工程上关于SQL数据库 - 你需要知道的事
大部分的计算机系统都会有需要维护的状态,大概率就要依赖于一个存储系统。在重数据的系统当中,数据库就会成为整个系统设计的核心,其中会有很多需要考虑到的权衡。我们必须要学习并且了解数据库是如何被使用的,这篇文章会分享一些对于开发者有用的视角和观点。
1. 网络连接问题 – 难以达到的5个9
总有关于当前的网络有多么值得信赖的考量,谷歌云的数据,在服务层面达到99.999%的可访问的程度的时候,大约有7.6%的问题是由于网络造成的。这也同样有相关数据在AWS,甚至阿里云当中。因为挖断光纤,或者网络配置的问题,造成一个数据中心,甚至一个avaliability zone 不可访问。
根据过往的经验,云服务提供商出现的网络问题,很有可能直接造成使用的公司服务down掉数小时的时间。从用户的角度来看,他们去定位问题所在是很有难度的。首先要尽快判断是IaaS 还是PaaS出现的问题,当判断出是云服务供应商这边出现的问题之后,除了尽快联系,恐怕也别无他法。
出现网络问题的原因很多,像是硬件炸了,权限更改,停电,光纤被挖断,诸如此类。各大云服务厂商都会在一个地区有多个AZ,每个AZ有多个data center,相互之间再用光纤连接。会需要看哪条光纤无法使用,会对整个系统造成不同程度的影响。
2. ACID 有多个涵义
ACID指的是Atomicity, Consistency, Isolation, Durability。这些都是数据库的transaction需要的相关属性,以确保用户的数据属性在程序崩溃,硬件出现错误等各种情况下依旧按照期待来运行。没有ACID的话,开发者无法知道自己的代码的责任,以及数据库的责任,会造成很多问题。当然上述说的还是主要对于SQL数据库而言的,对于NoSQL来说,大部分都没有实现ACID,或者不是默认实现的(譬如AWS DynamoDB,可以选择实现transaction的功能),因为他们实现起来很昂贵。
关于为什么NoSQL实现ACID很昂贵,首先需要说的是SQL对于大数据量是有瓶颈的,在上千万的数据规模以上,会难以继续扩容。NoSQL实质上是将传统的纵向扩容改为横向扩容,牺牲了一致性,(保证最终一致性),来达到对更多数据的支持。
值得注意的是工业界对于ACID是没有一个非常非常之明确的定义的,首先不是每个数据库都是满足ACID的,然后在那些满足ACID的数据库当中,ACID也可以被不同的方式来做解释。ACID被不同的方式来解释的原因之一是在实现的时候四个特征之间的制衡。他们在处理一个edge case还有“不可能”情况的时候,表现还是会有蛮多不一样的地方的。
3. 每个数据库都有不同的一致性和隔离性能力
在ACID属性当中,一致性和隔离性是在实现的时候最需要权衡的两个属性,因为实现的代价都很高。他们需要协同,在保证数据一致的过程中实质上是加剧了竞争的,竞争共同的资源。
在云服务的层面,一致性变得尤为困难,尤其是当我们需要横向的去扩展到不同的数据中心当中去的时候。根据CAP理论,一致性,可用性,分区容错性不可能同时满足,当我们要实现一致性的时候,势必会丢失掉一部分可用性,或者分区容错性。
值得注意的是,工程师是可以在程序的层面去解决一定的一致性的问题的,不一定要完全依赖于数据库层面的一致性检测。
数据库一般会提供一系列的隔离的层次,因此应用开发者就可以根据他们所需来选择最高效的isolation方式。弱隔离会更快,但也许会带来数据竞争。更强的隔离消减了一些潜在的数据隔离,但是会更慢,而且在慢到一定程度,TPS又相对比较高的情况下,数据库可能会被高TPS拖垮,变得不可访问。
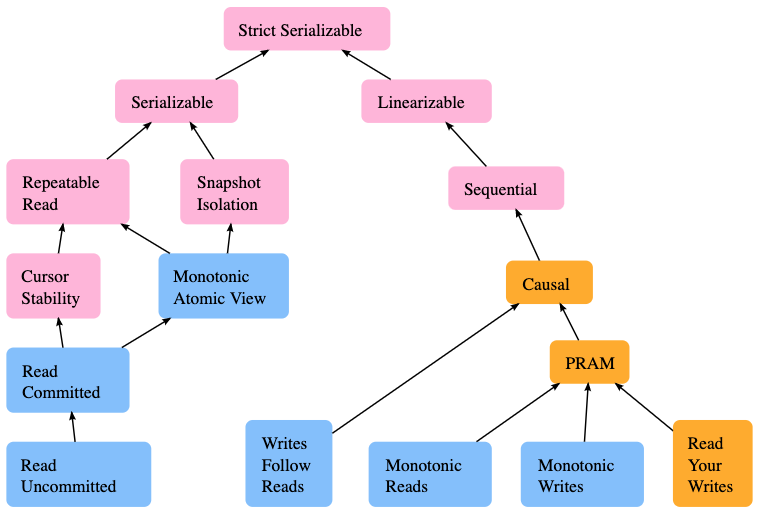
在SQL标准当中,隔离性的层级有:
- Serializable - 最严格,最昂贵的
- 序列化的执行会要求前一个transaction完全执行完,才能去执行下一个transaction
- 常常被称为snapshot isolation
- Repeatable reads
- 在当前transaction当中还没提交的读请求对当前transaction是可见的,但是其他transaction做出的改变对当前transaction依旧不可见
- Read Committed
- 未提交的读对transaction不可见
- 如果另外一个transaction插入并提交了新的行,当前的transaction在query的时候是可以看到的
