]]>
<h1 id="Background"><a href="#Background" class="headerlink" title="Background"></a>Background</h1><p>看了《时间贫困》这本书,发现对我来说很有用,确实有很多目标,很多想法,但是无
Add @MeterTag support with @Timedhttps://www.llchen60.com/Add-MeterTag-support-with-Timed/2023-09-23T09:01:30.000Z2023-09-23T09:10:57.638ZBackground
Micrometer add @MeterTag support on 2023, we are integrating micrometer with datadog in a spring boot project, this blog document how we set @MeterTag with @Timed
What’s MeterTag
With MeterTag annotation, we could add tags to @Timed with some dynamic value, e.g, sth parameters in the input. We could leverage on valueResolver, and use some expression language. For our case, Spel will be totally fine.
Implementation
Import related dependencies, in gradle kotlin, it would contains snippets as below
For the annotation you want to use, we need to define the corresponding aspect bean. As we want to enhance the @Timed with @MeterTag we need to set the meterTagAnnotationHandler
We mainly leverage on CachedSpelValueExpressionResolver to pass in an expression following spring expression language, the resolver is defined as follow
open class SpelValueExpressionResolver : ValueExpressionResolver { private val log = KotlinLogging.logger {} override fun resolve(expression: String, parameter: Any): String { try { val context = SimpleEvaluationContext.forReadOnlyDataBinding().withInstanceMethods().build() return parseExpression(expression).getValue(context, parameter, String::class.java) ?: "" } catch (ex: Exception) { log.error("Exception occurred while trying to evaluate the SpEL expression [$expression]", ex) } return parameter.toString() } open fun parseExpression(expression: String): Expression = SpelExpressionParser().parseExpression(expression)}class CachedSpelValueExpressionResolver : SpelValueExpressionResolver() { private val expressionsCache: MutableMap<String, Expression> = ConcurrentHashMap() override fun parseExpression(expression: String): Expression = expressionsCache.computeIfAbsent(expression) { super.parseExpression(expression) }}
]]>
<h1 id="Background"><a href="#Background" class="headerlink" title="Background"></a>Background</h1><p>Micrometer add @MeterTag support on 20
How to do bazel java_export with desired change onlyhttps://www.llchen60.com/How-to-do-bazel-java-export-with-desired-change-only/2023-08-16T12:26:10.000Z2023-08-16T12:43:23.725ZHow to to bazel java_export with desired change only
Faced one interesting issue when using bazel, the background is we have multiple repository to host code — SOA. For sharing, then we need to export the library and publish to company wide artifactory.
Background
We use bazel mainly because we have code on different languages, like RoR, Java, Kotlin, Scala, Clojure, etc. Bazel makes it easier to manage it cross different language in a monorepo.
For the export library purpose, we heavily rely on the rules_jvm_external , which has built-in java_export commend we could leverage on directly.
def java_export( name, maven_coordinates, deploy_env = [], excluded_workspaces = {name: None for name in DEFAULT_EXCLUDED_WORKSPACES}, pom_template = None, visibility = None, tags = [], testonly = None, **kwargs)
Basically we could follow the pattern here to define our srcs, deps, maven_coordinates, and then bazel could help us export it and publish to selected artifactory.
Issue
On the other end, we have a service built on kotlin with gradle. When we implement the library, we found inside the jar, besides the code in the export places, it also contain directory from com.google.protobuf.* , and unfortunately the protobuf package version in the lib mismatch with what we use in our own service, as the version in the lib is lower, it breaks the compilation of our code base, especially when we have couple extension functions in protobuf to enrich the conversion, whereas the old protobuf version does not support.
So basically we need to find a way to not include undesired directory inside the jar. In our case, remove those from com.google.protobuf.*
Add those into runtime_deps, then the export jar would not contain the directory from the pkg. It solves our problem perfect.
]]>
<h1 id="How-to-to-bazel-java-export-with-desired-change-only"><a href="#How-to-to-bazel-java-export-with-desired-change-only" class="headerl
CDK App with Github Actionhttps://www.llchen60.com/CDK-App-with-Github-Action/2023-01-18T07:08:52.000Z2023-01-18T07:11:50.406ZBackground
In our business use case, we need to create a proxy server to redirect traffic from a specific region. To achieve this, we leverage on aws lambda + api gateway with proper CORs setting, and allowed methods.
At first, we did this in aws console directly. It works fine, however, it would be more maintainable if we could achieve infra as code, benefits would be:
Speed
Low risk of human errors
Improved consistency
Eliminate configuration drift - correct source change mistake along with the pipeline deployment
Improved security strategies
Stable and scalable env
Self documentation
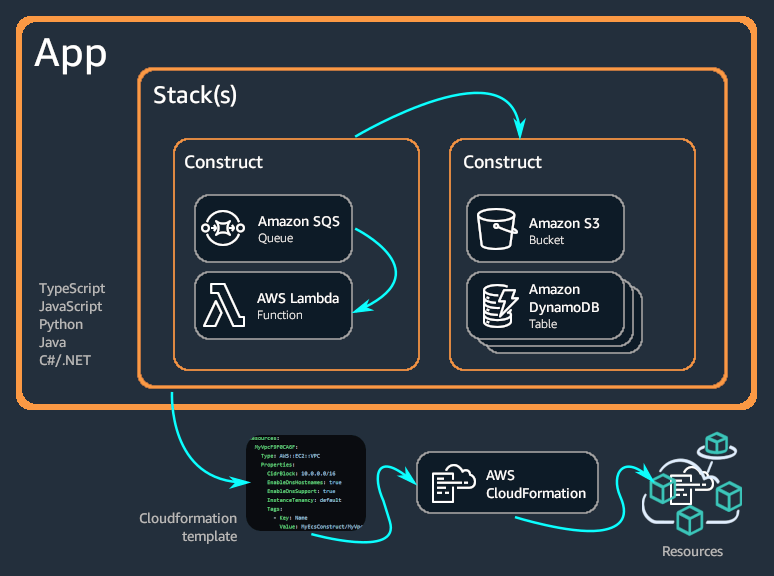
CDK Introduction
Concepts
CDK
Cloud Development Kit, is a framework for defining cloud infrastructure in code (IaC) and provisioning it through AWS CloudFormation.
We could leverage this tool to quickly build reliable, scalable, cost-effective applications in the cloud with the considerable expressive power of a programming language. AWS CDK Developer Guide
Construct
the basic building blocks of AWS CDK apps.
encode configuration detail, boilerplate, and glue logic for using one or multiple AWS services.
