数据结构与算法(11)-应用场景下的排序函数
在日常开发当中,无论我们使用的语言是什么,他们几乎都会提供排序算法,本篇博文将尝试着对其进行分析,看看如何实现一个通用的,高性能的排序算法。
首先看看我们的现有排序算法库,看看我们的选择空间在哪里:
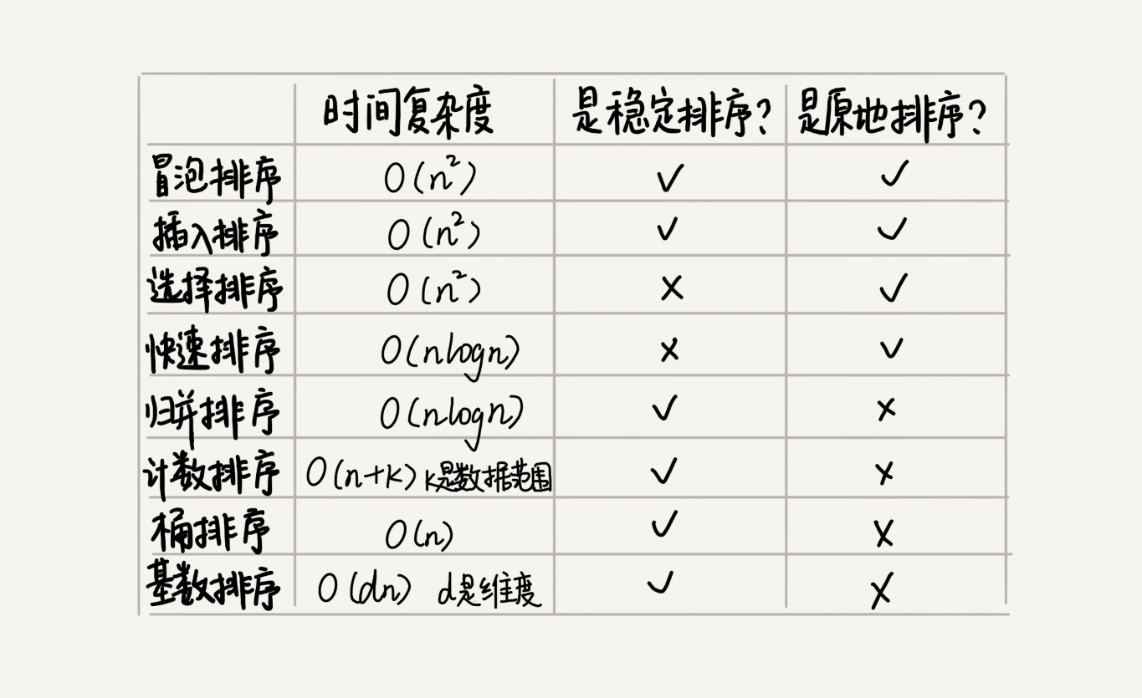
如果对于小规模数据排序,可以选择O(n^2); 但是对于大规模的数据,时间复杂度为O(nlogn)的算法会高效很多。因此为了兼顾任意规模数据的排序,一般都会首选时间复杂度为O(nlogn)的排序算法来实现排序函数。
一般来说会选用堆排序或者快速排序来做。
因为在实际情况下内存的占用情况是非常关键的参数了,所以我们需要看待选算法的空间复杂度,最好是原地的,即不占用更多的空间。像归并排序,时间复杂度很合适但是空间复杂度为O(n),那就完全不是一个好选择了
快速排序想要优化的话,主要的点在于要选准分区点,好的分区点是希望其两个分区数据的数量是差不多的才可以。我们可以随机取值,也可以多取几个随机点,然后求平均。
还有一点需要注意的是在实际情况当中, O(n^2)有可能会比O(nlogn)要快的,因为小规模数据集的时候首先常量就不能忽略掉了。在这种情况下,可能插入排序反而会更快。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:数据结构与算法(11)-应用场景下的排序函数
文章字数:424
本文作者:Leilei Chen
发布时间:2020-02-10, 02:00:04
最后更新:2020-02-10, 02:00:58
原始链接:https://www.llchen60.com/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%B8%8E%E7%AE%97%E6%B3%95-11-%E5%BA%94%E7%94%A8%E5%9C%BA%E6%99%AF%E4%B8%8B%E7%9A%84%E6%8E%92%E5%BA%8F%E5%87%BD%E6%95%B0/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