- Read uncommitted
- 脏读是被允许的
- transactions可以看到其他transaction还没有提交的commit。很实用与count这种请求
关于具体的一个数据库,是怎么样对各级别的隔离进行处理的,可以参考 Github - hermitage
4. 当你无法完全锁住的时候,可以选择使用乐观锁
锁是极度昂贵的,这不仅仅是因为在数据库当中造成了强竞争,并且因为他们对于长连接的要求,这种从你的应用服务器到数据库的连接需要一直保持,是非常耗资源的。排它锁收到网络分区的影响更大,并且会导致非常难debug的死锁的问题。在排它锁不易实现的情境下,乐观锁是一个值得考虑的选择。
乐观锁从实现上是指当你去读一行的时候,记录下来版本号,最后一次修改的时间或者是checksum,想要达成的目的就是知道当前的它还是它。然后我们就可以在修改了数据之后去检测这个数据是否有被改变,如果没有,那么就证实其没有什么问题,我们就可以执行我们接下来的写操作了。
UPDATE products
SET name = 'Telegraph receiver', version = 2
WHERE id = 1 AND version = 1注意乐观锁不是在数据库层面的限制了,而是在应用代码的层面,加以限制。
5. 除了dirty reads 和data loss 你可能遇到其他的一些问题
当我们谈论数据一致性的时候,我们会主要将注意力放在可能的race condition当中,其会导致脏读,以及数据的丢失。但是可能出现的问题不仅仅会出现在这个方面的。
比如说write skew问题 - 写偏序,是指一致性约束下的异常现象,即两个并行事务都基于自己读到的数据去覆盖另一部分数据集,在串行化的情况下两个事务无论何种先后顺序,最终都将达到一致状态,但是在Snapshot Isolation的隔离级别下是无法实现的。
BEGIN tx1; BEGIN tx2;SELECT COUNT(*)
FROM operators
WHERE oncall = true;
0 SELECT COUNT(*)
FROM operators
WHERE oncall = TRUE;
0UPDATE operators UPDATE operators
SET oncall = TRUE SET oncall = TRUE
WHERE userId = 4; WHERE userId = 2;
COMMIT tx1; COMMIT tx2;为了解决write skew问题,需要在事务的运行阶段增加冲突检测,而不是在提交阶段。通过加入事务开始时间戳以及事务结束时间戳,保证一个事务读的数据的最近一个版本的提交时间要早于事务的开始时间。
6. 关于事务提交顺序
数据库首先是提供顺序保证的,但是这个顺序和我们想的可能会又不用。即从数据库的视角来看,关注的是接收到事务(transaction)的顺序,而不是开发者编程看到的顺序。事务执行的顺序是很难预测的,尤其是在高并发的系统当中。
如果说执行顺序非常关键的话,我们应当将多条命令放到同一个数据库transaction当中。老避开提交时间不确定的问题。
7. 应用层面的数据库分区可以布局在应用之外
有点拗口,想要说明的是当我们的数据库数据量持续增大的时候,横向的分区就变得必不可少了。但是很多数据库可能无法做好横向分区,即traffic会非常不均匀等等。
标题想要阐述的,这个分区的逻辑不需要必须在你的应用里边,我们可以单独抽取出一个层级,包含分区逻辑。即application server –> shard servers –> database nodes。这样分离的好处是随着数据量的增大以及访问的数据特征的变化,我们需要的分区逻辑也会不断发生变化。分隔开变化,使得分区逻辑的改变不需要重新deploy应用服务器,加速了整个开发的进程。
8. AUTOINCCREMENT 可能有害
AUTOINCREMENT是个很常见的生成主键的方式,常常看到数据库被用来作为ID生成器,或者有专门的一个数据库用来负责做ID的生成。这样做有可能会无益,以下是一些原因:
- 在分布式数据库系统当中,自动增长是一个很困难的事情。是需要一个global lock来生成ID的。如果你可以用UUID来取而代之的话,那么就不需要各个数据库节点之间的合作了。带锁的自增操作可能会引入冲突,极大的降低插入操作在分布式数据库当中的表现。
