DynamoDB Architecture (Paper Reading)
- 1. Overview
- 2. High Level Design
1. Overview
- Designed to be always on
- Dynamo falls within the category of AP systems (available and partition tolerant) and is designed for high availability and partition tolerance at the expense of strong consistency
1.1 Design Goals
- Scalable
- System need to be highly scalable. We should be able to throw a machine into the system to see proportional improvement
- Decentralized
- To avoid single points of failures and performance bottlenecks, there should not be any central/ leader process
- Eventually Consistent
- Data can be optimistically replicated to become eventually consistent
1.2 Use cases
- eventually consistent database
1.3 System APIs
- put(key, context, object)
- find the nodes where the object associated with the given key should locate
- context is a value that is returned with a get operation and then sent back with the put operation
- context is always stored along with the object
- used like a cookie to verify the validity of the object supplied in the put request
- get(key)
- find the nodes where the object associated with the given key is located
- return a single object or a list of objects with conflicting versions along with a context
- context contains encoded metadata about the object, and version of the object
2. High Level Design
2.1 Data Distribution
2.1.1 What is it
- Consistent hashing to distribute its data among nodes
- Also make it easy to add/ remove nodes from a dynamo cluster
2.1.2 Challenge
- how do we know on which node a particular piece of data will be stored?
- when we add/ remove nodes, how do we know what data will be moved from existing nodes to the new nodes?
- how can we minimize data movement when nodes join or leave?
2.1.3 Consistent Hashing
Represents the data managed by a cluster as a ring
Each node in the ring is assigned a range of data
Token
The start of the range is called a token
each node will be assigned with one token
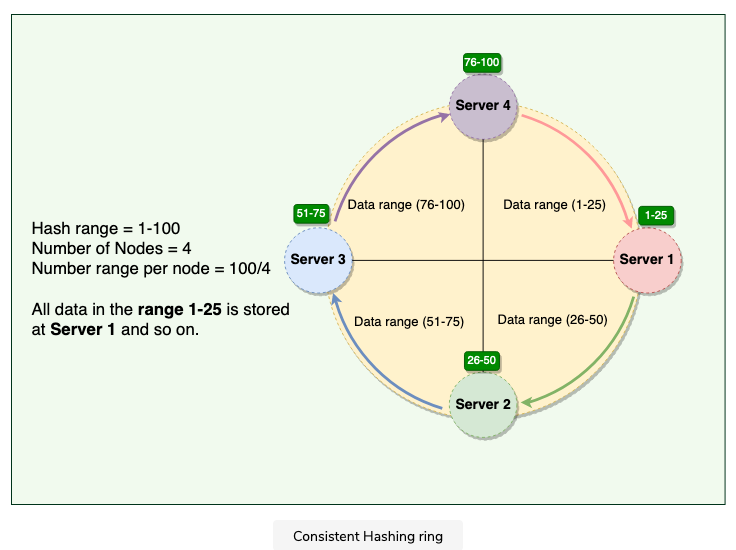
Process for a put or get request
- DDB performs a MD5 hashing algorithm to the key
- Output determines within which range the data lies —→ which node the data will be stored
Problems for only use physical nodes
- for adding or removing nodes, it only influence the next node, but it would cause uneven distribution of traffic
- recomputing the tokens causing a significant administrative overhead for a large cluster
- Since each node is assigned one large range, if the data is not evenly distributed, some nodes can become hotspots
