网络协议(十) - RPC, SOAP, RESTful
1. RPC协议综述
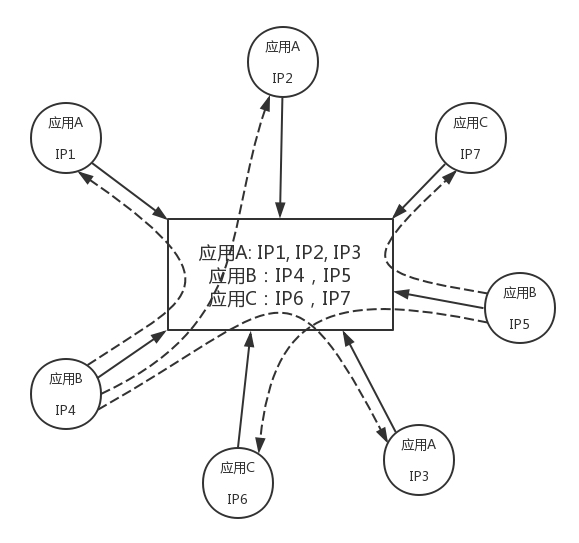
我们需要研究的是在网络打通以后,服务之间是如何互相调用的呢?
实质上是调用方和被调用方之间建立一个TCP或者UDP连接,来进行通信的。
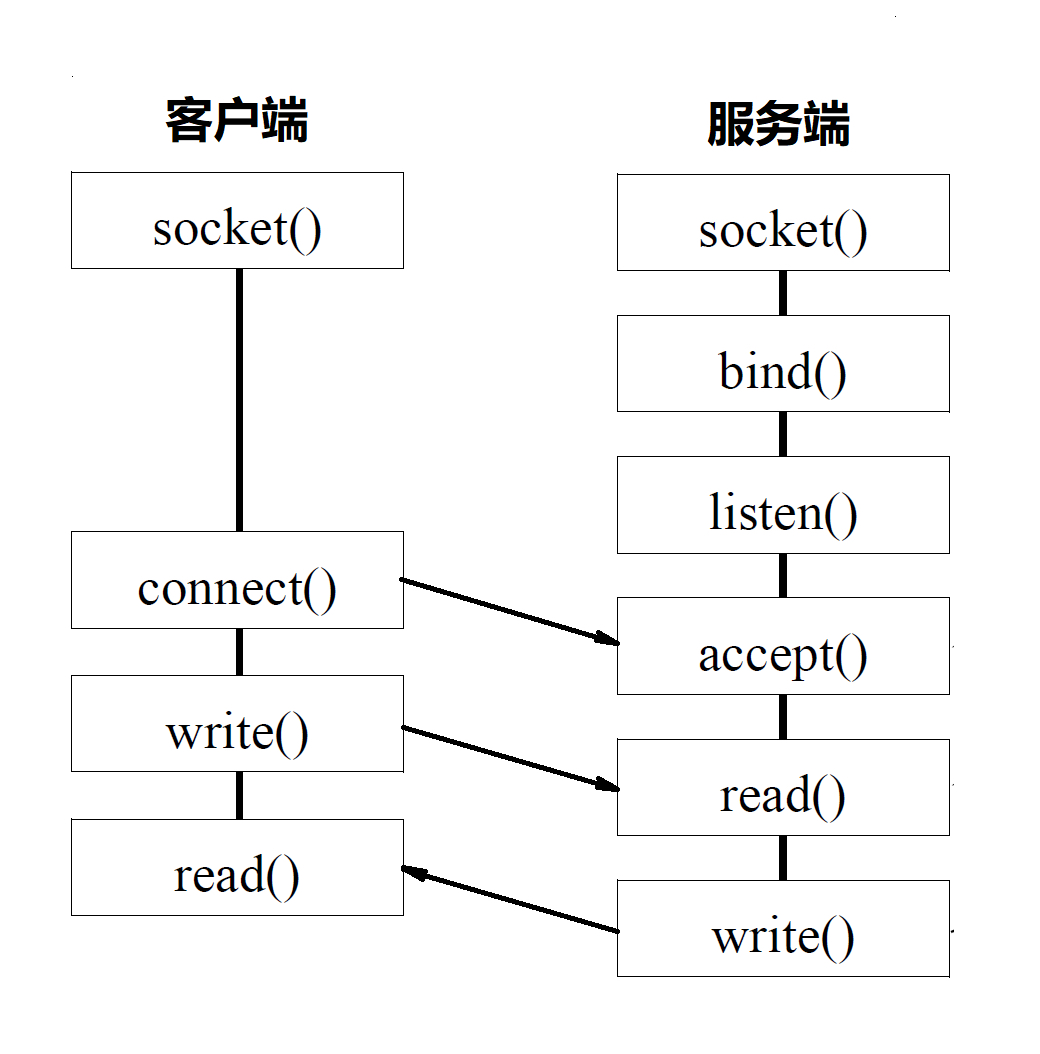
但是实际过程会非常复杂,假设一个场景,即客户端调用一个加法函数,将两个整数相加返回他们的和。放在远程调用上,因为要牵扯到网络,就要牵扯到Socket编程.
1.1 实现远程调用的问题
- 如何规定远程调用的语法?
如何表示加减,如何表示整数间的和小数间的?
- 如何传递参数?
参数和操作符的传递顺序;TCP流如何区分各个参数
- 如何表示数据?
对于长度不一定的类,结构体,怎么给空间来传递?
Big Endian 和Little Endian,采用的方式不一样的问题。
- 如何知道一个服务端都实现了哪些远程调用?从哪个端口可以访问到?
假设服务端实现了多个远程调用,每个可能实现在不同的进程当中,监听的端口也不一样,而且由于服务端都是自己实现的,不可能使用一个大家都公认的端口,而且有可能多个进程部署在同一台机器上,大家就需要抢占端口,为了防止冲突,往往使用随机端口,那客户端如何找到这些监听的端口呢?
- 发生了错误、重传、丢包、性能等问题怎么办?
本地调用没有这个问题,但是一旦到网络上,这些问题都需要处理,因为网络是不可靠的,虽然在同一个连接中,我们还可通过 TCP 协议保证丢包、重传的问题,但是如果服务器崩溃了又重启,当前连接断开了,TCP 就保证不了了,需要应用自己进行重新调用,重新传输会不会同样的操作做两遍,远程调用性能会不会受影响呢?
1.2 协议约定问题
上述的各种问题是需要服务端和客户端协商来解决的,Jay Nelson写了一篇论文,Implementing Remote Procedure Calls 定义了RPC的标准。
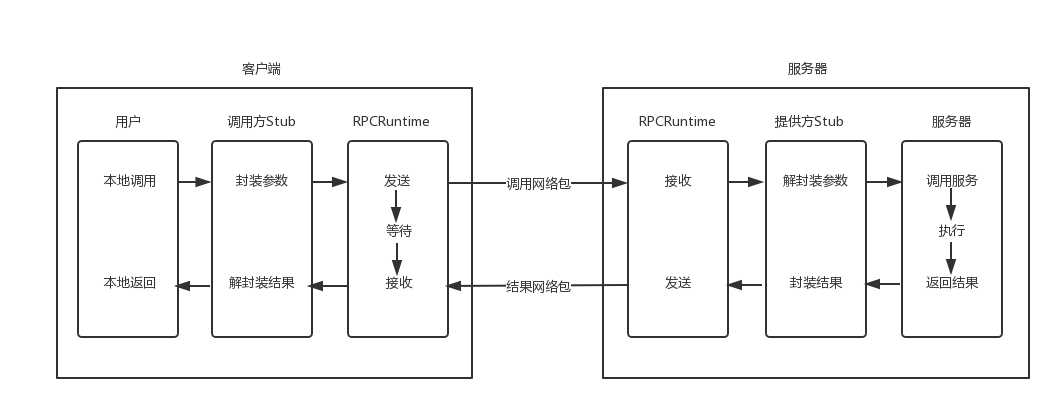
1.2.1 客户端发起远程调用
通过本地调用本地调用方的Stub,负责将调用的接口、方法和参数,通过约定的协议规范进行编码,并通过本地的RPCRuntime进行传输,将调用网络包发送到服务器上。
1.2.2 服务器端处理请求
服务器端的RPCRuntime收到请求以后,交给提供方Stub进行解码,然后调用服务端的方法,服务端执行方法,返回结果,提供方Stub将返回结果编码后,发送给客户端,客户端的RPCRuntime收到结果,发给调用方Stub解码得到结果,返回给客户端。
1.2.3 分析
这里面分了三个层次,对于客户端和服务端,都像是本地调用一样,专注于业务逻辑的处理就可以了。对于Stub层,主要处理双方约定好的语法、语义、封装、解封装。对于RPCRuntime,主要处理高性能的传输,以及网络的错误和异常。
1.3 RPC调用细节
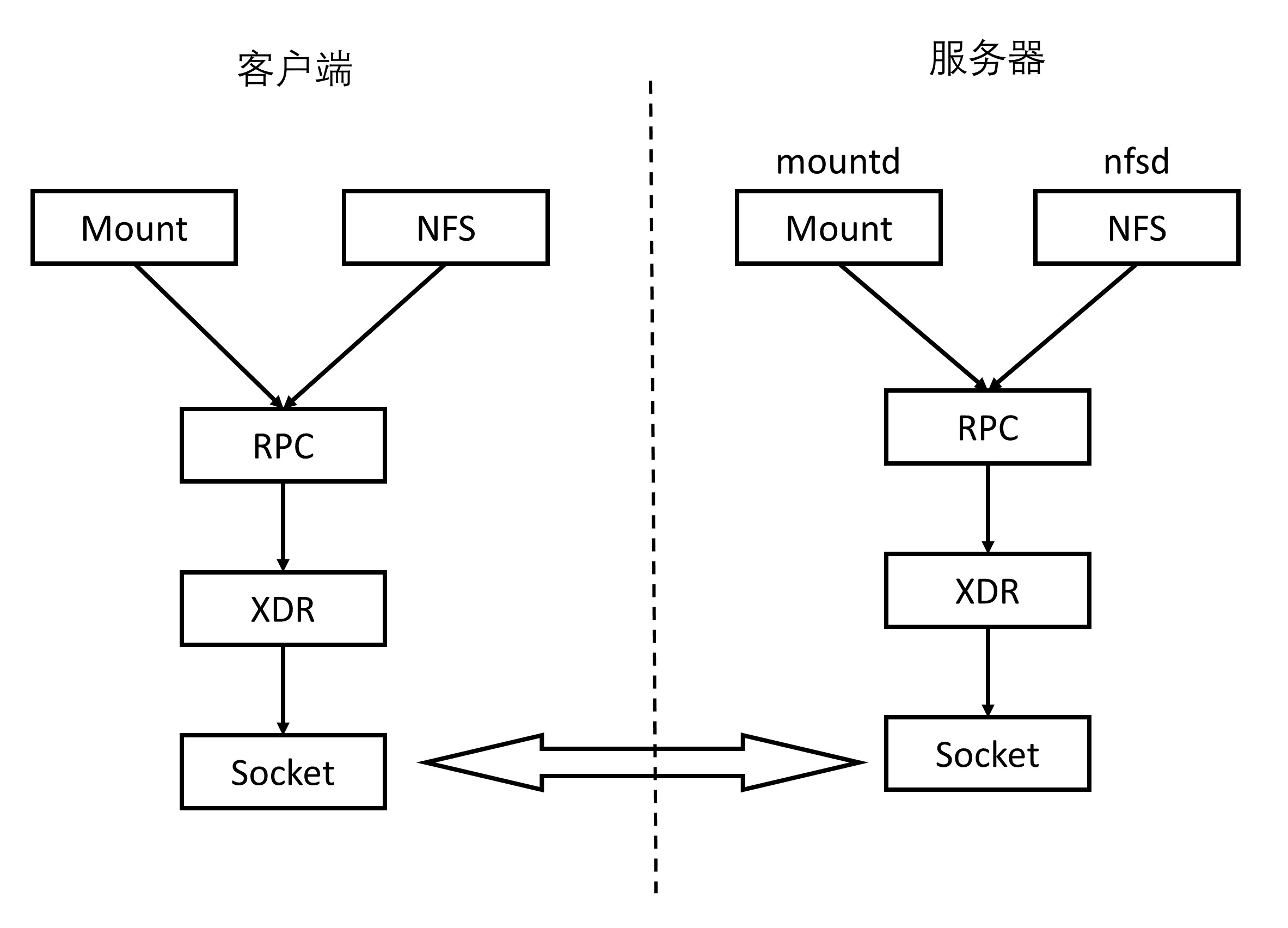
最早的RPC是在NFS协议中使用的。NFS(Network File System)就是网络文件系统。要使NFS成功运行,要启动两个服务端,一个是MountID,用来挂载文件路径;一个是nfsd,用来读写文件。NFS可以在本地mount一个远程的目录到本地的一个目录,从而本地的用户在这个目录里面读写的时候,实际上操作的是远程另一台机器上的文件。
XDR(External Data Representation,外部数据表示法)是一个标准的数据压缩格式,可以表示基本的数据类型,也可以表示结构体。
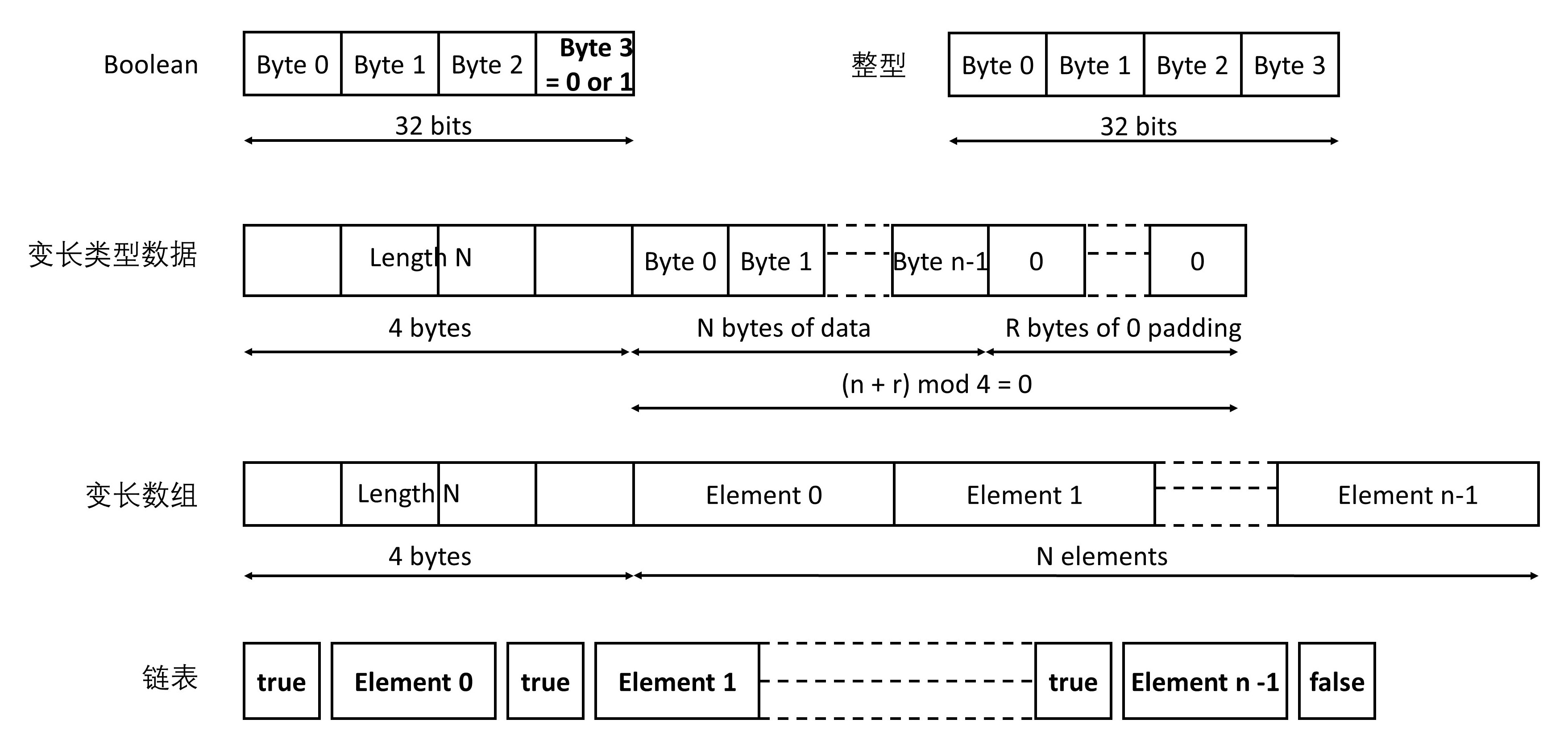
在RPC的调用中,所有的数据类型都要封装成类似的格式。而且RPC的调用和结果的返回,也有严格的格式。
- XID 唯一标识一对请求和回复。请求为 0,回复为 1。