CloudFormation
CloudFormation gives an easy way to create a collection of related AWS and third-party resources, and provision and manage them in an orderly and predictable fashion
Repeatable deployment, easy rollback, and drift detection
Using a configuration language (YAML or JSON)
Stacks
a collection of AWS resources that you can manage as a single unit in CloudFormation
How does CDK work?
AWS CDK takes the code we write (Stacks and Construct)
Compiles it down to CloudFormation
During cdk deployment, cloudFormation will help us create all resources we defined in CDK
represents an architecture that includes an AWS Fargate container cluster employing an Application Load Balancer.
help you to define load balancer, fargate service, ECS, ECR
we could also define our network setting like VPC, subnet, cloudMap inside the construct
Powered by AWS CloudFormation
repeatable deployment, easy rollback, and drift detection
Use familiar programming languages, tools, and workflows
Per the guide, inside Amazon, new features would be first developed in typescript, then leverage on some parsing tool to translate to different languages. Thus in this MVP, I’ll also use typescript.
Development Process
Prerequisite: You need to at least have permission to the corresponding aws account to move forward
The development loop consists of
Check CDK Doc, try to use constructs
Run cdk diff and cdk synth
check the output and make sure the changes are expected
Run cdk deploy to deploy aws resources
You should be able to see corresponding stacks in AWS Console - CloudFormation
Once the stack is deployed successfully, you should be able to see resources get created
If you find something wrong, you could just change the code, CDK and CloudFormation will help to take care of the update of your stack
If the stack is in some convoluted status, you could try to do cdk destroy or just manually delete the corresponding stack from the CloudFormation console page
remember the deletion needs to be started with the higher level stack, if there are some other stacks that rely on your current to-be-deleted stack, your deletion would not be able to finish
could happen when you deal with ALB/ NLB
Build CDK app using constructs
CDK has different level construct per guide. In our case, we should try our best to interact with high-level constructs/ patterns which have common tasks predefined. One good example would be ApplicationLoadBalancedFargateService, we could leverage on such construct directly instead of defining load balancer, route table, IAM roles, ECR, ECS, Fargate, etc. on our own. It could save a lot of time, and also help us insist on the best practice per Amazon team guidance.
CDK API Doc would be a great reference during the development
Compares the specified stack and its dependencies with the deployed stacks or a local CloudFormation template
We should make sure the diff change are what we want locally before deployment
cdk synth to generate CloudFormation file
Synthesizes and prints the CloudFormation template for one or more specified stacks
One Example when we generate our lambda server with api gateway
IAM Role
S3 Bucket for Code
Lamda handler
Api Gateway
Metadatas for defined resources
**cdk deploy - deploy to CloudFormation
Deploys one or more specified stacks
Log would show the change and deployment progress
Useful Commands
// install cdk globally npm install -g aws-cdk// configure access token, secret, account id, preferred region hereaws configuremkdir cdkAppDictName cdk init app --language typescript// check command guide for reference https://docs.aws.amazon.com/cdk/v2/guide/cli.html // list stacks in the app cdk list // synthesize the prints the cloudformation template cdk synth // bootstrap CDK toolkit stack cdk bootstrap cdk destroy // Compares the specified stack and its dependencies with the deployed stacks or a local CloudFormation templatecdk diff // Deploys one or more specified stackscdk deploy
CI/ CD workflow setup
After PR, we want to do a automatic deployment in github
there are couple options we could leverage on, E.G
buildkite
github action
In this project, we use github action
Github Action Core Concept
Workflow
configurable automated process that will run one or more jobs
defined in yaml file
reside under .github/workflows
Event
an activity to trigger a workflow to run
Job
a set of steps in a workflow that execute on the same runner
executed in order
Action
Perform a complex but frequently repeated task
Use action to help reduce the amount of repetitive code
Runner
server runs the workflow when they are triggered
Github Action Syntax
that’s the main part we need to use
we could define our action under .github/workflows , define what events should trigger the workflow
here we also need to define which runner we want to use, we could use public runner offered by github, or we could use self hosted one
this action would need several secrets for us to access slack or aws
we could generate them in corresponding platform, and put them under github repository secrets section
Code
name: "cdk deploy"on: push: branches: - masterjobs: aws_cdk: runs-on: "your runner" steps: - name: Post to a Slack Channel Before Deployment id: slack-before-deploy uses: slackapi/slack-github-action@v1.23.0 with: # Slack channel id, channel name, or user id to post message. # See also: https://api.slack.com/methods/chat.postMessage#channels channel-id: "channel-id" # For posting a rich message using Block Kit payload: | { "blocks": [ { "type": "section", "text": { "type": "mrkdwn", "text": "*Hello World*" } } ] } env: SLACK_BOT_TOKEN: ${{ secrets.SLACK_BOT_TOKEN }} - name: Checkout repo uses: actions/checkout@v3 - uses: actions/setup-node@v2 with: node-version: "14" - name: Configure aws credentials uses: aws-actions/configure-aws-credentials@master with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY }} aws-secret-access-key: ${{ secrets.AWS_SECRET_KEY }} aws-region: us-west-1 - name: Install dependencies run: npm install -g yarn && yarn - name: Synth stack run: yarn cdk synth - name: Deploy stack run: yarn cdk deploy --all - name: Post to a Slack Channel Post Deployment id: slack-after-deploy-success if: ${{ success() }} uses: slackapi/slack-github-action@v1.23.0 with: # Slack channel id, channel name, or user id to post message. # See also: https://api.slack.com/methods/chat.postMessage#channels channel-id: "channel-id" # For posting a rich message using Block Kit payload: | { "blocks": [ { "type": "section", "text": { "type": "mrkdwn", "text": "text msg" } } ] } env: SLACK_BOT_TOKEN: ${{ secrets.SLACK_BOT_TOKEN }} - name: Post to a Slack Channel Post Deployment id: slack-after-deploy-failure if: ${{ failure() }} uses: slackapi/slack-github-action@v1.23.0 with: # Slack channel id, channel name, or user id to post message. # See also: https://api.slack.com/methods/chat.postMessage#channels channel-id: "channel-id" # For posting a rich message using Block Kit payload: | { "blocks": [ { "type": "section", "text": { "type": "mrkdwn", "text": "test msg" } } ] } env: SLACK_BOT_TOKEN: ${{ secrets.SLACK_BOT_TOKEN }}
That’s literally the whole process for us to integrate CDK with github actions, let me know if you have any questions! :)
]]>
<h1 id="Background"><a href="#Background" class="headerlink" title="Background"></a>Background</h1><p>In our business use case, we need to c
Singleton Patternhttps://www.llchen60.com/Singleton-Pattern/2022-12-07T11:18:26.000Z2022-12-07T11:19:07.324Z1. why we need
Registry Setting
Thread Pool / Connection Pool
The singleton Pattern ensures a class has only one instance, and provides a global point of access to it.