- Since each node’s data is replicated on a fixed number of nodes (discussed later), when we need to rebuild a node, only its replica nodes can provide the data. This puts a lot of pressure on the replica nodes and can lead to service degradation
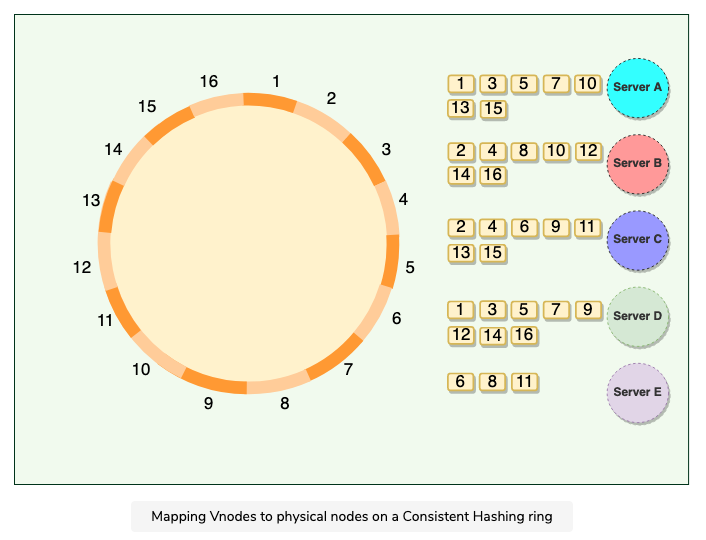
2.1.4 Virtual Nodes
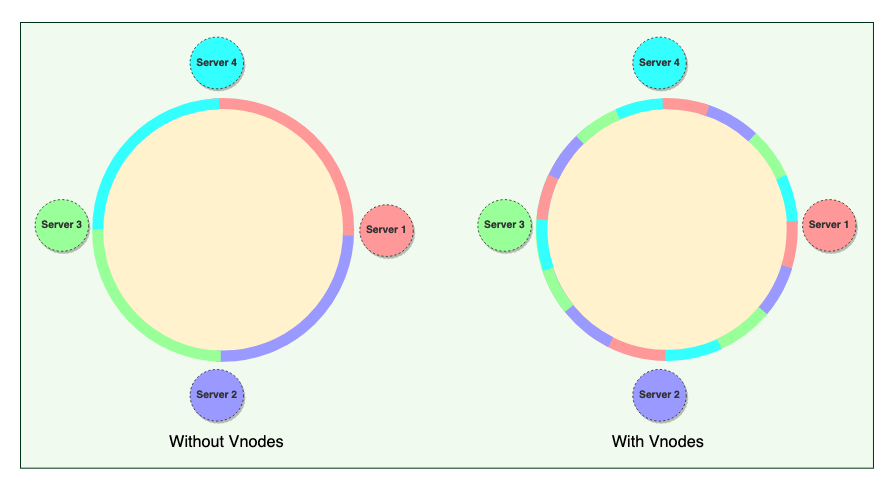
Hash range is divided into multiple smaller ranges, and each physical node is assigned multiple of these smaller ranges
Each of these subranges is called a Vnode
Vnodes are randomly distributed across the cluster and are generally non contiguous (不连续的)
Benefits of Vnodes
- Help spread the load more evenly across the physical nodes on the cluster by dividing the hash range into smaller subranges
- speeds up the rebalancing process after adding or removing nodes
- When a new node is added, it receives many Vnodes from the existing nodes to maintain a balanced cluster. Similarly, when a node needs to be rebuilt, instead of getting data from a fixed number of replicas, many nodes participate in the rebuild process.
- Vnodes make it easier to maintain a cluster containing heterogeneous machines. This means, with Vnodes, we can assign a high number of ranges to a powerful server and a lower number of ranges to a less powerful server
- Since Vnodes help assign smaller ranges to each physical node, the probability of hotspots is much less than the basic Consistent Hashing scheme which uses one big range per node
- Help spread the load more evenly across the physical nodes on the cluster by dividing the hash range into smaller subranges
2.2 Data Replication and Consistency
- Data is replicated optimistically
- Dynamo provides eventual consistency
2.2.1 Optimistic Replication
To ensure high availability and durability, Dynamo replicates each data item on multiple N nodes in the system where the value N is equivalent to the replication factor, also is configured per instance of Dynamo
Each key is assigned to a coordinator node, which first stores the data locally and then replicates it to N-1 clockwise successor nodes on the ring
- Thus each node owns the region on the ring between it and its Nth predecessor
Replication is done asynchronously and Dynamo provides an eventually consistent model
It’s called optimistic replication, as the replicas are not guaranteed to be identical at all times
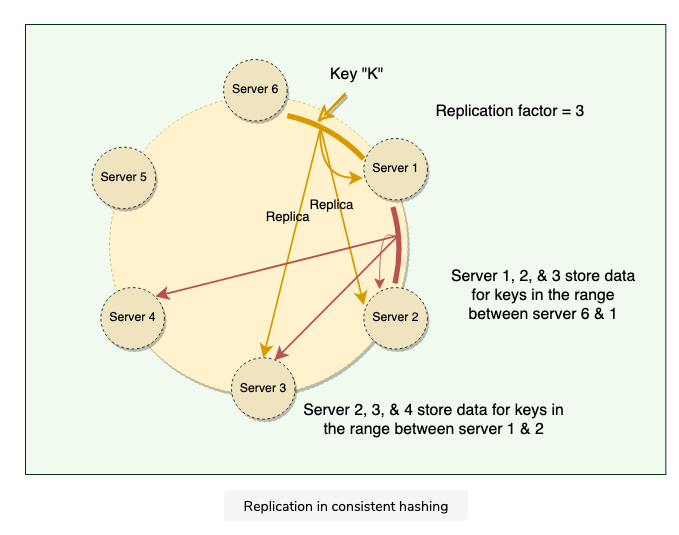
Preference List
- List of nodes responsible for storing a particular key
- Dynamo is designed so that every node in the system can determine which nodes should be in the list for any specific key