- RPC 有版本号,两端要匹配 RPC 协议的版本号。如果不匹配,就会返回 Deny,原因就是 RPC_MISMATCH。
- 程序有编号。如果服务端找不到这个程序,就会返回 PROG_UNAVAIL。
- 程序有版本号。如果程序的版本号不匹配,就会返回 PROG_MISMATCH。
- 一个程序可以有多个方法,方法也有编号,如果找不到方法,就会返回 PROC_UNAVAIL。
- 调用需要认证鉴权,如果不通过,则 Deny。
- 对于参数列表,如果参数无法解析,则返回GARBAGE_ARGS
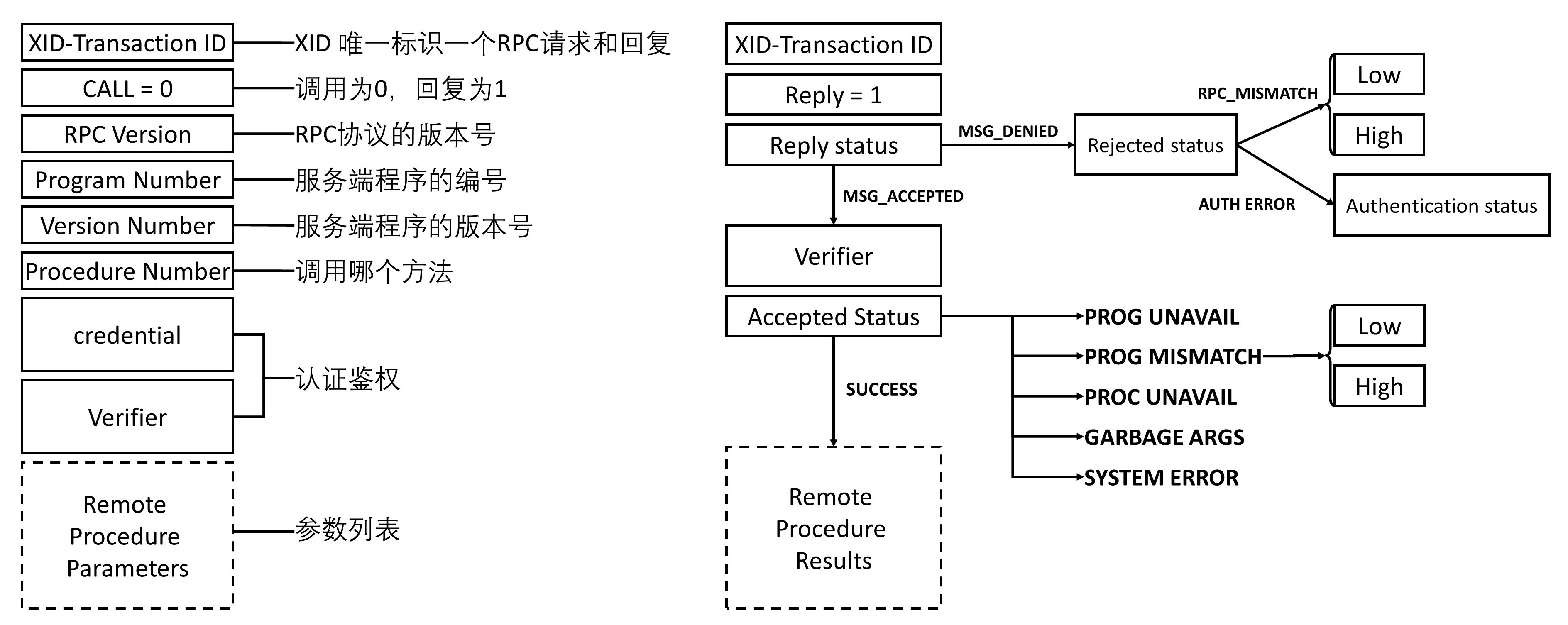
因此为了可以成功调用RPC,在客户端和服务端实现RPC的时候,首先要定义一个双方都认可的程序、版本、方法、参数等。
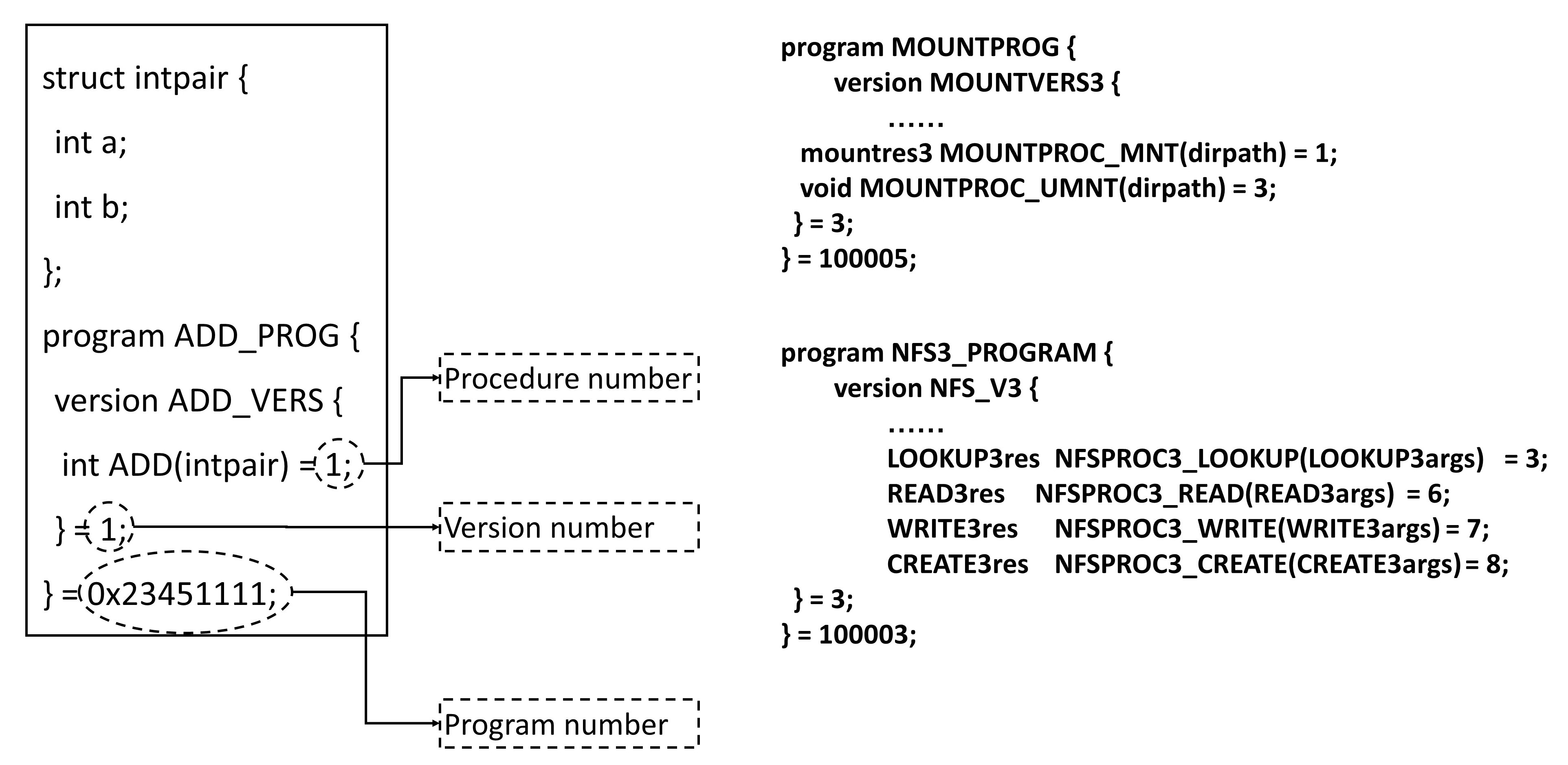
如果还是上面的加法,则双方约定为一个协议定义文件,同理如果是 NFS、mount 和读写,也会有类似的定义。
有了协议定义文件,ONC RPC 会提供一个工具,根据这个文件生成客户端和服务器端的 Stub 程序。
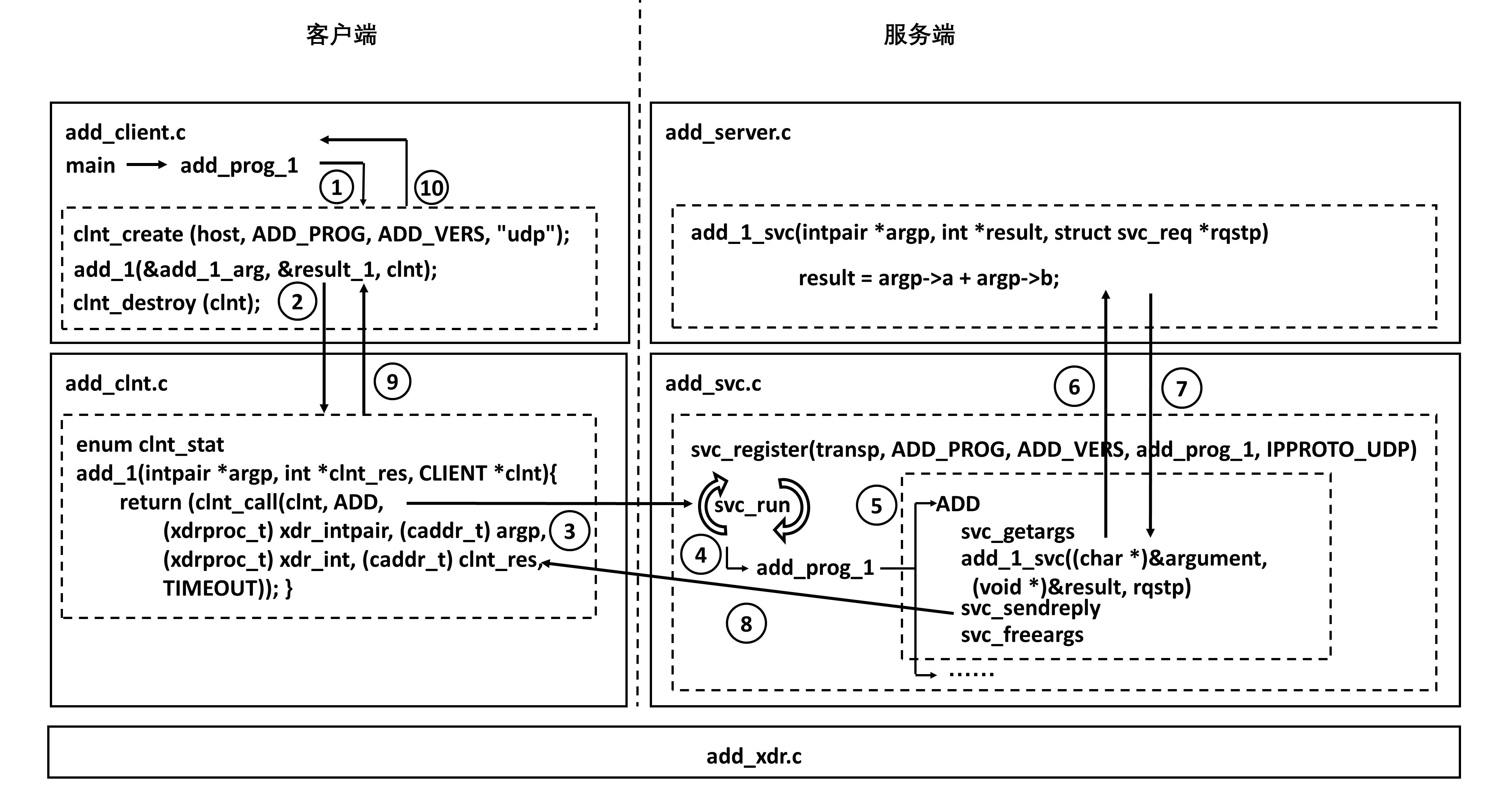
最下层的是XDR文件,用于编码和解码参数。这个文件是客户端和服务端共享的,因为只有双方一致才能成功通信。
在客户端,会调用 clnt_create 创建一个连接,然后调用 add_1,这是一个 Stub 函数,感觉是在调用本地一样。其实是这个函数发起了一个 RPC 调用,通过调用 clnt_call 来调用 ONC RPC 的类库,来真正发送请求。
当然服务端也有一个 Stub 程序,监听客户端的请求,当调用到达的时候,判断如果是 add,则调用真正的服务端逻辑,也即将两个数加起来。
服务端将结果返回服务端的 Stub,这个 Stub 程序发送结果给客户端,客户端的 Stub 程序正在等待结果,当结果到达客户端 Stub,就将结果返回给客户端的应用程序,从而完成整个调用过程。
1.4 传输问题
传输问题主要解决错误,重传,丢包,性能的问题,这些不是Stub来解决的,而是由One RPC类库来实现。
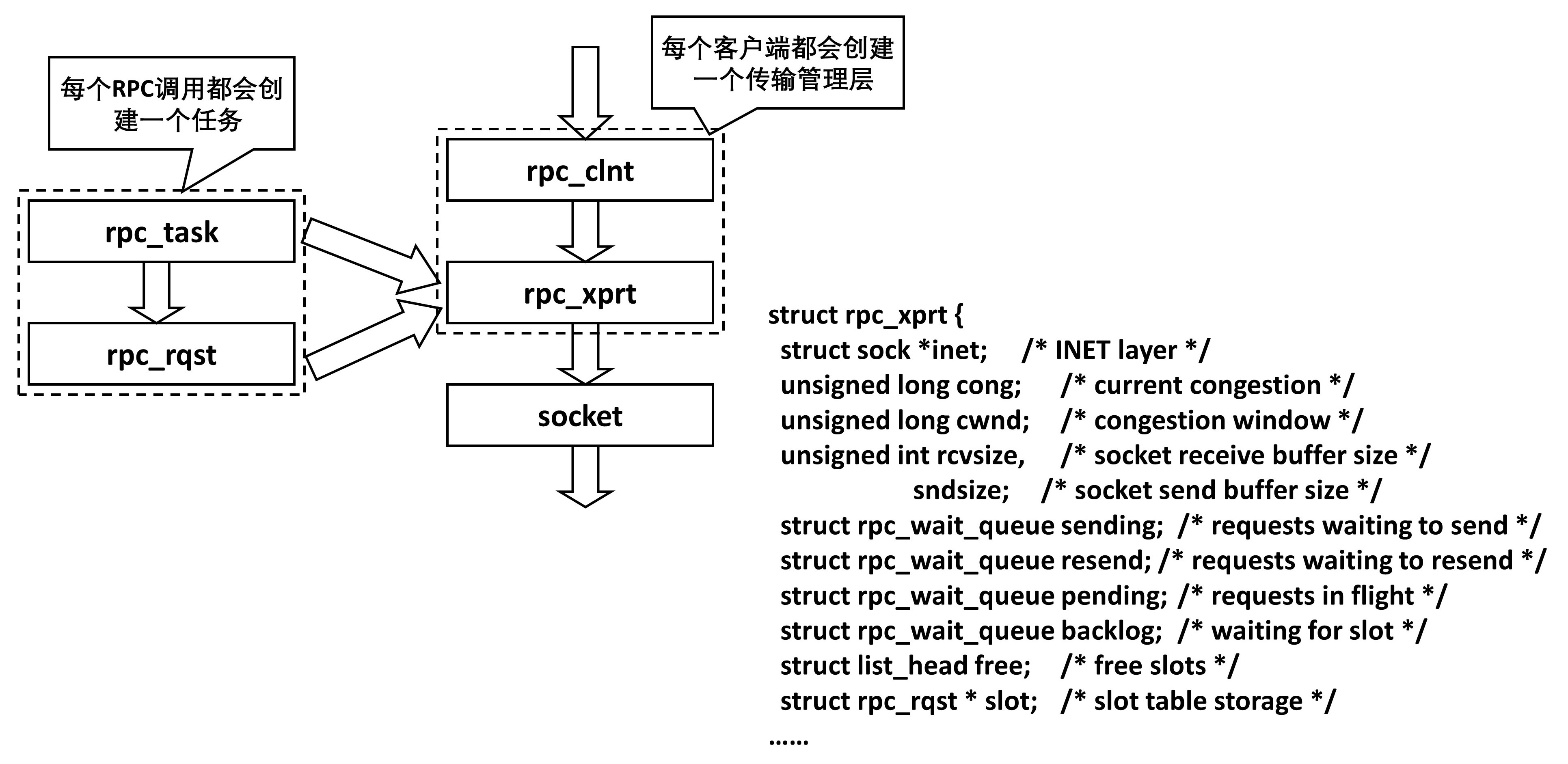
在这个类库中,为了解决传输问题,对于每一个客户端,都会创建一个传输管理层,而每一次RPC调用,都会是一个任务,在传输管理层会有队列机制、拥塞控制机制等等。
由于在网络传输的时候,经常需要等待,因而同步的方式往往效率比较低,因而也就有 Socket 的异步模型。为了能够异步处理,对于远程调用的处理,往往是通过状态机来实现的。只有当满足某个状态的时候,才进行下一步,如果不满足状态,不是在那里等,而是将资源留出来,用来处理其他的 RPC 调用。
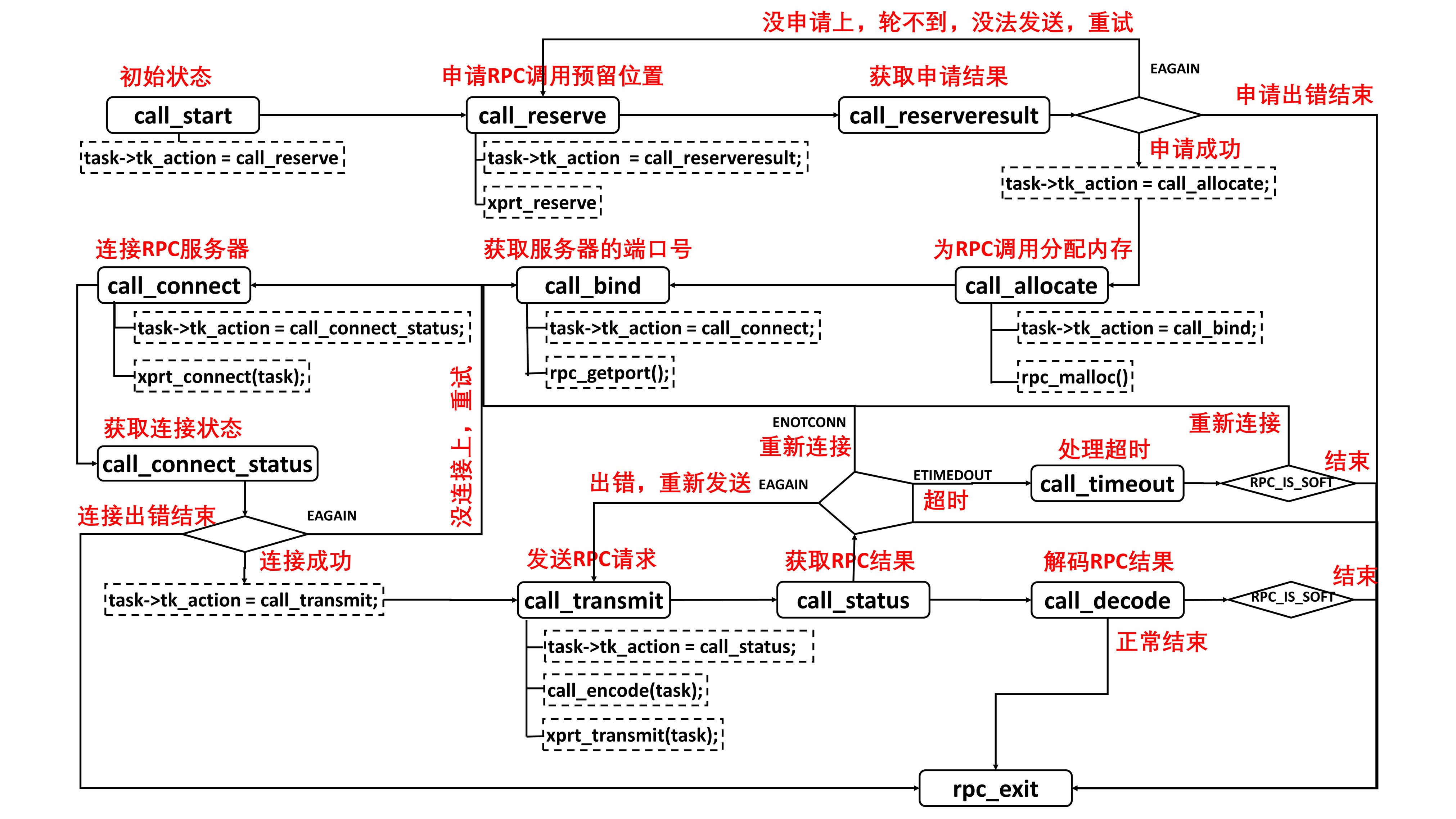
首先,进入起始状态,查看 RPC 的传输层队列中有没有空闲的位置,可以处理新的 RPC 任务。如果没有,说明太忙了,或直接结束或重试。如果申请成功,就可以分配内存,获取服务的端口号,然后连接服务器。
连接的过程要有一段时间,因而要等待连接的结果,会有连接失败,或直接结束或重试。如果连接成功,则开始发送 RPC 请求,然后等待获取 RPC 结果,这个过程也需要一定的时间;如果发送出错,可以重新发送;如果连接断了,可以重新连接;如果超时,可以重新传输;如果获取到结果,就可以解码,正常结束。
1.5 服务发现问题
如何找到RPC服务端的随机端口,在Onc RPC中,服务发现是通过portmapper实现的

portmapper 会启动在一个众所周知的端口上,RPC 程序由于是用户自己写的,会监听在一个随机端口上,但是 RPC 程序启动的时候,会向 portmapper 注册。客户端要访问 RPC 服务端这个程序的时候,首先查询 portmapper,获取 RPC 服务端程序的随机端口,然后向这个随机端口建立连接,开始 RPC 调用。从图中可以看出,mount 命令的 RPC 调用,就是这样实现的。