let a class to manage a single instance of itself
also prevent other classes from creating a new instance on its own
provide a global access point to the instance
2. Implementation
2.1 1st Iteration
public class Singleton { private static Singleton uniqueInstance; private Singleton() {} public static Singleton getInstance() { if (uniqueInstance == null) { uniqueInstance = new Singleton(); } return uniqueInstance; }}
Issue when multi threading
Thread A
if (uniqueInstance == null) { // return true
new Singleton()
Thread B
if (uniqueInstance == null) { // return true
new Singleton()
Under such case, we’ll create two new instances
2.2 Implementation with multi-threading support
public class Singleton { private static Singleton uniqueInstance; private Singleton() {} public static synchronized Singleton getInstance() { if (uniqueInstance == null) { uniqueInstance = new Singleton(); } return uniqueInstance; }}
synchronized
force every thread to wait its turn before it can enter the method
no two threads may enter the method at the same time
Issue
we only need synchronized when there is no instance, once there are, no need to use synchronized, it’s just overhead
2.3 Implementation with multi-threading support — Eagerly created instance
public class Singleton { private static Singleton uniqueInstance = new Singleton(); private Singleton() {} public static synchronized Singleton getInstance() { return uniqueInstance; }}
We rely on the JVM to create the unique instance of the Singleton when the class is loaded
JVM guarantees the instance will be created before any thread accesses the static unique instance variable
2.4 Implementation with multi-threading support — Double Checked Locking
public class Singleton { private volatile static Singleton uniqueInstance; private Singleton() {} public static synchronized Singleton getInstance() { if (uniqueInstance == null) { synchronized (Singleton.class) { if (uniqueInstance == null) { uniqueInstance = new Singleton(); } } } return uniqueInstance; }}
volatile
ensure multiple threads handle the unique instance variable correctly when it is initialized to the singleton instance
2.5 Implementation with multi-threading support — Using Enum
public enum Singleton { UNIQUE_INSTANCE;}public class SingletonClient { Singleton singleton = Singleton.UNIQUE_INSTANCE;}
ClassLoader
Responsible for loading java classes dynamically to the JVM during runtime
Responsible for loading classes into memory
type
application class loader
An application or system class loader loads our own files in the classpath.
extension class loader
Extension class loaders load classes that are an extension of the standard core Java classes.
bootstrap class loader
A bootstrap or primordial class loader is the parent of all the others.
This is because the bootstrap class loader is written in native code, not Java, so it doesn’t show up as a Java class
how does it work
JVM request a class
class loader try to locate the class and load the definition into the runtime using fully qualified class name
delegation model
delegate the search of the class/ resource to the parent class loader
]]>
<h1 id="1-why-we-need"><a href="#1-why-we-need" class="headerlink" title="1. why we need"></a>1. why we need</h1><ul>
<li>Registry Setting</
工厂模式https://www.llchen60.com/%E5%B7%A5%E5%8E%82%E6%A8%A1%E5%BC%8F/2022-12-05T13:24:32.000Z2022-12-05T13:26:47.688Z1.工厂模式Overview
Define an interface for creating an object, but let’s subclasses decide which class to instantiate. Factory method lets a class defer instantiation to subclasses.
出现工厂模式是因为我们不希望将实现和类的声明进行强绑定,我们希望整体在一个松耦合的状态
我们希望达到的理想状态是 Open for extension, Close for modification.
but for common one, we should define here, and subclass could override if they want
a set of subclass implements the abstract methods
product side
abstract product
concrete products which extends the abstract one
2. 使用场景
当我们的对象生成需要某些逻辑运算的时候,比如需要根据一些传入的参数来决定生成什么样子的对象
3. 使用目的
将对象的生成和使用解耦,方便对于一组对象的维护,根据一些条件来生成指定的对象
4. 具体实现
4.1 接口和数据对象定义
public abstract class Animal { String name; public abstract void bark();}public interface IAnimalFactory { Animal createAnimal(String type);}
4.2 具体实现类的定义
public class Cat extends Animal { public Cat(String name) { this.name = name; } @Override public void bark() { System.out.println("miao"); }}public class Dog extends Animal { public Dog(String name) { this.name = name; } @Override public void bark() { System.out.println("wang"); }}public class RandomFactory implements IAnimalFactory { @Override public Animal createAnimal(String name) { Random random = new Random(); int num = random.nextInt(2); var list = Arrays.asList("cat", "dog"); switch(list.get(num)) { case "cat": return new Cat(name); case "dog": return new Dog(name); default: return null; } }}
4.3 测试
@GetMapping("/factory") public String factory() { RandomFactory randomFactory = new RandomFactory(); randomFactory.createAnimal("test").bark(); randomFactory.createAnimal("test").bark(); randomFactory.createAnimal("test").bark(); randomFactory.createAnimal("test").bark(); randomFactory.createAnimal("test").bark(); return "check the log"; }
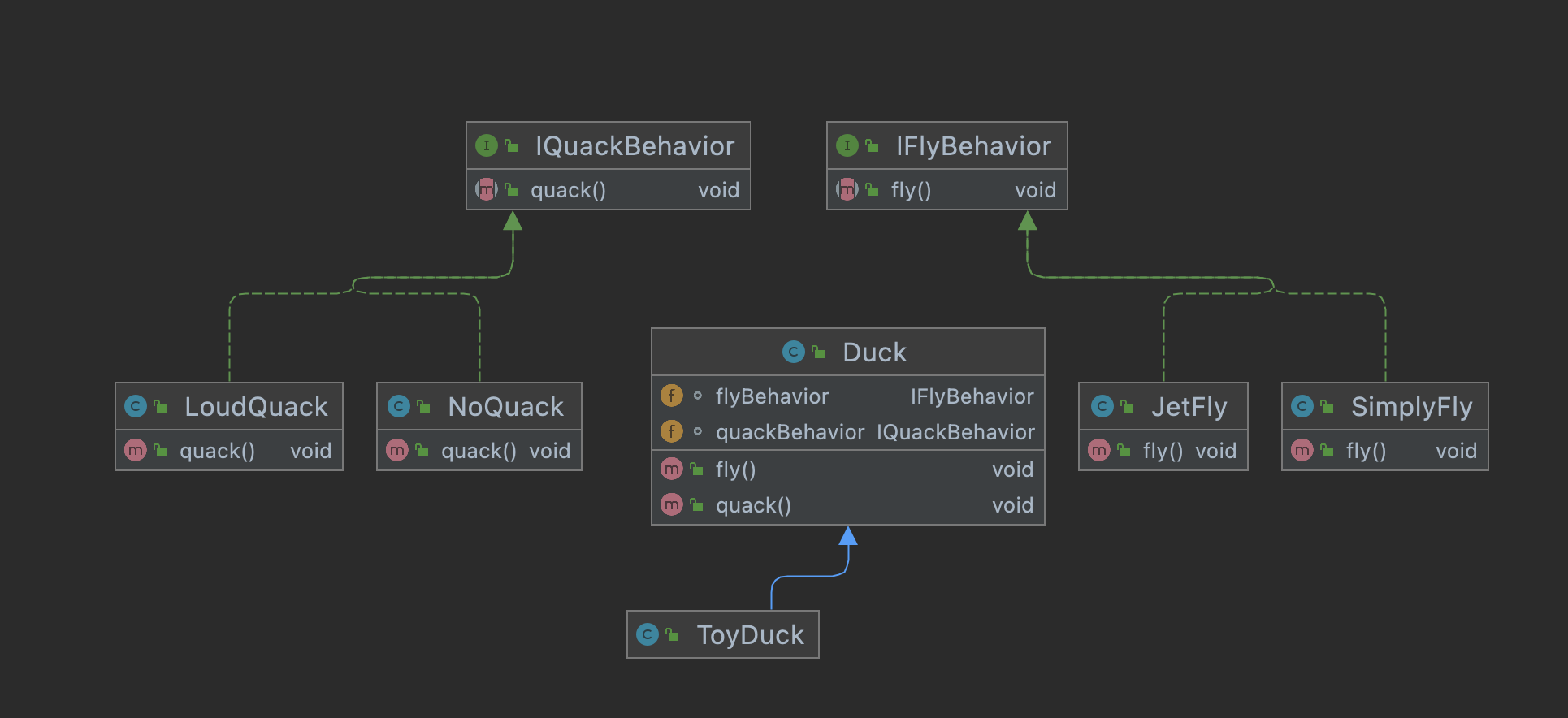
Strategy patten define a set of algorithms, encapsulate each of them and make then exchangable. And we could switch them at run time , decouple the algorithm with the place they are used
2. Why use strategy pattern?
when we have a set of classes, they belong to same object, they should could a certain types of actions, but the detail would vary. Then we need a way to regulate they have such type of behaviors, and also differ them in a maintainable manner