- The list contains more than N nodes to account for failures and skip virtual nodes on the ring so that the list only contains distinct physical nodes
2.3 Handling Temporary Failures
- To handle temporary failures, dynamo replicates data to a sloppy quorum of other nodes in the system instead of a strict majority quorum
2.3.1 Quorum Approach
- Traditional quorum approach
- any distributed system becomes unavailable during server failures or network partitions and would have reduced availability even under simple failure conditions
- Sloppy quorum
- all read/ write operations are performed on the first N healthy nodes from the preference list. may not always be the first N nodes encountered while moving clockwise on the consistent hashing ring
2.3.2 Hinted Handoff
- When a node is unreachable, another node can accept writes on its behalf
- Write is then kept in a local buffer and sent out once the destination node is reachable again
- Problem
- Sloppy quorum is not a strict majority, the data can and will diverge
- It is possible for two concurrent writes to the same key to be accepted by non-overlapping sets of nodes. This means that multiple conflicting values against the same key can exist in the system, and we can get stale or conflicting data while reading. Dynamo allows this and resolves these conflicts using Vector Clocks.
2.4 Inter node communication and failure detection
- Use gossip protocol to keep track of the cluster state
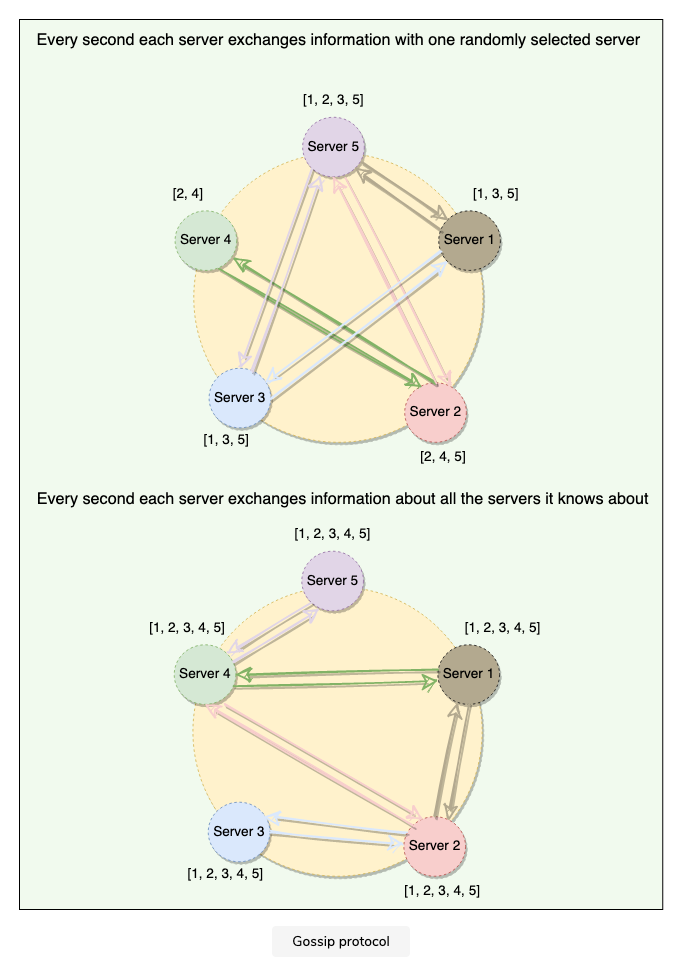
2.4.1 Gossip Protocol
Enable each node to keep track of state information about the other nodes in the cluster
- which nodes are reachable
- what key ranges they are responsible for
Gossip Protocol
Peer to peer communication mechanism
nodes periodically exchange state information about themselves and other nodes they know about
each node initiate a gossip round every second with a random node
External discovery through seed nodes
- An administrator joins node A to the ring and then joins node B to the ring. Nodes A and B consider themselves part of the ring, yet neither would be immediately aware of each other. To prevent these logical partitions, Dynamo introduced the concept of seed nodes. Seed nodes are fully functional nodes and can be obtained either from a static configuration or a configuration service. This way, all nodes are aware of seed nodes. Each node communicates with seed nodes through gossip protocol to reconcile membership changes; therefore, logical partitions are highly unlikely.