2. 基于XML的SOAP协议
上述的ONC RPC协议还存在一些问题:
- 需要双方的压缩格式完全一致
- 协议修改不灵活
- 版本问题
即还是很难在客户端和服务端之间进行开发。
2.1 XML & SOAP
要让所有不同的人都能看懂我们的信息,那么我们就需要用文本类的方式进行传输,无论哪个客户端获得这个文本,都能够知道它的意义。
2.2 传输协议问题
基于XML的最著名的通信协议就是SOAP了(Simple Object Access Protocol)-简单对象访问协议。使用XML编写简单的请求和回复消息,并用HTTP协议进行传输。
SOAP将请求和回复放在一个信封里,就像传递邮件一样,有抬头与正文的区别。
POST /purchaseOrder HTTP/1.1
Host: www.baidu.com
Content-Type: application/soap+xml; charset=utf-8
Content-Length: nnn
<?xml version="1.0"?>
<soap:Envelope xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Header>
<m:Trans xmlns:m="http://www.w3schools.com/transaction/"
soap:mustUnderstand="1">1234
</m:Trans>
</soap:Header>
<soap:Body xmlns:m="http://www.baidu.com/perchaseOrder">
<m:purchaseOrder">
<order>
<date>2018-07-01</date>
<className> RPC & SOAP </className>
<Author> LLCHEN </Author>
</order>
</m:purchaseOrder>
</soap:Body>
</soap:Envelope>这个请求使用POST方法,发送一个格式为application/soap + xml的XML正文给www.baidu.com,从而下一个单,这个订单封装在SOAP的信封里。
2.3 协议约定问题
因为服务开发出来是给陌生人用的,就像上面下单的那个 XML 文件,对于客户端来说,它如何知道应该拼装成上面的格式呢?这就需要对于服务进行描述,因为调用的人不认识你,所以没办法找到你,问你的服务应该如何调用。
当然你可以写文档,然后放在官方网站上,但是你的文档不一定更新得那么及时,而且你也写的文档也不一定那么严谨,所以常常会有调试不成功的情况。因而,我们需要一种相对比较严谨的Web服务描述语言, WSDL(Web Service Description Languages)
在这个文件里,要定义一个类型的order,与上面的XML对应起来。
<wsdl:types>
<xsd:schema targetNamespace="http://www.example.org/geektime">
<xsd:complexType name="order">
<xsd:element name="date" type="xsd:string"></xsd:element>
<xsd:element name="className" type="xsd:string"></xsd:element>
<xsd:element name="Author" type="xsd:string"></xsd:element>
<xsd:element name="price" type="xsd:int"></xsd:element>
</xsd:complexType>