public class Duck { IFlyBehavior flyBehavior; IQuackBehavior quackBehavior; public void fly() { flyBehavior.fly(); } public void quack() { quackBehavior.quack(); }}public class JetFly implements IFlyBehavior { @Override public void fly() { System.out.println("Jet Fly"); }}public class SimplyFly implements IFlyBehavior { @Override public void fly() { System.out.println("Simple flying"); }}public class LoudQuack implements IQuackBehavior { @Override public void quack() { System.out.println("Make noise!"); }}public class NoQuack implements IQuackBehavior { @Override public void quack() { // do nothing, as no quack exist }}public class ToyDuck extends Duck { public ToyDuck(IFlyBehavior flyBehavior, IQuackBehavior quackBehavior) { this.flyBehavior = flyBehavior; this.quackBehavior = quackBehavior; }}
3.3 Test
@GetMapping("/strategy") public String strategy() { Duck testDuck = new ToyDuck(new JetFly(), new LoudQuack()); testDuck.fly(); testDuck.quack(); return "check the log"; }
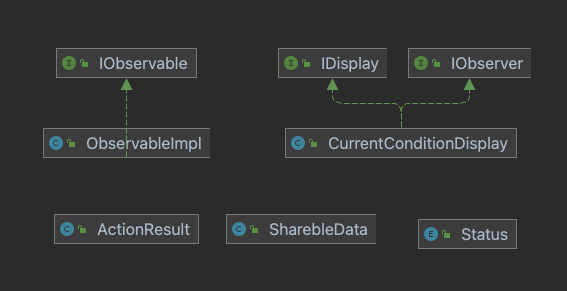
/** * Observer other abilities */public interface IDisplay { void display();}/*** Observable interface, used to register/remove/notify observers */public interface IObservable { ActionResult registerObserver(IObserver observer); ActionResult removeObserver(IObserver observer); void notifyObservers();}/** * Observable will call update method for regiestered observer to update the status in observer side */public interface IObserver { void update(SharebleData data);@Data@RequiredArgsConstructor@AllArgsConstructorpublic class SharebleData { Double temperature; Double humidity; Double pressure;}public enum Status { SUCCESS, FAILURE}@Data@AllArgsConstructorpublic class ActionResult { @NonNull Status status; @Nullable List<String> errorReason;}
4.2 具体实现类的定义
public class ObservableImpl implements IObservable{ private static List<IObserver> observerList; private SharebleData data; public ObservableImpl() { observerList = new ArrayList<>(); data = new SharebleData(); } public void setSharebleData(double tem, double humidity, double pressure) { data.setHumidity(humidity); data.setTemperature(tem); data.setPressure(pressure); notifyObservers(); } @Override public ActionResult registerObserver(IObserver observer) { observerList.add(observer); return new ActionResult(Status.SUCCESS, null); } @Override public ActionResult removeObserver(IObserver observer) { observerList.remove(observer); return new ActionResult(Status.SUCCESS, null); } @Override public void notifyObservers() { observerList.forEach(observer -> {observer.update(data);}); }}public class CurrentConditionDisplay implements IObserver, IDisplay{ private double temp; private double pressure; private IObservable observable; public CurrentConditionDisplay(IObservable subject) { this.observable = subject; observable.registerObserver(this); } @Override public void display() { System.out.println(String.format("======= print out current tem and pressure! temp: %f, pressure: %f ", temp, pressure)); } @Override public void update(SharebleData data) { temp = data.getTemperature(); pressure = data.getPressure(); display(); }}
4.3 测试
@RestControllerpublic class TestController { @GetMapping("/observer") public String observer() { StringBuilder sb = new StringBuilder(); ObservableImpl observable = new ObservableImpl(); observable.setSharebleData(30, 0.7, 80); CurrentConditionDisplay currentConditionDisplay = new CurrentConditionDisplay(observable); observable.setSharebleData(31, 0.7, 80); observable.setSharebleData(32, 0.7, 80); observable.setSharebleData(33, 0.7, 80); return "Please check log"; }}// Output from console ======= print out current tem and pressure! temp: 31.000000, pressure: 80.000000 ======= print out current tem and pressure! temp: 32.000000, pressure: 80.000000 ======= print out current tem and pressure! temp: 33.000000, pressure: 80.000000
]]>
<h1 id="1-观察者模式Overview"><a href="#1-观察者模式Overview" class="headerlink" title="1. 观察者模式Overview"></a>1. 观察者模式Overview</h1><ul>
<li>定义了一种一对多的交
How to use Sprint transactional annotationhttps://www.llchen60.com/How-to-use-Sprint-transactional-annotation/2022-07-15T12:58:18.000Z2022-07-15T12:59:24.908ZHow to use Sprint transactional annotation
1. Attributes
value and transactionManager
used to provide a TransactionManager reference to be used when handling the transaction for the annotated block
propagation
define how the transaction boundaries propagate to other methods that will be called either directly or indirectly from within the annotated block
default is REQUIRED
means a transaction is started if no transaction is already available
otherwise use the current running thread
timeout and timeoutString
define the max number of seconds the current method is allowed to run
readOnly
defines if the current transaction is read-only or read-write
rollbackFor and rollbackForClassName
define one or more Throwable classes for which the current transaction will be rolled back
default is RuntimeException or an Error is thrown, but not for a checked Exception
noRollbackFor and noRollbackForClassName
used for one or more RuntimeException
2. Transaction Override
addStatementReportOperation is using the serializeble level, which override the class level readonly transaction
@Service@Transactional(readOnly = true)public class OperationService { @Transactional(isolation = Isolation.SERIALIZABLE) public boolean addStatementReportOperation( String statementFileName, long statementFileSize, int statementChecksum, OperationType reportType) { ... }}
we use readOnly in class level because Spring could perform some read only optimization
we could save memory when loading read only entities since the loaded state is discarded right away, and not kept for the whole duration of the currently running persistence context
