序列化和反序列化
序列化和反序列化
1. 定义
序列化
- 将对象转化为可传输的字节序列的过程
- 是属于TCP/ IP协议应用层的一部分
- 常用的你可能看到的名字
- serialization
- marshalling
- flatteing
- 常见序列化方式
- JSON
- XML
- 将对象转化为可传输的字节序列的过程
反序列化
- 将字节序列还原为对象的过程称为反序列化
二进制串
- 二进制串:序列化所生成的二进制串指的是存储在内存中的一块数据。
- C++语言具有内存操作符,所以二进制串的概念容易理解,例如,C++语言的字符串可以直接被传输层使用,因为其本质上就是以’\0’结尾的存储在内存中的二进制串。
- 在Java语言里面,二进制串的概念容易和String混淆。实际上String 是Java的一等公民,是一种特殊对象(Object)。对于跨语言间的通讯,序列化后的数据当然不能是某种语言的特殊数据类型。二进制串在Java里面所指的是byte[],byte是Java的8中原生数据类型之一(Primitive data types)
2. 为什么要序列化
- 为了使得对象可以跨平台进行存储,进行网络传输
- 本质上存储和网络传输都需要将一个对象状态保存成一种跨平台识别的字节格式,然后其他的平台才可以通过字节信息解析还原对象的信息
- 而且序列化后可以存在文件当中,永久性的存到硬盘上
3. 序列化技术选择的metrics
3.1 跨平台 & 跨语言
是否需要支持多种语言,应该选择没有语言局限性的序列化协议
- Json会是一个很好的选择,因为Json表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输
- JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面当中读取
3.2 性能
3.2.1 速度
如果序列化的频率非常高,那么选择序列化速度快的协议会为你的系统性能提升不少
3.2.3 序列化后的大小
数据量小对于网络的压力小,传输也会快,能够提升整体的性能
序列化需要在原有的数据上加上描述字段,以为反序列化解析之用。如果序列化过程引入的额外开销过高,可能会导致过大的网络,磁盘等各方面的压力。对于海量分布式存储系统,数据量往往以TB为单位,巨大的的额外空间开销意味着高昂的成本。
3.3 鲁棒性
从两方面来进行考虑
- 成熟度
- 一个协议从制定,实施到成熟是一个很漫长的阶段。协议的强健性依赖于大量而全面的测试。对于致力于提供高质量服务的系统,采用处于测试阶段的序列化协议会带来很高的风险。
- 语言/ 平台的公平性
- 当所支持的语言或者平台之间存在难以调和的特性的时候,协议制定者需要做权衡
- 做支持更多人使用的语言/平台 vs 为了支持更多的语言/ 平台而放弃某个特性
- 当所支持的语言或者平台之间存在难以调和的特性的时候,协议制定者需要做权衡
3.4 可调试性/ 可读性
- 序列化和反序列化的数据正确性和业务正确性的调试往往需要很长的时间,良好的调试机制会大大提高开发效率。
- 序列化后的二进制串往往不具备人眼可读性,为了验证序列化结果的正确性,写入方不得同时撰写反序列化程序,或提供一个查询平台–这比较费时;
- 另一方面,如果读取方未能成功实现反序列化,这将给问题查找带来了很大的挑战–难以定位是由于自身的反序列化程序的bug所导致还是由于写入方序列化后的错误数据所导致
3.5 可扩展性/ 兼容性
移动互联时代,业务系统需求的更新周期变得更快,新的需求不断涌现,而老的系统还是需要继续维护。如果序列化协议具有良好的可扩展性,支持自动增加新的业务字段,而不影响老的服务,这将大大提供系统的灵活度
3.6 安全性/ 访问限制
在序列化选型的过程中,安全性的考虑往往发生在跨局域网访问的场景。当通讯发生在公司之间或者跨机房的时候,出于安全的考虑,对于跨局域网的访问往往被限制为基于HTTP/HTTPS的80和443端口。如果使用的序列化协议没有兼容成熟的HTTP传输层框架支持,可能会导致以下三种结果之一:
第一、因为访问限制而降低服务可用性。
第二、被迫重新实现安全协议而导致实施成本大大提高。
第三、开放更多的防火墙端口和协议访问,而牺牲安全性。
4. 序列化和反序列化的组件
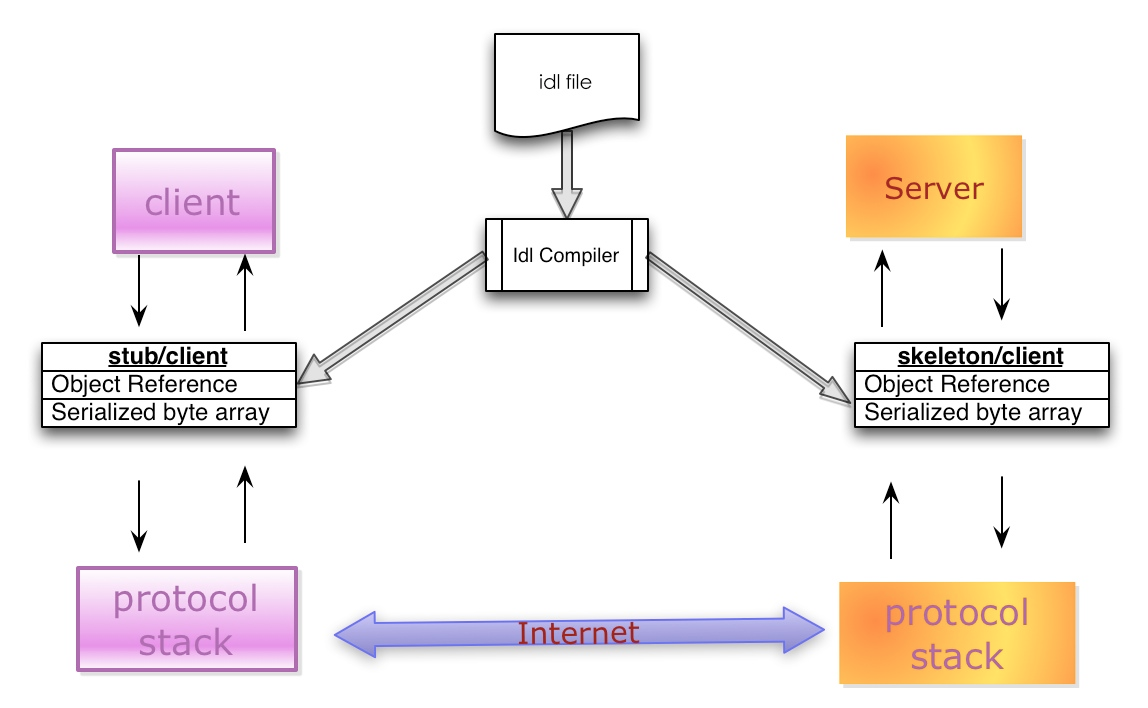
4.1 IDL — Interface Description Language
- 参与通讯的各方需要对通讯的内容做相关的约定 — specifications
- 这个约定需要和语言以及平台无关
- 被称为接口描述语言
4.2 IDL Compiler
- IDL文件中约定的内容为了在各个语言和平台可见,需要有一个编译器,将IDL文件转换成各个语言对应的动态库
4.3 Stub/ Skeleton Lib
- 负责序列化和反序列化的工作代码
- Stub是一段部署在分布式系统客户端的代码,一方面接收应用层的参数,并对其序列化后通过底层协议栈发送到服务端,另一方面接收服务端序列化后的结果数据,反序列化后交给客户端应用层;
- Skeleton部署在服务端,其功能与Stub相反,从传输层接收序列化参数,反序列化后交给服务端应用层,并将应用层的执行结果序列化后最终传送给客户端Stub。
5. 常见的序列化和反序列化协议
下面以这两个类的序列化反序列化为例
class Address
{
private String city;
private String postcode;
private String street;
}
public class UserInfo
{
private Integer userid;
private String name;
private List<Address> address;
}5.1 XML & SOAP
5.1.1 XML
- 特点
- 描述语言,self-describing
- XML自身可以被用于XML序列化的IDL
- 标准的XML描述格式有
- DTD - Document Type Definition
- XSD - XML Schema Definition
- 优点
- 跨机器,跨语言
- 可读性
- 因为其最初的目标是对互联网文档Document进行标记,所以其设计理念当中就包含了对于人和机器都具备可读性
- 缺点
- 冗长,复杂
5.1.2 SOAP - Simple Object Access Protocol
概念
- 基于XML为序列化和反序列化协议的结构化的消息传递协议
- SOAP支持多种传输层协议,最常见的使用方式是XML + HTTP
IDL
- SOAP协议的主要接口描述语言IDL是WSDL — Web Service Description Language
SOAP具有安全、可扩展、跨语言、跨平台并支持多种传输层协议。如果不考虑跨平台和跨语言的需求,XML的在某些语言里面具有非常简单易用的序列化使用方法,无需IDL文件和第三方编译器, 例如Java+XStream
自我描述和递归
SOAP是一种采用XML进行序列化和反序列化的协议,它的IDL是WSDL. 而WSDL的描述文件是XSD,而XSD自身是一种XML文件。 这里产生了一种有趣的在数学上称之为“递归”的问题,这种现象往往发生在一些具有自我属性(Self-description)的事物上
<xsd:complexType name='Address'> <xsd:attribute name='city' type='xsd:string' /> <xsd:attribute name='postcode' type='xsd:string' /> <xsd:attribute name='street' type='xsd:string' /> </xsd:complexType> <xsd:complexType name='UserInfo'> <xsd:sequence> <xsd:element name='address' type='tns:Address'/> <xsd:element name='address1' type='tns:Address'/> </xsd:sequence> <xsd:attribute name='userid' type='xsd:int' /> <xsd:attribute name='name' type='xsd:string' /> </xsd:complexType>