</xsd:schema>
</wsdl:types>定义一个message结构
<wsdl:message name="purchase">
<wsdl:part name="purchaseOrder" element="tns:order"></wsdl:part>
</wsdl:message>暴露一个端口
<wsdl:portType name="PurchaseOrderService">
<wsdl:operation name="purchase">
<wsdl:input message="tns:purchase"></wsdl:input>
<wsdl:output message="......"></wsdl:output>
</wsdl:operation>
</wsdl:portType>编写一个binding,将上面定义的信息绑定到SOAP请求的body里面
<wsdl:binding name="purchaseOrderServiceSOAP" type="tns:PurchaseOrderService">
<soap:binding style="rpc"
transport="http://schemas.xmlsoap.org/soap/http" />
<wsdl:operation name="purchase">
<wsdl:input>
<soap:body use="literal" />
</wsdl:input>
<wsdl:output>
<soap:body use="literal" />
</wsdl:output>
</wsdl:operation>
</wsdl:binding>对应的Service:
<wsdl:service name="PurchaseOrderServiceImplService">
<wsdl:port binding="tns:purchaseOrderServiceSOAP" name="PurchaseOrderServiceImplPort">
<soap:address location="http://www.geektime.com:8080/purchaseOrder" />
</wsdl:port>
</wsdl:service>2.4 服务发现问题
采用UDDI协议(Universal Description, Discovery, and Integration),即统一描述、发现和继承协议。它其实是一个注册中心,服务提供方可以将上面的 WSDL 描述文件,发布到这个注册中心,注册完毕后,服务使用方可以查找到服务的描述,封装为本地的客户端进行调用。
3. 基于JSON的RESTful接口协议
3.1 RESTful
然而 RESTful 可不仅仅是指 API,而是一种架构风格,全称 Representational State Transfer,表述性状态转移
3.2 协议约定问题
和 SOAP 不一样,REST 不是一种严格规定的标准,它其实是一种设计风格。如果按这种风格进行设计,RESTful 接口和 SOAP 接口都能做到,只不过后面的架构是 REST 倡导的,而 SOAP 相对比较关注前面的接口。
然而本地调用和远程跨网络调用毕竟不一样,这里的不一样还不仅仅是因为有网络而导致的客户端和服务端的分离,从而带来的网络性能问题。更重要的问题是,客户端和服务端谁来维护状态。所谓的状态就是对某个数据当前处理到什么程度了。
当有了 RPC 之后,我们本来期望对上层透明,就像上一节说的“远在天边,尽在眼前”。于是使用 RPC 的时候,对于状态的问题也没有太多的考虑。上面的例子都是在 RPC 场景下,由服务端来维护状态,很多 SOAP 接口设计的时候,也常常按这种模式。这种模式原来没有问题,是因为客户端和服务端之间的比例没有失衡。因为一般不会同时有太多的客户端同时连上来,所以 NFS 还能把每个客户端的状态都记住。