also, in the cluster, read only data source could be redirected to DB replica instead of DB primary, this could also reduce the burden for primary
]]>
<h1 id="How-to-use-Sprint-transactional-annotation"><a href="#How-to-use-Sprint-transactional-annotation" class="headerlink" title="How to u
PG::DuplicatePstatement Error prepared statement axxx already existshttps://www.llchen60.com/PG-DuplicatePstatement-Error-prepared-statement-axxx-already-exists/2022-07-01T14:04:04.000Z2022-07-01T14:05:31.350ZThat’s an interesting issue we faced in production during one deployment which only contain some frontend changes.
Upon check, this happens in such scenario:
A prepared statement is generated in postgresql, but never stored in rails. Since the code was interrupted before storing the statement, the @counter variable was never incremented even though it was used to generate a prepared statement.
That pretty much described the issue, prepared statement on postgres side is a server side object that can be used to optimize performance. When the PREPARE statement is executed, the specified statement is parsed, analyzed, and rewritten. When an EXECUTEcommand is subsequently issued, the prepared statement is planned and executed.
When the identifiers already bound to existing prepared statements but rails does not realize it, this issue will be happened.
def next_key "a#{@counter + 1}"end def next_key "a#{@counter += 1}"end This change make the postgres prepared statement counter before makeing a prepared statementThus if the statemnt is aborted in rails side, app won't end up in perpetual crash state
]]>
<p>That’s an interesting issue we faced in production during one deployment which only contain some frontend changes. </p>
<p>Upon check, th
Equity 101https://www.llchen60.com/Equity-101/2022-04-02T09:08:11.000Z2022-04-02T09:09:25.877Z1. What is equity?
A form of compensation
give you partial ownership in the company
shares
options
RSUs
can have seriously life changing result
Liquidity
the ability to sell your shares
2. Cap Table
A document that details who has ownership in a company
records
how and when you’ll get your shares
how many shares you’ll get
how you’ll be paid out
employee option pool
investors require it, to hire talented people
let talented stay longer
different types of equity
preferred shares — investors
stock options — employees
advisory shares — advisors
3. Equity grants
equity grant agreements
how many shares you are getting
how much each share is worth
how long it will take to vest all your shares
types of equity
stock option — early stage
you have the option to buy shares, but not obligated to
only vest on a single trigger
taxed when you buy/ sell your shares
option types
incentive stock option
pay tax when you sell your shares
non qualified stock option
pay taxes when you buy and sell shares
restricted stock units - large startup
you receive shares that you own automatically
often vest on a double trigger
taxed when get vested
4. How vesting work
Earning the right to buy your shares
when you are taxed
when you are able to buy shares
vesting structures
time based vesting
event based vesting
hybrid vesting
option outstanding
options has not been granted
5. How exercising equity works
Being granted stock options doesn’t mean you’re automatically a shareholder in a company.
Stock option not means share, you need to buy it
exercise
means you purchase stock at a specified price
purchase your options
then company give stock certificate
strike price
option price you could leverage on to buy stocks
fixed price
409A valuation
an analysis of your company’s financials, which determines the value of the company’s shares
usually done every 12 months
Fair Market Value - FMV
the value of one share of common stock
Spread/ Gain
the difference between stock price and strike price
PTEP - post termination exercise period
the amount of time you have to exercise your options after you leave the company
early exercise
company let you buy everything today
then you just need to pay taxes at strike price
83b election
a form sent to IRS
you want to pay tax now
6. How to sell shares
How and when can you sell your shares
think about
any restrictions on selling?
do you need the cash?
is the value increasing?
only chance to sell?
ways
public company
public shares pretty liquid,
as it’s easy to convert them into cash at market price
private company
strongly restrict sell usually
ways
IPO
usually 6 month lock up period after going public
M&A
bought or merge acquisition
another company buys your shares
pay for cash or other stocks
tender offer
company buy from employee
could happen while the company still private
7. How are equity grants taxed?
ISO shares
when sell it, tax rate come to be different
qualifying disposition
1 year after exercise
2 years after option grant date
long term capital gains tax
0% 0 20%
short term capital gains
taxed at ordinary income rates
AMT
alternative minimum tax
a low threshold, or floor, defining the minimum amount of taxes you are obligated to pay
8. Valuations
dilution
affect the percentage you have
how valuation works
term sheet
a legal document defining the terms of an investment
valuation
an appraisal of a company’s worth
affect
how many shares
price per shares
percentage
stage
pre money valuation
post money matters you
the employee stock option pool—that percentage of the company that gets carved out for new hires and new employees? Well, if you think about how dilution works, when an option pool gets carved out, it reduces the ownership percentage of all of the other shareholders. So that’s why a lot of the time, when an investor puts money into a company, they’ll require that this option pool gets sliced out of the company on a pre-money basis.
