数据结构与算法(9)-排序(归并 快排)
这节主要讲归并排序和快速排序,二者其实都用了分治的思想,可以借鉴这个思想,来解决诸如“如何在O(n)的时间复杂度内查找一个无序数组中的第k大元素”这样的问题。
1. 归并排序
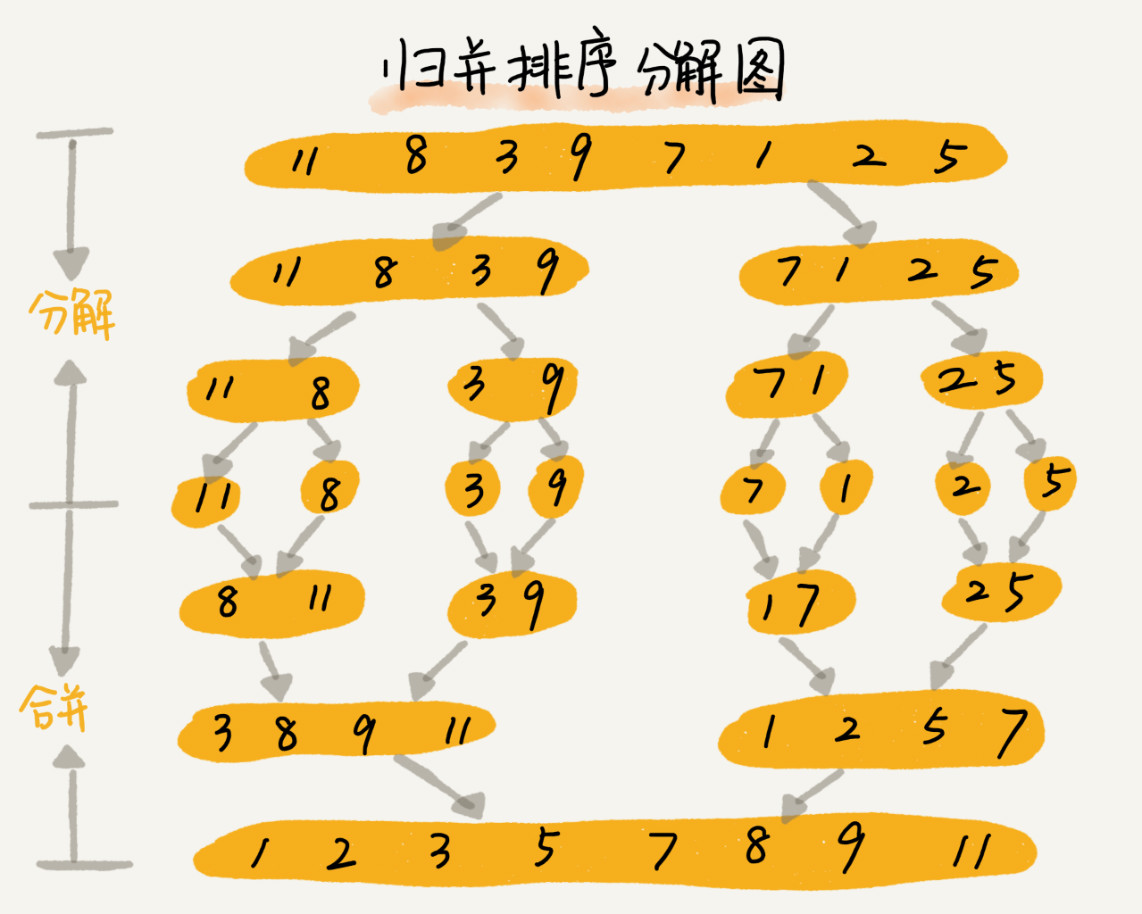
归并排序
- 分治思想
- 分治是一种解决问题的处理思想,递归是一种编程技巧
- 和递归的三要素很类似,先分析得出递推公式,然后找到终止条件,再将递推公式翻译成递归代码。
注意是分成了分开和合并两个过程的,在合并的过程当中,需要遍历两个有序子集,相互比较大小,然后放置在另外一个空间当中
递推公式:
merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
终止条件:
p >= r 不用再继续分解
// 归并排序算法, A 是数组,n 表示数组大小
merge_sort(A, n) {
merge_sort_c(A, 0, n-1)
}
// 递归调用函数
merge_sort_c(A, p, r) {
// 递归终止条件
if p >= r then return
// 取 p 到 r 之间的中间位置 q
q = (p+r) / 2
// 分治递归
merge_sort_c(A, p, q)
merge_sort_c(A, q+1, r)
// 将 A[p...q] 和 A[q+1...r] 合并为 A[p...r]
merge(A[p...r], A[p...q], A[q+1...r])
}- 稳定排序
- 时间复杂度为O(nlog(n))
- 需要借助额外空间,不是原地排序算法 空间复杂度 O(n) 每次搞完就会直接释放掉了
2. 快速排序
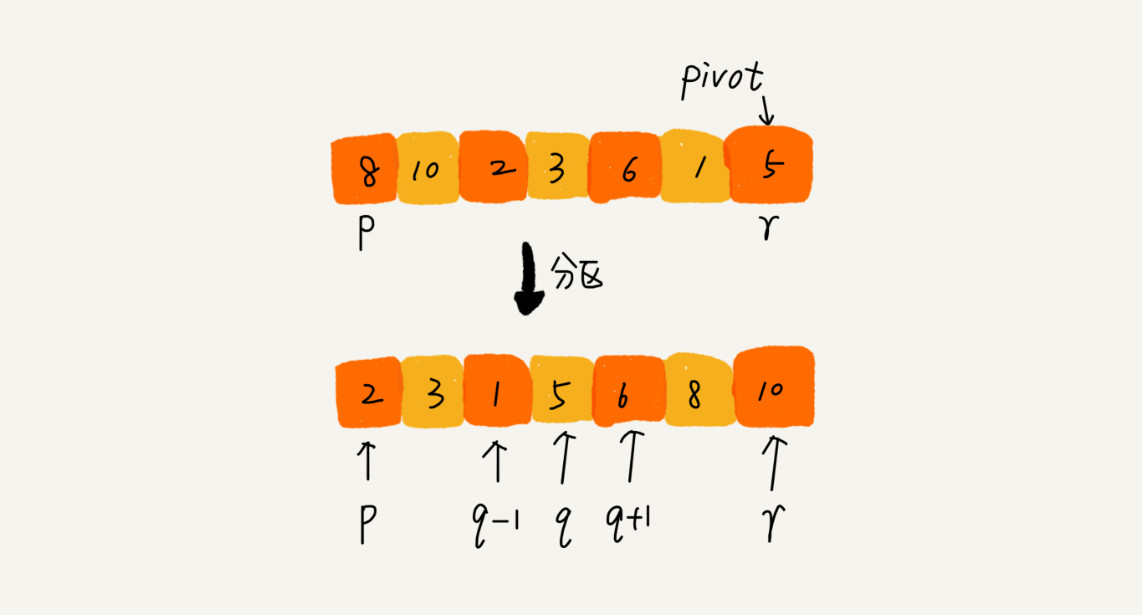
- 快排的思想
- 如果要排序数组中下标从p到r之间的一组数据,我们选择p到r之间的任意一个数据作为pivot(分区点)
- 我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
- 快速排序是一种不稳定的排序方法,因为要实现swap
递推公式:
quick_sort(p…r) = quick_sort(p…q-1) + quick_sort(q+1, r)
终止条件:
p >= r
// 快速排序,A 是数组,n 表示数组的大小
quick_sort(A, n) {
quick_sort_c(A, 0, n-1)
}
// 快速排序递归函数,p,r 为下标
quick_sort_c(A, p, r) {
if p >= r then return
q = partition(A, p, r) // 获取分区点
quick_sort_c(A, p, q-1)
quick_sort_c(A, q+1, r)
}转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:数据结构与算法(9)-排序(归并 快排)
文章字数:634
本文作者:Leilei Chen
发布时间:2020-02-10, 01:51:41
最后更新:2020-02-10, 01:55:54
原始链接:https://www.llchen60.com/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%B8%8E%E7%AE%97%E6%B3%95-9-%E6%8E%92%E5%BA%8F-%E5%BD%92%E5%B9%B6-%E5%BF%AB%E6%8E%92/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