但是互联网场景下,客户端和服务端就彻底失衡了。你可以想象“双十一”,多少人同时来购物,作为服务端,它能记得过来吗?当然不可能,只好多个服务端同时提供服务,大家分担一下。但是这就存在一个问题,服务端怎么把自己记住的客户端状态告诉另一个服务端呢?或者说,你让我给你分担工作,你也要把工作的前因后果给我说清楚啊!
因此应该是服务端只记录资源的状态,而客户端自己维护自己的状态,比如已经访问到哪个目录了,哪一页等等这类信息。
当客户端维护了自己的状态的时候,就不需要这样调用服务端了。通过这种让客户端记录自己的状态的方式,我们可以实现服务端的无状态化,就可以让服务端来横向扩展了。
所谓的无状态,其实是服务端维护资源的状态,客户端维护会话的状态。对于服务端来讲,只有资源的状态改变了,客户端才调用 POST、PUT、DELETE 方法来找我;如果资源的状态没变,只是客户端的状态变了,就不用告诉我了,对于我来说都是统一的 GET。
虽然这只改进了 GET,但是已经带来了很大的进步。因为对于互联网应用,大多数是读多写少的。而且只要服务端的资源状态不变,就给了我们缓存的可能。例如可以将状态缓存到接入层,甚至缓存到 CDN 的边缘节点,这都是资源状态不变的好处。
按照这种思路,对于API的设计,就慢慢变成了以资源为核心,而不是以过程为核心了。也就是说服务端只需要客户端告诉它你需要什么资源就好了,具体的过程和动作就不需要知道了。
还是文件目录的例子。客户端应该访问哪个绝对路径,而非一个动作,我就要进入某个路径。再如,库存的调用,应该查看当前的库存数目,然后减去购买的数量,得到结果的库存数。这个时候应该设置为目标库存数(但是当前库存数要匹配),而非告知减去多少库存。
这种 API 的设计需要实现幂等,因为网络不稳定,就会经常出错,因而需要重试,但是一旦重试,就会存在幂等的问题,也就是同一个调用,多次调用的结果应该一样,不能一次支付调用,因为调用三次变成了支付三次。不能进入 cd a,做了三次,就变成了 cd a/a/a。也不能扣减库存,调用了三次,就扣减三次库存。
当然按照这种设计模式,无论 RESTful API 还是 SOAP API 都可以将架构实现成无状态的,面向资源的、幂等的、横向扩展的、可缓存的。
但SOAP的XML正文可以放任何动作,而RESTful基本描述的就是资源的状态,没法描述动作,能发出的动作只有CRUD。
3.3 服务发现问题
有个著名的基于 RESTful API 的跨系统调用框架叫 Spring Cloud。在 Spring Cloud 中有一个组件叫 Eureka。传说,阿基米德在洗澡时发现浮力原理,高兴得来不及穿上裤子,跑到街上大喊:“Eureka(我找到了)!”所以 Eureka 是用来实现注册中心的,负责维护注册的服务列表。
服务分服务提供方,它向 Eureka 做服务注册、续约和下线等操作,注册的主要数据包括服务名、机器 IP、端口号、域名等等。
另外一方是服务消费方,向 Eureka 获取服务提供方的注册信息。为了实现负载均衡和容错,服务提供方可以注册多个。
当消费方要调用服务的时候,会从注册中心读出多个服务来,那怎么调用呢?当然是 RESTful 方式了。
Spring Cloud 提供一个 RestTemplate 工具,用于将请求对象转换为 JSON,并发起 Rest 调用,RestTemplate 的调用也是分 POST、PUT、GET、 DELETE 的,当结果返回的时候,根据返回的 JSON 解析成对象。
4. 二进制类RPC协议
接入层设计,在CDN, DNS当中,对于静态资源或者动态资源静态化的部分都可以做缓存。但是对于下单,支付等交易场景,还是需要调用API。
对于微服务的架构,API需要一个API网关统一进行管理。实现方式有:用Nginx或者OpenResty结合Lua脚本。在Spring Cloud当中,用组件Zuul也可以。
4.1 数据中心内部是如何调用的?