2.5 Conflict Resolution and Handling permanent failures
2.5.1 Clock Skew
- Dynamo resolves potential conflicts using below mechanisms
- use vector clocks to keep track of value history and reconcile divergent histories at read time
- in the background, dynamo use an anti entropy mechanism like Merkle trees to handle permanent failures
2.5.2 Vector Clock
Used to capture causality between different versions of the same object
A vector clock is a
node, counterpairEach version of every object associate with a vector clock
- one can determine whether two versions of an object are on parallel branches or have a causal ordering by examining vector clocks
- If the counters on the first object’s clock are less-than-or-equal to all of the nodes in the second clock, then the first is an ancestor of the second and can be forgotten. Otherwise, the two changes are considered to be in conflict and require reconciliation.
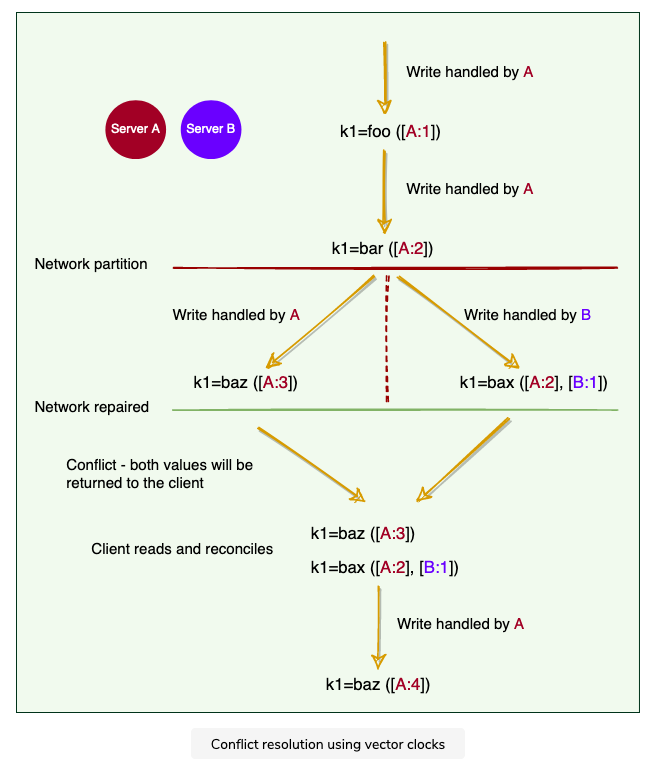
Issue occur when there are network partition, that same data cannot be shared / communicated via different servers
In this case, DynamoDB will return it back and let client reads and reconciles
2.5.3 Conflict free replicated data types (CRDTs)
- we need to model our data in such a way that concurrent changes can be applied to the data in any order and will produce the same end result
2.6 put() and get() Operations
2.6.1 Strategies for choosing the coordinator node
Strategies
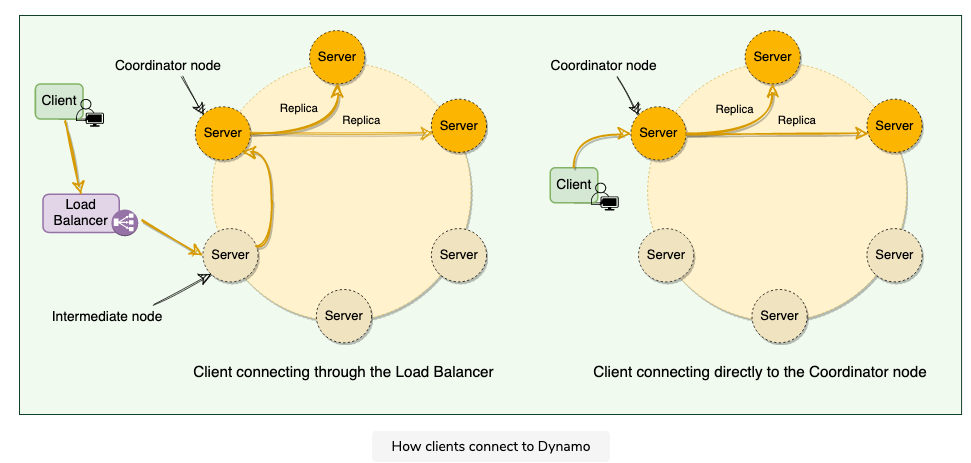
- Clients can route their requests through a generic load balancer
- client is unaware of the dynamo ring
- helps scalability
- make ddb architecture loosely coupled
- it’s possible node it select is not part of the perference list, this will result in an extra hop
- client is unaware of the dynamo ring
- Clients can use a partition aware client library that routes the request to the appropriate coordinator nodes with lower latency
- helps to achieve lower latency — achieve zero hop
- DDB doesn’t have much control over the load distribution and request handling
- Clients can route their requests through a generic load balancer
2.6.2 Consistency Protocol
- R W is the min number of nodes that must participate in a successful read/ write operation
- R + W > N yields a quorun like system
- A Common (N,R,WN, R, WN,R,W) configuration used by Dynamo is (3, 2, 2)
- In general, low values of WWW and RRR increase the risk of inconsistency, as write requests are deemed successful and returned to the clients even if a majority of replicas have not processed them. This also introduces a vulnerability window for durability when a write request is successfully returned to the client even though it has been persisted at only a small number of nodes
2.6.3 put() process
- the coordinator generates a new data version and vector clock component
- saves new data locally
- sends the write request to N-1 highest ranked healthy nodes from the preference list
- the put() operation is considered successful after receiving W - 1 confirmation
2.6.4 get() process
- coordinator requests the data version from N - 1 highest ranked healthy nodes from the preference list
- waits until R - 1 replies
- coordinator handles causal data versions through a vector clock
- returns all relevant data versions to the caller