优点
- 安全性
- XML肉眼可读,可调试性好
缺点
- XML空间开销会大很多,序列化后的数据量剧增,这意味着巨大的内存和磁盘开销
适用场景
- 对于公司之间传输数据量小或者实时性要求相对低的服务是一个很好的选择
5.2 JSON - Javascript Object Notation
概念
- 出自Javascript,产生来自于Associative array的概念,本质是采用Attribute-value的方法来描述对象
优点
- 这种Associative array格式非常符合工程师对对象的理解。
- 它保持了XML的人眼可读(Human-readable)的优点。
- 相对于XML而言,序列化后的数据更加简洁。 来自于的以下链接的研究表明:XML所产生序列化之后文件的大小接近JSON的两倍。http://www.codeproject.com/Articles/604720/JSON-vs-XML-Some-hard-numbers-about-verbosity
- 它具备Javascript的先天性支持,所以被广泛应用于Web browser的应用常景中,是Ajax的事实标准协议。
- 与XML相比,其协议比较简单,解析速度比较快。
- 松散的Associative array使得其具有良好的可扩展性和兼容性。
应用场景
- 公司之间传输数据量相对小,实时性要求相对低(例如秒级别)的服务。
- 基于Web browser的Ajax请求。
- 由于JSON具有非常强的前后兼容性,对于接口经常发生变化,并对可调式性要求高的场景,例如Mobile app与服务端的通讯。
- 由于JSON的典型应用场景是JSON+HTTP,适合跨防火墙访问
缺点
- 采用JSON进行序列化的额外空间开销比较大,对于大数据量服务或持久化,这意味着巨大的内存和磁盘开销,这种场景不适合。
- 没有统一可用的IDL降低了对参与方的约束,实际操作中往往只能采用文档方式来进行约定,这可能会给调试带来一些不便,延长开发周期。
- 由于JSON在一些语言中的序列化和反序列化需要采用反射机制,所以在性能要求为ms级别,不建议使用
{"userid":1,"name":"messi","address":[{"city":"北京","postcode":"1000000","street":"wangjingdonglu"}]}5.3 Thrift
- 简介
- FB开源的一个高性能轻量级的RPC框架
- 为了满足当前大数据量、分布式、跨语言、跨平台数据通讯的需求
- ,Thrift并不仅仅是序列化协议,而是一个RPC框架。相对于JSON和XML而言,Thrift在空间开销和解析性能上有了比较大的提升,对于对性能要求比较高的分布式系统,它是一个优秀的RPC解决方案;但是由于Thrift的序列化被嵌入到Thrift框架里面,Thrift框架本身并没有透出序列化和反序列化接口,这导致其很难和其他传输层协议共同使用
// IDL wen
struct Address
{
1: required string city;
2: optional string postcode;
3: optional string street;
}
struct UserInfo
{
1: required string userid;
2: required i32 name;
3: optional list<Address> address;
}5.4 Protobuf
- 特征
- 标准的IDL和IDL编译器,这使得其对工程师非常友好。