API网关用来管理API,但是API的实现一般在Controller层进行实现,这一层对外提供API。因为是面向大规模互联网应用的,所以主流还是使用RESTful API。
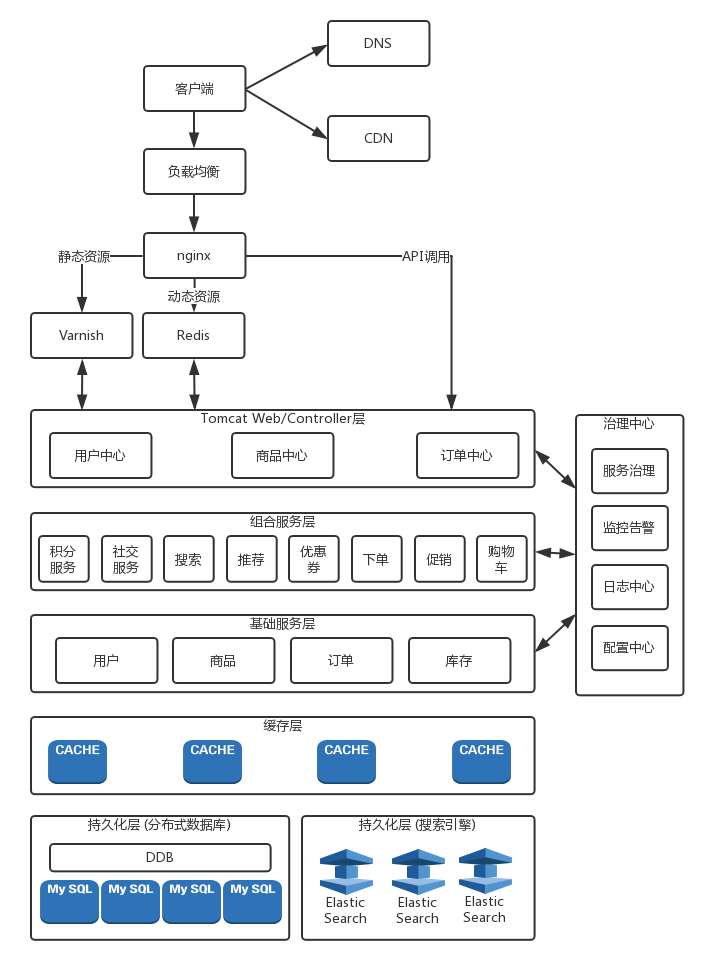
非常棒的分层图:
- 客户端进入的请求首先会进入负载均衡系统-nginx
- 静态资源先到Varnish找
- 动态资源去Redis找
- 2,3是负责整个页面的渲染
- 对于API调用,会到Controller层去解决,这里主要是处理各种业务逻辑的
- Controller层下方会有细化的基础服务层
- 缓存层
- 持久化层(分布式数据库+搜索引擎)
在Controller之内,就是互联网应用的业务逻辑实现了。业务逻辑的实现最好是无状态的,从而可以横向扩展,但是资源的状态还是需要服务端来维护的。资源的状态不应该维护在业务逻辑层,而是在最底层的持久化层,一般会使用分布式数据库和Elastic Search.
这些服务端的状态,例如订单、库存、商品等,都是重中之重,都需要持久化到硬盘上,数据不能丢,但是由于硬盘读写性能差,因而持久化层往往吞吐量不能达到互联网应用要求的吞吐量,因而前面要有一层缓存层,使用 Redis 或者 memcached 将请求拦截一道,不能让所有的请求都进入数据库“中军大营”。
缓存和持久化层之上一般是基础服务层,这里面提供一些原子化的接口。例如,对于用户、商品、订单、库存的增删查改,将缓存和数据库对再上层的业务逻辑屏蔽一道。有了这一层,上层业务逻辑看到的都是接口,而不会调用数据库和缓存。因而对于缓存层的扩容,数据库的分库分表,所有的改变,都截止到这一层,这样有利于将来对于缓存和数据库的运维。
再上面就是组合层。因为基础服务层只是提供简单的接口,实现简单的业务逻辑,而复杂的业务逻辑,比如下单,要扣优惠券,扣减库存等,就要在组合服务层实现。
这样,Controller 层、组合服务层、基础服务层就会相互调用,这个调用是在数据中心内部的,量也会比较大,还是使用 RPC 的机制实现的。
由于服务比较多,需要一个单独的注册中心来做服务发现。服务提供方会将自己提供哪些服务注册到注册中心中去,同时服务消费方订阅这个服务,从而可以对这个服务进行调用。
调用的时候有一个问题,这里的 RPC 调用,应该用二进制还是文本类?其实文本的最大问题是,占用字节数目比较多。比如数字 123,其实本来二进制 8 位就够了,但是如果变成文本,就成了字符串 123。如果是 UTF-8 编码的话,就是三个字节;如果是 UTF-16,就是六个字节。同样的信息,要多费好多的空间,传输起来也更加占带宽,时延也高。因而对于数据中心内部的相互调用,很多公司选型的时候,还是希望采用更加省空间和带宽的二进制的方案。
4.2 Dubbo服务化框架二进制的RPC方式
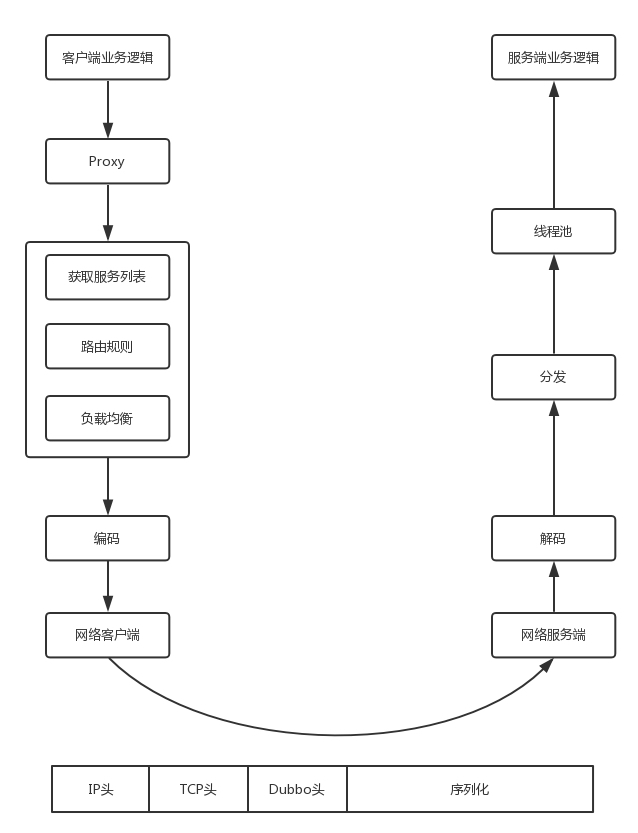
Dubbo 会在客户端的本地启动一个 Proxy,其实就是客户端的 Stub,对于远程的调用都通过这个 Stub 进行封装。
接下来,Dubbo 会从注册中心获取服务端的列表,根据路由规则和负载均衡规则,在多个服务端中选择一个最合适的服务端进行调用。
调用服务端的时候,首先要进行编码和序列化,形成 Dubbo 头和序列化的方法和参数。将编码好的数据,交给网络客户端进行发送,网络服务端收到消息后,进行解码。然后将任务分发给某个线程进行处理,在线程中会调用服务端的代码逻辑,然后返回结果。
4.3 如何解决协议约定问题?
Dubbo 中默认的 RPC 协议是 Hessian2。为了保证传输的效率,Hessian2 将远程调用序列化为二进制进行传输,并且可以进行一定的压缩。这个时候你可能会疑惑,同为二进制的序列化协议,Hessian2 和前面的二进制的 RPC 有什么区别呢?Hessian2 是解决了一些问题的。例如,原来要定义一个协议文件,然后通过这个文件生成客户端和服务端的 Stub,才能进行相互调用,这样使得修改就会不方便。Hessian2 不需要定义这个协议文件,而是自描述的。什么是自描述呢?
所谓自描述就是,关于调用哪个函数,参数是什么,另一方不需要拿到某个协议文件、拿到二进制,靠它本身根据 Hessian2 的规则,就能解析出来。
4.4 如何解决RPC传输问题?