2.6.5 Request handling through state machine
- Each client request results in creating a state machine on the node that received the client request
- A read operation workflow would be:
- send read requests to the nodes
- wait for the minimum number of required responses
- if too few replies were received within a given time limit, fail the request
- otherwise, gather all the data versions and determine the ones to be returned
- if versioning is enabled, perform syntactic reconciliation and generate an opaque write context that contains the vector clock that subsumes all the remaining versions
- At this point, read response has been returned to the caller
- the state machine waits for a short period to receive any outstanding responces
- if stale versions were returned in any of the responses, the coordinator updates those nodes with the latest version — READ REPAIR
2.7 Anti-entropy Through Merkle Trees
- Vector clocks are useful to remove conflicts while serving read requests
- But if a replica falls significantly behind others, it might take a very long time to resolve conflicts using just vector clocks
—> we need to quickly compare two copies of a range of data residing on different replicas and figure out exactly which parts are different
2.7.1 What are MerkleTrees?
Dynamo use Merkel Trees to compare replicas of a range
A merkle tree is a binary tree of hashes, where each internal node is the hash of its two children, each leaf node is a hash of a portion of the original data
Then compare the merkle tree come to be super easy, just compare the root hashes of both trees, if equal, then stop; else, recurse on the left and right children
The principal advantage of using a Merkle tree is that each branch of the tree can be checked independently without requiring nodes to download the entire tree or the whole data set. Hence, Merkle trees minimize the amount of data that needs to be transferred for synchronization and reduce the number of disk reads performed during the anti-entropy process.
The disadvantage of using Merkle trees is that many key ranges can change when a node joins or leaves, and as a result, the trees need to be recalculated.
2.8 Dynamo Characteristics
2.8.1 Dynamo’s Node Responsibilities
- Each node serves three functions:
- Managing
get()andput()requests- A node may act as a coordinator and manage all operations for a particular key
- A node also could forward the request to the appropriate node
- Managing
- Keep track of membership and detecting failures
- Every node uses gossip protocol to keep track of other nodes in the system and their associated hash ranges
- Local persistent storage
- Each node is responsible for being either the primary or replica store for keys that hash to a specific range of values
- These pairs are stored within that node using various storage systems depending on application needs
- E.G
- BerkeleyDB Transactional Data Store
- MySQL
- In memory buffer backed by persistent storage
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:DynamoDB Architecture (Paper Reading)
文章字数:2.2k
本文作者:Leilei Chen
发布时间:2021-08-08, 04:14:38
最后更新:2021-08-09, 02:51:22
原始链接:https://www.llchen60.com/DynamoDB-Architecture-Paper-Reading/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