investment
post money valuation
how valuations are calculated
valuation for startup come to be complex,
revenue, profit, tax, etc.
growth rate
user count
industry
founding team
section 409A
let 3rd party help do valuation for the startup
every 12 months
or every time do a new fund raising
9. Who can invest in startups
For private company
no need to release any info to public
less info and more risk comparing with public company investment
who can invest in a startup
accredited investor
more relevant to individuals
criteria (either one of them)
net worth over a million, not include the primary living place;
income net income 200k per year for last 2 years. reasonable expectation in following year; for a family is 300k
passing a financial exam, hold a license
qualified purchaser
more relevant for funds, institution,
all about investment, purchasing power
an entity that has a significant amount of investment capital — their purchasing power
10. How venture capital works
venture capital system
equity financing
angel investors
venture capital fund
invest other people’s money through fund
debt financing
type of fundraising instruments
convertible instrument
investor iou, convert the note into shares, owns equity in the future
]]>
<h1 id="1-What-is-equity"><a href="#1-What-is-equity" class="headerlink" title="1. What is equity?"></a>1. What is equity?</h1><ul>
<li>A fo
System.nanoTime vs System.currentTimeMillishttps://www.llchen60.com/System-nanoTime-vs-System-currentTimeMillis/2022-03-28T10:13:34.000Z2022-03-28T10:14:08.401Z1. Monotonic Clock
suitable for measuring a duration, such as a timeout or a service’s response time
clock_gettime(CLOCK_MONOTONIC)
System.nanoTime()
They are guaranteed to always move forward
However, the absolute value of the clock is meaningless: it might be the number of nanoseconds since the computer was started, or something similarly arbitrary. In particular, it makes no sense to compare monotonic clock values from two different computers, because they don’t mean the same thing.
On a server with multiple CPU sockets, there may be a separate timer per CPU, which is not necessarily synchronized with other CPUs
2. Time of day clock
It returns the current date and time according to some calendar
clock_gettime(CLOCK_REALTIME)
System.currentTimeMillis()
return the number of seconds since the epoch
this time is synchronized with NTP, which means a timestamp from one machine ideally means the same as a timestamp on another machine
Oddies
In particular, if the local clock is too far ahead of the NTP server, it may be forcibly reset and appear to jump back to a previous point in time. These jumps, as well as similar jumps caused by leap seconds, make time-of-day clocks unsuitable for measuring elapsed time
interruptions in the network can unexpectedly cut off the application from the db, or one db node from another
several clients may write to the db at the same time, overwriting each other’s change
race conditions between clients can cause surprising bugs
1.2 Transaction
Transaction is the mechanism for us to simplify those issues
Group several reads and writes together is a logical unit
either the entire transaction succeeds or it fails
application can safely retry if it fails
Transaction makes error handling much more easier
no need to worry about partial failure
Transaction is created with a purpose, to simplify the programming model for applications accessing a database
database take care of such issue
for transaction, we need to understand
what safety guarantees transactions can provide
what costs are associated with them
2. ACID
ACID are the safety guarantees provided by transactions
Atomicity
Consistency
Isolation
Durability
2.1 Atomicity
Atomic means sth cannot be broken down into smaller parts
Describes what happens if a client want to make several writes, but a fault occurs after some of the writes have been processed
if the writes are grouped together into an atomic transaction
the transaction cannot be completed due to a fault,
then the transaction is aborted
the database must discard or undo any writes it has made so far in that transaction
The ability to abort a transaction on error and have all writes from that transaction discarded is the defining feature of ACID atomicity
2.2 Consistency
Consistency refers to an application specific notion of the database being in a good state
The idea of ACID consistency is that you have certain statements about your data (invariants) that must always be true—for example, in an accounting system, credits and debits across all accounts must always be balanced
But this ususally is application code responsibility to define what data is valid or invalid
2.3 Isolation
Isolation means that concurrently executing transactions are isolated from each other: they cannot step on each other’s toe
2.4 Durability
Purpose of a db system is to provide a safe place where data can be stored without fear of losing it
Durability is the promise that once a transaction has committed successfully, any data it has written will not be forgotten, even if there is a hardware fault or the database crashes.
In a single node database
means data has been written to nonvolatile storage such as a hard drive or SSD
could also involves a write ahead log
In a replicated db,
means data has been successfully copied to some number of nodes
3. Single and Multi Objects Operations - Atomicity + Isolation
3.1 Multi Object Transactions
3.1.1 Why we need it
Need some way to determine which read and write operations belong to the same transaction
In relational db, typically done based on the client’s TCP connection to the database server
on any particular connection, everything between a BEGIN TRANSACTION and a COMMIT statement is considered to be part of the same transaction
3.1.2 Scenarios
In a relational data model, a row in one table often has a foreign key reference to a row in another table
multi object transactions allow you to ensure that these references remain valid
In a document data model, the fields that need to be updated together are often within the same document, which is treated as a single object—no multi-object transactions are needed when updating a single document. However, document databases lacking join functionality also encourage denormalization. When denormalized information needs to be updated, you need to update several documents in one go. Transactions are very useful in this situation to prevent denormalized data from going out of sync
In db with secondary indexes, indexes also need to be updated every time you change a value
These indexes are different database objects from a transaction point of view: for example, without transaction isolation, it’s possible for a record to appear in one index but not another, because the update to the second index hasn’t happened yet.
3.2 Single Object Writes
Atomicity and isolation also apply when a single object is being changed
all storage engines universally aim to provide atomicity and isolation on the level of a single object on one node
Atomicity
Using a log for crash recovery
increment operation
compare and set
Isolation
Using a lock on each object
3.3 Handling errors and aborts
ACID DB Philosophy
Aborts of transaction point is to safely retry, thus we should have some retry mechanism build for such scenario
4. Isolation Levels
Concurrency bugs are hard to find by testing, cause they are rare, and difficult to reproduce. For such reasons, databases have long tried to hide concurrency issues from application developers by providing transaction isolation
In theory, isolation should make your life easier by letting you pretend that no concurrency is happening: serializable isolation means that the database guarantees that transactions have the same effect as if they ran serially
In practice, isolation has a performance cost, and many databased don’t want to pay that price. Thus it’s common for systems to use weaker levels of isolation, which protect against some concurrency issues, but not all
4.1 Read Committed
4.1.1 Guarantees
when reading from the database, you will only see data that has been committed(no dirty reads)
when writing to the database, you will only overwrite data that has been committed (no dirty writes)
4.1.2 No dirty reads Explanation
Prevent dirty read, only committed record could be seen
reasons for dirty read prevention
See the database in a partially updated state is confusing to users and may cause other transactions to take incorrect decisions
If a transaction aborts, any writes it has made need to be rolled back (like in Figure 7-3). If the database allows dirty reads, that means a transaction may see data that is later rolled back—i.e., which is never actually committed to the database. Reasoning about the consequences quickly becomes mind-bending.