Dubbo使用了Netty的网络传输框架。
Netty是一个非阻塞的基于事件的网络传输框架,在服务端启动的时候,会监听一个端口,并注册以下事件:
- 连接事件 - 当收到客户端的连接事件时,会调用void connected(Channel channel)方法
- 当可写事件触发时,会调用void sent(Channel channel, Object message),服务端向客户端返回响应数据
- 当可读事件触发时,会调用 void received(Channel channel, Object message) ,服务端在收到客户端的请求数据。
- 当发生异常时,会调用 void caught(Channel channel, Throwable exception)。
当事件触发之后,服务端在这些函数中的逻辑,可以选择直接在这个函数里面进行操作,还是将请求分发到线程池去处理。一般异步的数据读写都需要另外的线程池参与,在线程池中会调用真正的服务端业务代码逻辑,返回结果
到这里,我们说了数据中心里面的相互调用。为了高性能,大家都愿意用二进制,但是为什么后期 Spring Cloud 又兴起了呢?这是因为,并发量越来越大,已经到了微服务的阶段。同原来的 SOA 不同,微服务粒度更细,模块之间的关系更加复杂。
在上面的架构中,如果使用二进制的方式进行序列化,虽然不用协议文件来生成 Stub,但是对于接口的定义,以及传的对象 DTO,还是需要共享 JAR。因为只有客户端和服务端都有这个 JAR,才能成功地序列化和反序列化。
但当关系复杂的时候,JAR 的依赖也变得异常复杂,难以维护,而且如果在 DTO 里加一个字段,双方的 JAR 没有匹配好,也会导致序列化不成功,而且还有可能循环依赖。这个时候,一般有两种选择。
- 建立严格的项目管理流程
- 不允许循环调用,不允许跨层调用,只准上层调用下层,不允许下层调用上层。
- 接口要保持兼容性,不兼容的接口新添加而非改原来的,当接口通过监控,发现不用的时候,再下掉。
- 升级的时候,先升级服务提供端,再升级服务消费端。
- 改用RESTful方式
- 使用 Spring Cloud,消费端和提供端不用共享 JAR,各声明各的,只要能变成 JSON 就行,而且 JSON 也是比较灵活的。
- 使用 RESTful 的方式,性能会降低,所以需要通过横向扩展来抵消单机的性能损耗。
5. 跨语言类RPC协议
通过学习,我们知道,二进制的传输性能好,文本类的传输性能差一些;二进制的难以跨语言,文本类的可以跨语言;要写协议文件的严谨一些,不写协议文件的灵活一些。虽然都有服务发现机制,有的可以进行服务治理,有的则没有。
RPC从最初的客户端服务器的模式,最终演化到微服务。对于RPC框架的要求也开始逐渐变多,要求如下:
- 传输性能很重要,因为服务之间的调用太过频繁,还是二进制的越快越好
- 跨语言很重要,因为服务多了,什么语言写成的都有,而且不同的场景适宜用不同的语言,不能一个语言走到底。
- 最好既严谨又灵活,添加一个字段不需要重新编译和发布程序
- 最好既有服务发现,也有服务治理,就像Dubbo和Spring Cloud这样子。
5.1 gRPC协议
二进制传输,并且可以跨语言传输。因为语言不同,还压缩过了,所以双方必须搞一个协议约定文件,规定好双方沟通的专业术语,这样来让整个沟通更加顺畅。
对于 GRPC 来讲,二进制序列化协议是 Protocol Buffers。首先,需要定义一个协议文件.proto。
syntax = “proto3”;
package com.llchen60.grpc
option java_package = “com.llchen60.grpc”;
message Order {
required string date = 1;
required string classname = 2;
required string author = 3;
required int price = 4;
}
message OrderResponse {
required string message = 1;
}
service PurchaseOrder {
rpc Purchase (Order) returns (OrderResponse) {}
}在这个协议文件中,我们首先指定使用 proto3 的语法,然后我们使用** Protocol Buffers 的语法,定义两个消息的类型,一个是发出去的参数,一个是返回的结果。里面的每一个字段,例如 date、classname、author、price 都有唯一的一个数字标识**,这样在压缩的时候,就不用传输字段名称了,只传输这个数字标识就行了,能节省很多空间。
最后定义一个Service,里面会有一个RPC调用的声明,无论使用什么语言,都有相应的工具生成客户端和服务端的Stub程序,这样客户端就可以像调用本地一样,调用远程的服务了。
5.2 协议约定问题
Protocol Buffers,是一个有着很高的压缩效率的序列化协议。对于 int 类型 32 位的,一般都需要 4 个 Byte 进行存储。在 Protocol Buffers 中,使用的是变长整数的形式。对于每一个 Byte 的 8 位,最高位都有特殊的含义。如果该位为 1,表示这个数字没完,后续的 Byte 也属于这个数字;如果该位为 0,则这个数字到此结束。其他的 7 个 Bit 才是用来表示数字的内容。因此,小于 128 的数字都可以用一个 Byte 表示;大于 128 的数字,比如 130,会用两个字节来表示。对于每一个字段,使用的是 TLV(Tag,Length,Value)的存储办法。其中 Tag = (field_num << 3) | wire_type。field_num 就是在 proto 文件中,给每个字段指定唯一的数字标识,而 wire_type 用于标识后面的数据类型。

在灵活性方面,这种基于协议文件的二进制压缩协议往往存在更新不方便的问题。例如,客户端和服务器因为需求的改变需要添加或者删除字段。这一点上,Protocol Buffers考虑了兼容性,在上面的协议文件当中,每一个字段都有修饰符,比如:
- required
- optional
- repeated
如果我们想修改协议文件,对于赋给某个标签的数字,例如 string author=3,这个就不要改变了,改变了就不认了;也不要添加或者删除 required 字段,因为解析的时候,发现没有这个字段就会报错。对于 optional 和 repeated 字段,可以删除,也可以添加。这就给了客户端和服务端升级的可能性。
5.3 网络传输问题
假设是Java技术栈,那么gRPC的客户端和服务器之间通过Netty Channel作为数据通道,每个请求都被封装成HTTP2.0的Stream当中。
Netty是一个搞笑的基于异步IO的网络传输框架,
HTTP2.0还将所有的传输信息分割为更小的消息和帧,并对它们采用二进制格式编码。
通过这两种机制,HTTP 2.0 的客户端可以将多个请求分到不同的流中,然后将请求内容拆成帧,进行二进制传输。这些帧可以打散乱序发送, 然后根据每个帧首部的流标识符重新组装,并且可以根据优先级,决定优先处理哪个流的数据。
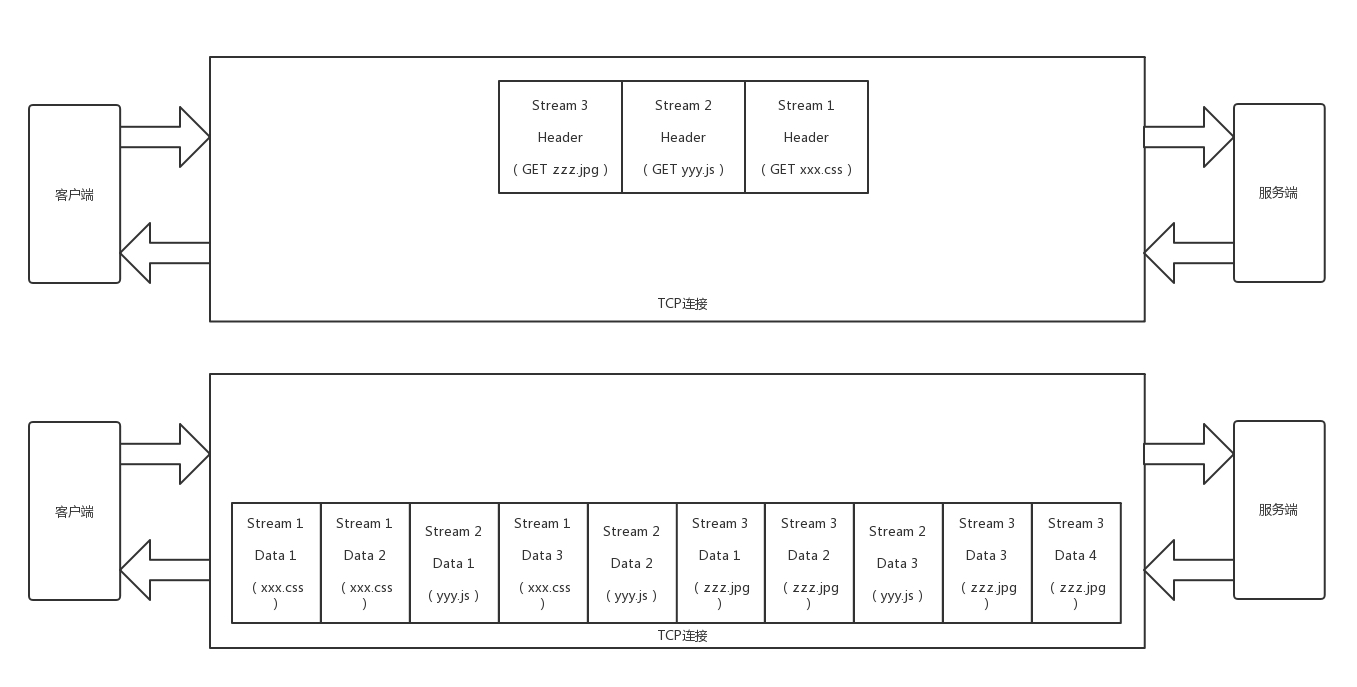
由于基于HTTP2.0,gRPC和其他的RPC不同,可以定义四种服务方法。
5.3.1 单向RPC
客户端发送一个请求给服务端,从服务端获取一个应答,就像普通的一次函数调用一样。
rpc SayHello(HelloRequest) returns (HelloResponse){}5.3.2 服务端流式RPC
服务端返回的不是一个结果,而是一批。客户端发送一个请求给服务端,可获取一个数据流用来读取一系列信息。客户端从返回的数据流里一直读取,直到没有更多的消息为止。
rpc LotsOfReplies(HelloRequest) returns (stream HelloResponse){}5.3.3 客户端流式RPC
客户端的请求不是一个,而是一批,客户端用提供的一个数据流写入并发送一系列消息给服务端。一旦客户端完成消息写入,就等待服务端读取这些消息并返回应答。
rpc LotsOfGreetings(stream HelloRequest) returns (HelloResponse) {}5.3.4 双向流式RPC
即两边都可以分别通过一个读写数据流来发送一系列消息。这两个数据流操作是相互独立的,所以客户端和服务端能按其希望的任意顺序读写,服务端可以在写应答前等待所有的客户端消息,或者它可以先读一个消息再写一个消息,或者读写相结合的其他方式。每个数据流里消息的顺序会被保持。
rpc BidiHello(stream HelloRequest) returns (stream HelloResponse){}如果基于 HTTP 2.0,客户端和服务器之间的交互方式要丰富得多,不仅可以单方向远程调用,还可以实现当服务端状态改变的时候,主动通知客户端。
5.4 服务发现与治理问题
gRPC本身没有提供服务发现的机制,需要借助其他的组件,发现要访问的服务端,在多个服务端之间进行容错和负载均衡。
这个地方的重点问题在于如何发现服务端,并根据服务端的变化,动态修改负载均衡器的配置。
5.4.1 Envoy配置
在这里我们介绍一种对于 GRPC 支持比较好的负载均衡器 Envoy。其实 Envoy 不仅仅是负载均衡器,它还是一个高性能的 C++ 写的 Proxy 转发器,可以配置非常灵活的转发规则。
这些规则可以是静态的,放在配置文件中的,在启动的时候加载。要想重新加载,一般需要重新启动,但是 Envoy 支持热加载和热重启,这在一定程度上缓解了这个问题。
当然,最好的方式是将规则设置为动态的,放在统一的地方维护。这个统一的地方在 Envoy 眼中被称为服务发现(Discovery Service),过一段时间去这里拿一下配置,就修改了转发策略。
无论是静态的,还是动态的,在配置里面往往会配置四个东西:
- listener: Envoy既然是Proxy,专门做转发,就得监听一个端口,接入请求,然后才能根据策略转发,这个监听的端口就称为listener.
