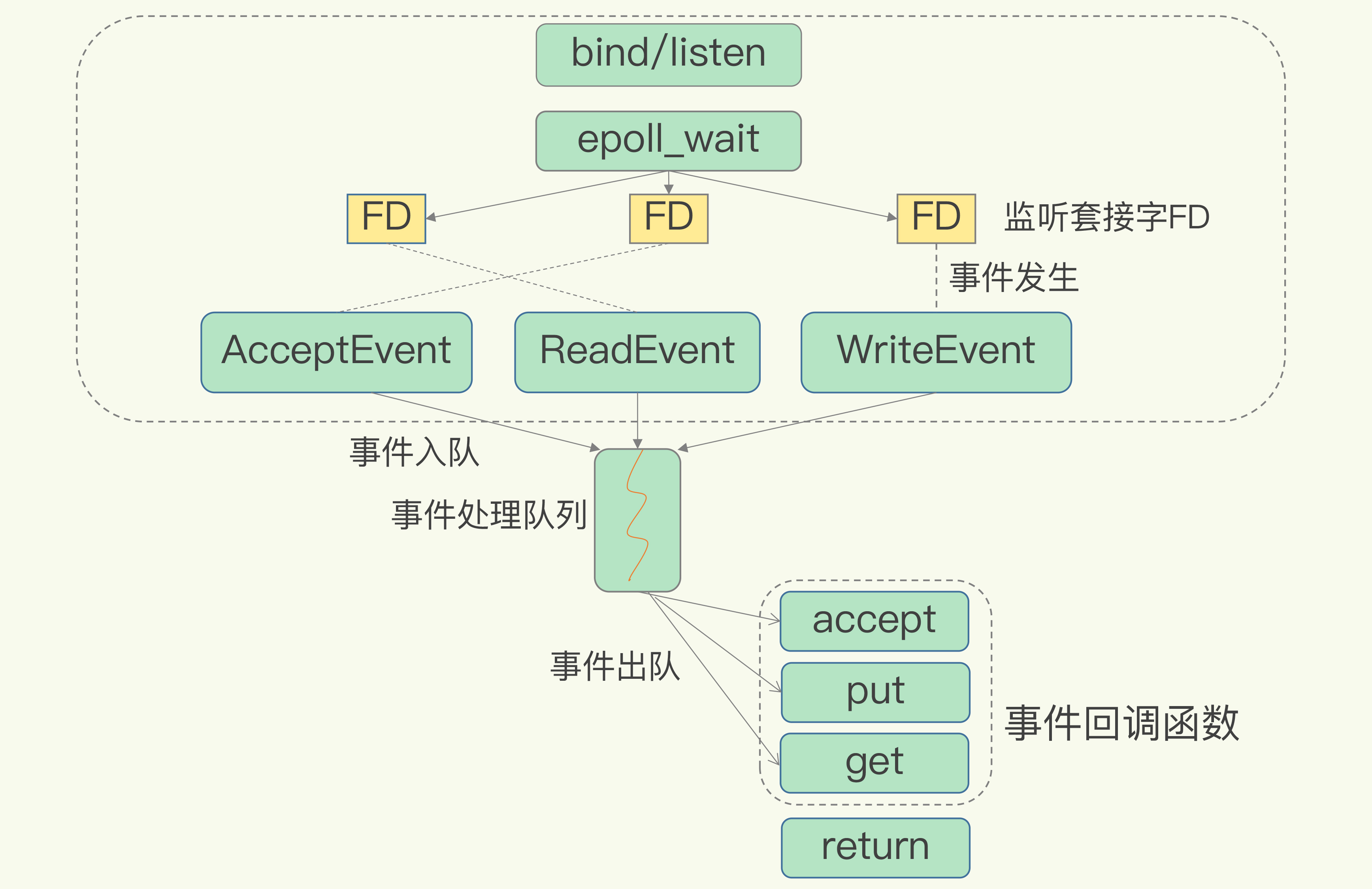
多路复用全程
select/ epoll 一旦检测到FD上有请求到达,就会触发相应的事件
- 事件会被放到一个事件队列,Redis单线程对该事件队列不断进行处理
3.3 单线程处理的性能瓶颈
1、任意一个请求在server中一旦发生耗时,都会影响整个server的性能,也就是说后面的请求都要等前面这个耗时请求处理完成,自己才能被处理到。耗时的操作包括以下几种:
a、操作bigkey:写入一个bigkey在分配内存时需要消耗更多的时间,同样,删除bigkey释放内存同样会产生耗时;
b、使用复杂度过高的命令:例如SORT/SUNION/ZUNIONSTORE,或者O(N)命令,但是N很大,例如lrange key 0 -1一次查询全量数据;
c、大量key集中过期:Redis的过期机制也是在主线程中执行的,大量key集中过期会导致处理一个请求时,耗时都在删除过期key,耗时变长;
d、淘汰策略:淘汰策略也是在主线程执行的,当内存超过Redis内存上限后,每次写入都需要淘汰一些key,也会造成耗时变长;
e、AOF刷盘开启always机制:每次写入都需要把这个操作刷到磁盘,写磁盘的速度远比写内存慢,会拖慢Redis的性能;
f、主从全量同步生成RDB:虽然采用fork子进程生成数据快照,但fork这一瞬间也是会阻塞整个线程的,实例越大,阻塞时间越久;
2、并发量非常大时,单线程读写客户端IO数据存在性能瓶颈,虽然采用IO多路复用机制,但是读写客户端数据依旧是同步IO,只能单线程依次读取客户端的数据,无法利用到CPU多核。
针对问题1,一方面需要业务人员去规避,一方面Redis在4.0推出了lazy-free机制,把bigkey释放内存的耗时操作放在了异步线程中执行,降低对主线程的影响。
针对问题2,Redis在6.0推出了多线程,可以在高并发场景下利用CPU多核多线程读写客户端数据,进一步提升server性能,当然,只是针对客户端的读写是并行的,每个命令的真正操作依旧是单线程的。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:Redis IO 模型
文章字数:1.7k
本文作者:Leilei Chen
发布时间:2021-07-03, 02:54:57
最后更新:2021-07-03, 02:59:13
原始链接:https://www.llchen60.com/Redis-IO-%E6%A8%A1%E5%9E%8B/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