- 序列化数据非常简洁,紧凑,与XML相比,其序列化之后的数据量约为1/3到1/10。
- 解析速度非常快,比对应的XML快约20-100倍。
- 提供了非常友好的动态库,使用非常简介,反序列化只需要一行代码。
- Protobuf是一个纯粹的展示层协议,可以和各种传输层协议一起使用;Protobuf的文档也非常完善。 但是由于Protobuf产生于Google,所以目前其仅仅支持Java、C++、Python三种语言。另外Protobuf支持的数据类型相对较少,不支持常量类型。由于其设计的理念是纯粹的展现层协议(Presentation Layer),目前并没有一个专门支持Protobuf的RPC框架
- 应用场景
- Protobuf具有广泛的用户基础,空间开销小以及高解析性能是其亮点,非常适合于公司内部的对性能要求高的RPC调用。
- 由于Protobuf提供了标准的IDL以及对应的编译器,其IDL文件是参与各方的非常强的业务约束,
- 另外,Protobuf与传输层无关,采用HTTP具有良好的跨防火墙的访问属性,所以Protobuf也适用于公司间对性能要求比较高的场景
- 由于其解析性能高,序列化后数据量相对少,非常适合应用层对象的持久化场景。
// IDL File E.G
message Address
{
required string city=1;
optional string postcode=2;
optional string street=3;
}
message UserInfo
{
required string userid=1;
required string name=2;
repeated Address address=3;
}5.5 Avro
- 介绍
- Apache Hadoop的子项目
- 提供两种序列化方式
- Json
- 为了方便测试的调试过程
- Binary
- 空间开销和解析性能可以和Protobuf媲美
- Json
- 优点
- Avro支持JSON格式的IDL和类似于Thrift和Protobuf的IDL(实验阶段),这两者之间可以互转。
- Schema可以在传输数据的同时发送,加上JSON的自我描述属性,这使得Avro非常适合动态类型语言。
- Avro在做文件持久化的时候,一般会和Schema一起存储,所以Avro序列化文件自身具有自我描述属性,所以非常适合于做Hive、Pig和MapReduce的持久化数据格式。
- 对于不同版本的Schema,在进行RPC调用的时候,服务端和客户端可以在握手阶段对Schema进行互相确认,大大提高了最终的数据解析速度。
6. Benchmark
- 通过下面链接可以发现Protobuf和Avro在两个方面都表现很优越
https://code.google.com/archive/p/thrift-protobuf-compare/wikis/Benchmarking.wiki
Reference
- https://zhuanlan.zhihu.com/p/40462507
- https://www.liaoxuefeng.com/wiki/1016959663602400/1017624706151424
- https://tech.meituan.com/2015/02/26/serialization-vs-deserialization.html
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:序列化和反序列化
文章字数:3.6k
本文作者:Leilei Chen
发布时间:2021-01-14, 14:03:10
最后更新:2021-01-14, 14:04:54
原始链接:https://www.llchen60.com/%E5%BA%8F%E5%88%97%E5%8C%96%E5%92%8C%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