- 一些数据库根据主键来做分区算法,连续的ID很可能会导致不可测的热点,也许会让一些分区炸掉的同时其他分区很空闲。
- 最快访问数据库当中一行的方式就是通过其主键。如果我们能够有更好的定义一条数据的方式,那么使用其他富含意义的属性来作为主键会是个更好的选择。
9. 任何时间源之间可能会有不同
所有的时间相关的API是不准确的,我们的机器并不是清楚的知道当前具体是什么时间的。我们的电脑都包含一个石英晶片,可以用来产生信号,让时间开始走。但是这种方式下,不会非常精准,总会比实际的时间稍微快一些或者慢一些。为了精确性,我们的电脑上的时间就需要根据实际时间来进行同步。
NTP服务器可以被用来对时间进行同步,但是好玩的是同步本身又会因为网络延时不够准确。谷歌是使用TrueTime服务来做的
- 其使用两种不同的资源: GPS和原子钟。他们有不同的失败模式,因此二者并用能够增加可信赖度。
- TrueTime用时间间隔来表示返回的时间,即当前时间一定在一个区间之内,所做的事情就是保证在这个区间的可信度足够高了
10. 评估数据库在单个事务中的表现
有些时候数据库会宣传自己的表现以及特征,然后说自己的latency,读写吞吐量有多么多么的大。但是… 离开具体场景的数据都是耍流氓,我们需要更加细致的衡量方式来评估数据库在一些非常关键的操作或者事务下的表现。
比如:
- 当在一个有5000万行的数据库当中插入新的一行的吞吐量和延时
- 当查询用户的朋友的朋友(朋友的平均数量大致为500)的延时
- 获取用户时间线上前100条数据的延时,假定用户订阅了500个用户,每个用户每小时会发送n条信息
我们需要根据使用数据库的实际场景来做针对性的测试,来更加深入的理解这个数据库的特征
11. 事务当中不应该保存应用的状态
还是要注重相互之间的隔离的,client端在网络出现问题的时候常常会不停重试请求。如果事务依赖于一些能够在其他地方被改变的状态,那么事务当中可能就会拿到错误的数据,导致隐含错误的出现,开发者是很难找到这种类型的错误的。
var seq int64with newTransaction():
newSeq := atomic.Increment(&seq)
Entries.query(newSeq) // Other operations...譬如这种错误,事务当中会对sequence number做累加操作,当网络出现问题,会回滚,但是seq数字已经增加了,这就导致了下次执行的结果和上次本应该获得的结果会出现不同。
Reference
- https://medium.com/@rakyll/things-i-wished-more-developers-knew-about-databases-2d0178464f78
- https://www.quora.com/Why-doesnt-NoSQL-support-an-ACID-property
- https://en.wikipedia.org/wiki/CAP_theorem
- https://jepsen.io/consistency
- https://blog.csdn.net/oaa608868/article/details/54866899
- http://www.nosqlnotes.com/technotes/mvcc-snapshot-isolation/
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 stone2paul@gmail.com
文章标题:工程上关于SQL数据库 - 你需要知道的事
文章字数:3.4k
本文作者:Leilei Chen
发布时间:2020-04-28, 04:48:48
最后更新:2020-04-30, 02:39:57
原始链接:https://www.llchen60.com/%E5%B7%A5%E7%A8%8B%E4%B8%8A%E5%85%B3%E4%BA%8ESQL%E6%95%B0%E6%8D%AE%E5%BA%93-%E4%BD%A0%E9%9C%80%E8%A6%81%E7%9F%A5%E9%81%93%E7%9A%84%E4%BA%8B/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