4.1.3 No Dirty Write Explanation
If two transactions concurrently try to update the same object in a db, we normally assume that the later write overwrites the earlier write
Dirty write happen when
the earlier write is part of a transaction that has not yet committed, so the later write overwrites an uncommitted value
how does committed isolation level work?
by delaying the second write until the first write’s transaction has committed or aborted
4.1.4 Implementation
Dirty writes — Row level lock
when a transaction wants to modify a particular object (row or document), it must first acquire a lock on that object.
It must then hold that lock until the transaction is committed or aborted.
Only one transaction can hold the lock for any given object;
if another transaction wants to write to the same object, it must wait until the first transaction is committed or aborted before it can acquire the lock and continue.
This locking is done automatically by databases in read committed mode (or stronger isolation levels).
Dirty Reads —
still use row level lock
the approach of requiring read locks does not work well in practice, because one long-running write transaction can force many other transactions to wait until the long-running transaction has completed, even if the other transactions only read and do not write anything to the database
This harms the response time of read-only transactions and is bad for operability: a slowdown in one part of an application can have a knock-on effect in a completely different part of the application, due to waiting for locks.
most databases prevent dirty reads using the approach illustrated here
for every object that is written, the database remembers both the old committed value and the new value set by the transaction that currently holds the write lock.
While the transaction is ongoing, any other transactions that read the object are simply given the old value. Only when the new value is committed do transactions switch over to reading the new value.
4.2 Snapshot Isolation and Repeatable Read
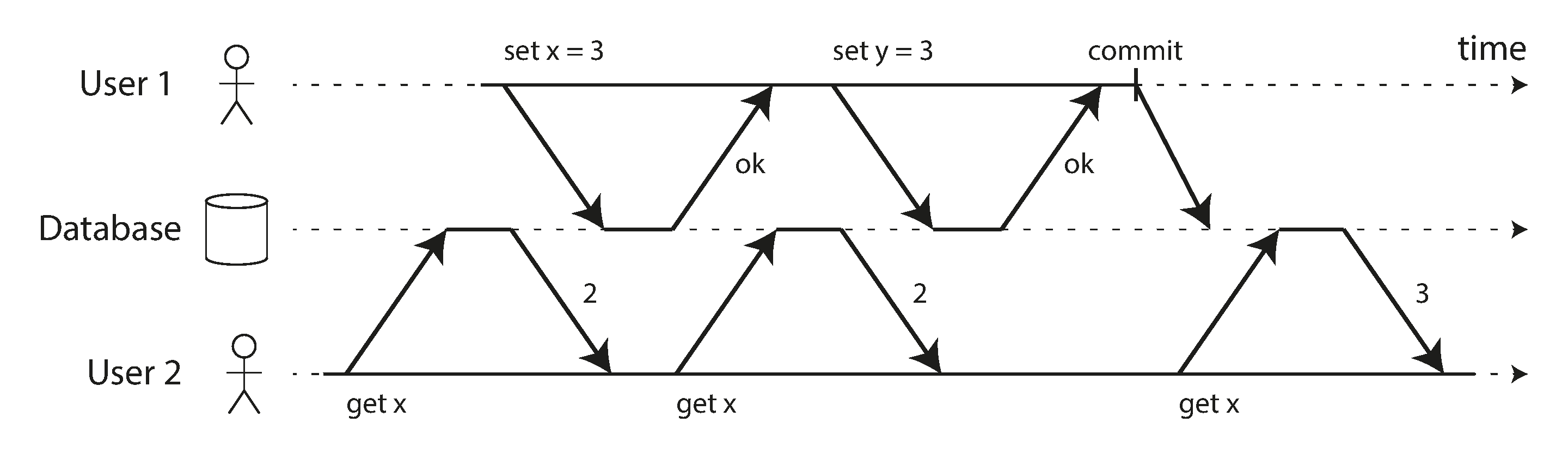
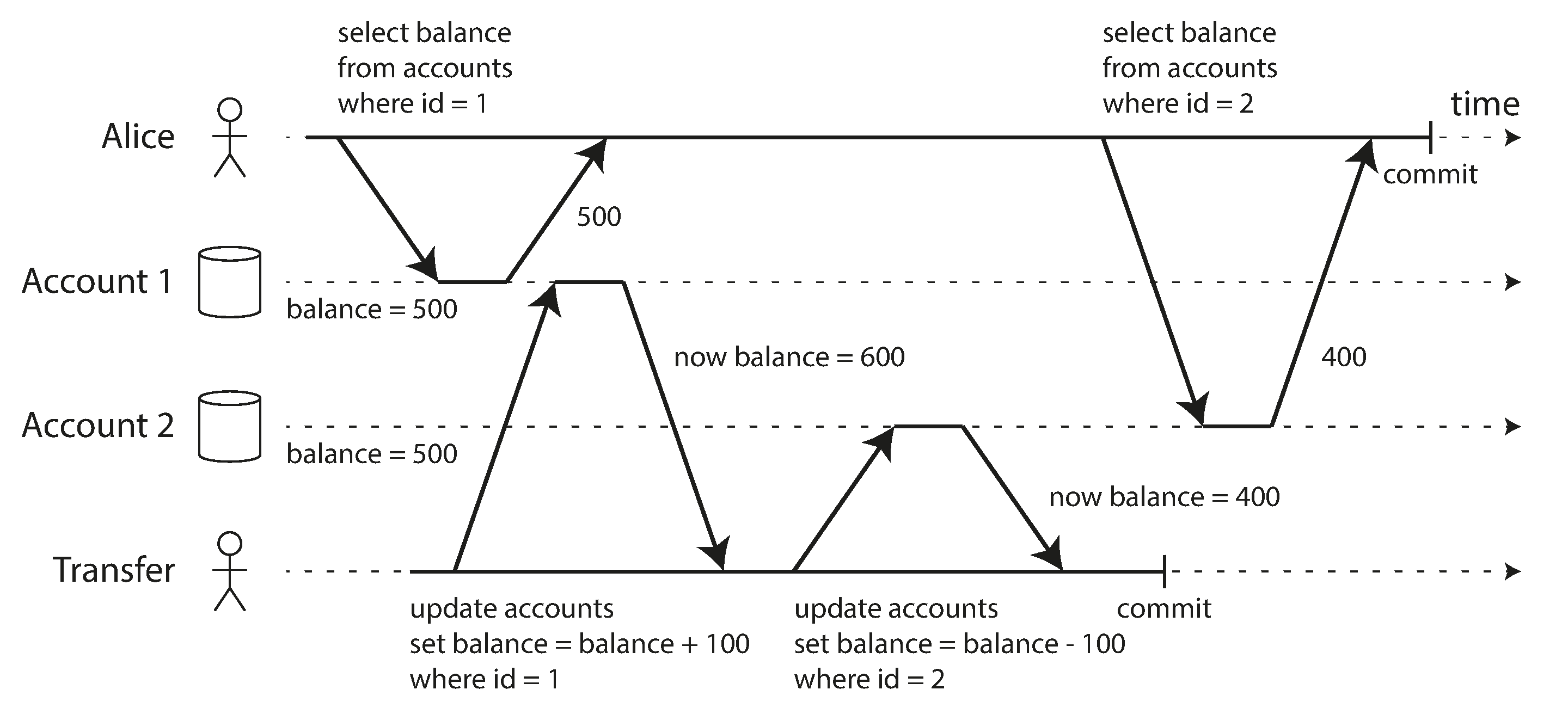
4.2.1 Issue with Read Committed
Read committed can still have concurrency bug
In the image above, there will be certain time the amount of 2 accounts are not equal to 1000
called read skew — nonrepeatable read
there will be temporary inconsistency
read the committed data by another transaction
But there are certain situations, that cannot tolerate such temporary inconsistency
Backup
Taking a backup requires making a copy of the entire database, which may take hours on a large database. During the time that the backup process is running, writes will continue to be made to the database. Thus, you could end up with some parts of the backup containing an older version of the data, and other parts containing a newer version. If you need to restore from such a backup, the inconsistencies (such as disappearing money) become permanent.
Analytic queries and integrity checks
nonsensical results will be returned if the database is at different points in time
4.2.2 Solution: Snapshot isolation
Each transaction reads from a consistent snapshot of the database,
the transaction sees all the data that was committed in the db at the start of the transaction
4.2.3 Snapshot Isolation Implementation
Use write locks to prevent dirty writes
a transaction that makes a write can block the progress of another transaction that writes to the same object
reads do not require any locks.
From a performance point of view, a key principle of snapshot isolation is readers never block writers, and writers never block readers
This allows a database to handle long-running read queries on a consistent snapshot at the same time as processing writes normally, without any lock contention between the two.
To implement snapshot isolation, db uses a generalization of the mechanism
db must potentially keep several different committed versions of an object, because various in progress transactions may need to see the state of the db at different points in time
— named as multi version concurrency control — MVCC
If a database only needed to provide read committed isolation, but not snapshot isolation, it would be sufficient to keep two versions of an object:
the committed version and the overwritten-but-not-yet-committed version.