- endpoint: 是目标的IP地址和端口。这个是proxy最终将请求转发到的地方。
- cluster: 一个cluster是具有完全相同行为的多个endpoint,即如果有三个服务端在运行,就会有三个IP和端口,但是部署的是完全相同的三个服务,它们组成了一个cluster,从cluster到endpoint的过程称为负载均衡,可以轮询。
- route: 有时候多个cluster具有类似的功能,但是是不同的版本,可以通过route规则,选择将请求路由到某一个版本号当中,就到了对应的cluster里面。
如果是静态的,则将后端的服务端的 IP 地址拿到,然后放在配置文件里面就可以了。
如果是动态的,就需要配置一个服务发现中心,这个服务发现中心要实现 Envoy 的 API,Envoy 可以主动去服务发现中心拉取转发策略。
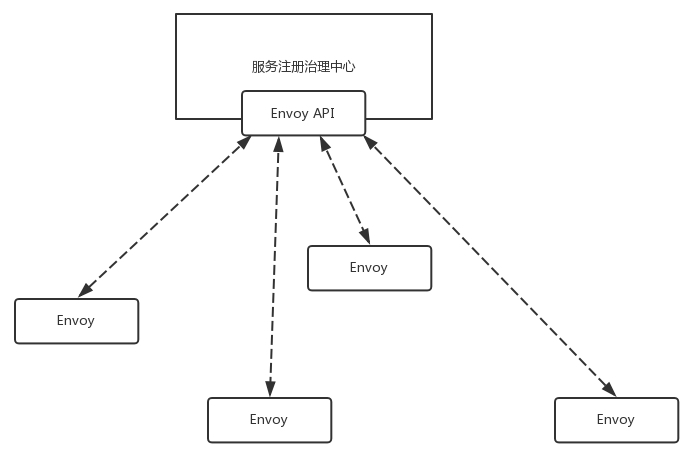
看来,Envoy 进程和服务发现中心之间要经常相互通信,互相推送数据,所以 Envoy 在控制面和服务发现中心沟通的时候,就可以使用 GRPC,也就天然具备在用户面支撑 GRPC 的能力。
5.4.2 Envoy 功能
- 配置路由策略
例如后端的服务有两个版本,可以通过配置 Envoy 的 route,来设置两个版本之间,也即两个 cluster 之间的 route 规则,一个占 99% 的流量,一个占 1% 的流量。
- 负载均衡策略
对于一个 cluster 下的多个endpoint,可以配置负载均衡机制和健康检查机制,当服务端新增了一个,或者挂了一个,都能够及时配置 Envoy,进行负载均衡。
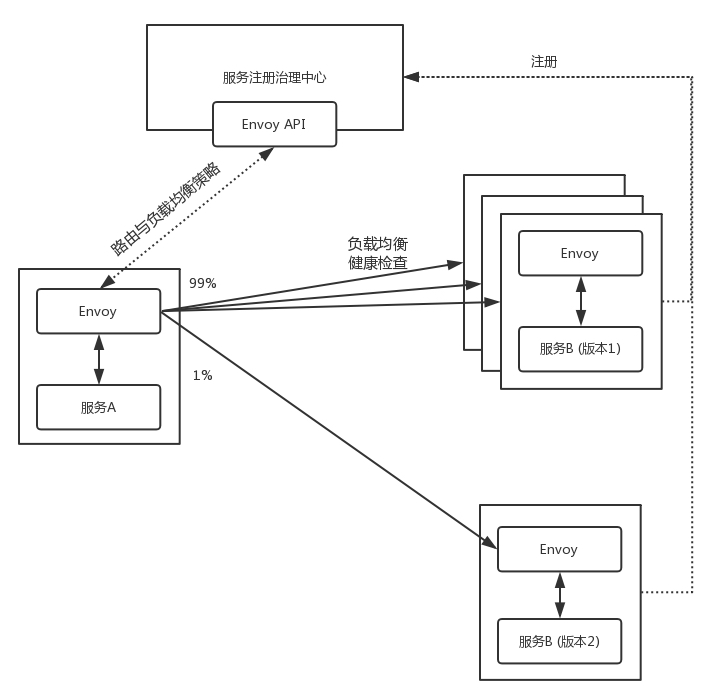
所有这些节点的变化都会上传到注册中心,所有这些策略都可以通过注册中心进行下发,所以,更严格的意义上讲,注册中心可以称为注册治理中心。
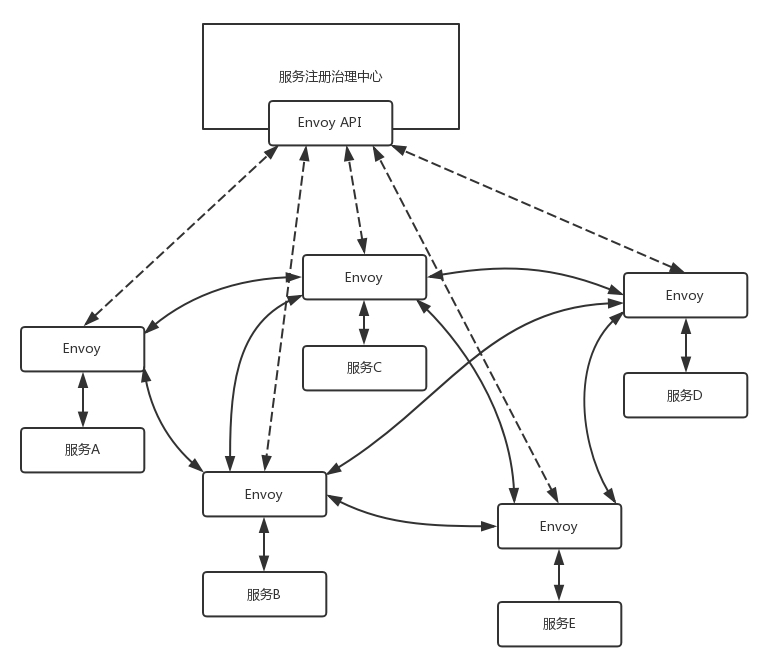
Envoy 这么牛,是不是能够将服务之间的相互调用全部由它代理?如果这样,服务也不用像 Dubbo,或者 Spring Cloud 一样,自己感知到注册中心,自己注册,自己治理,对应用干预比较大。
如果我们的应用能够意识不到服务治理的存在,就是直接进行 GRPC 的调用就可以了。
这就是未来服务治理的趋势Service Mesh,即应用之间的相互调用全部由Envoy进行代理,服务之间的治理也被Envoy进行代理,完全将服务治理抽象出来,到平台层解决。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:网络协议(十) - RPC, SOAP, RESTful
文章字数:9.6k
本文作者:Leilei Chen
发布时间:2020-02-02, 13:53:34
最后更新:2020-02-02, 14:06:58
原始链接:https://www.llchen60.com/%E7%BD%91%E7%BB%9C%E5%8D%8F%E8%AE%AE-%E5%8D%81-RPC-SOAP-RESTful/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