However, storage engines that support snapshot isolation typically use MVCC for their read committed isolation level as well.
A typical approach is that read committed uses a separate snapshot for each query, while snapshot isolation uses the same snapshot for an entire transaction.
4.2.4 Visibility rules for observing a consistent snapshot
Transaction IDs are used to decide which objects it can see and which are invisible
Rules
At the start of each transaction, the database makes a list of all the other transactions that are in progress (not yet committed or aborted) at that time. Any writes that those transactions have made are ignored, even if the transactions subsequently commit.
Any writes made by aborted transactions are ignored.
Any writes made by transactions with a later transaction ID (i.e., which started after the current transaction started) are ignored, regardless of whether those transactions have committed.
All other writes are visible to the application’s queries.
4.3 Preventing Lost Updates
4.3.1 Issues
The lost update problem can occur if an application reads some value from the database, modifies it, and writes back the modified value (a read-modify-write cycle). If two transactions do this concurrently, one of the modifications can be lost, because the second write does not include the first modification. (We sometimes say that the later write clobbers the earlier write.) This pattern occurs in various different scenarios:
Incrementing a counter or updating an account balance (requires reading the current value, calculating the new value, and writing back the updated value)
Making a local change to a complex value, e.g., adding an element to a list within a JSON document (requires parsing the document, making the change, and writing back the modified document)
Two users editing a wiki page at the same time, where each user saves their changes by sending the entire page contents to the server, overwriting whatever is currently in the database
4.3.2 Solution 1: Atomic Write Operations
Using atomic update provided by database,
UPDATE counters SET value = value + 1 WHERE key = 'foo';
Atomic operations are usually implemented by taking an exclusive lock on the object when it is read so that no other transaction can read it until the update has been applied
Also, we could force all atomic operations to be executed on a single thread
4.3.3 Solution 2: Explicit Locking
Explicitly lock objects that are going to be updated
then the application can perform a read modify write cycle
if any other transaction tries to concurrently read the same object, it is forced to wait until the first read-modify-write cycle has completed
BEGIN TRANSACTION;SELECT * FROM figures WHERE name = 'robot' AND game_id = 222// For Update will let databse take a lock o FOR UPDATE; 1-- Check whether move is valid, then update the position-- of the piece that was returned by the previous SELECT.UPDATE figures SET position = 'c4' WHERE id = 1234;COMMIT;
4.3.4 Solution 3: Automatically detecting lost updates
Atomic operations and locks are ways of preventing lost updates by forcing the read-modify-write cycles to happen sequentially.
An alternative is to allow them to execute in parallel and, if the transaction manager detects a lost update, abort the transaction and force it to retry its read-modify-write cycle.
Lost update detection is great because it doesn’t require application code to use any special database features, you could forget to use a lock or an atomic operation, but lost update detection happens automatically and thus less error prone
4.3.5 Solution 4: Compare and set
Avoid lost updates by allowing an update to happen only if the value has not changed since you last read it
UPDATE wiki_pages SET content = 'new content' WHERE id = 1234 AND content = 'old content';
But notice the compare and set operation is possible to be unsafe if db by default read from the old snapshot
4.3.6 Solution 5: Conflict resolution and replication
In multi leader or leaderless replication system, a common approach in such replicated databases is to allow concurrent writes to create several conflicting versions of a value (also known as siblings), and to use application code or special data structures to resolve and merge these versions after the fact.
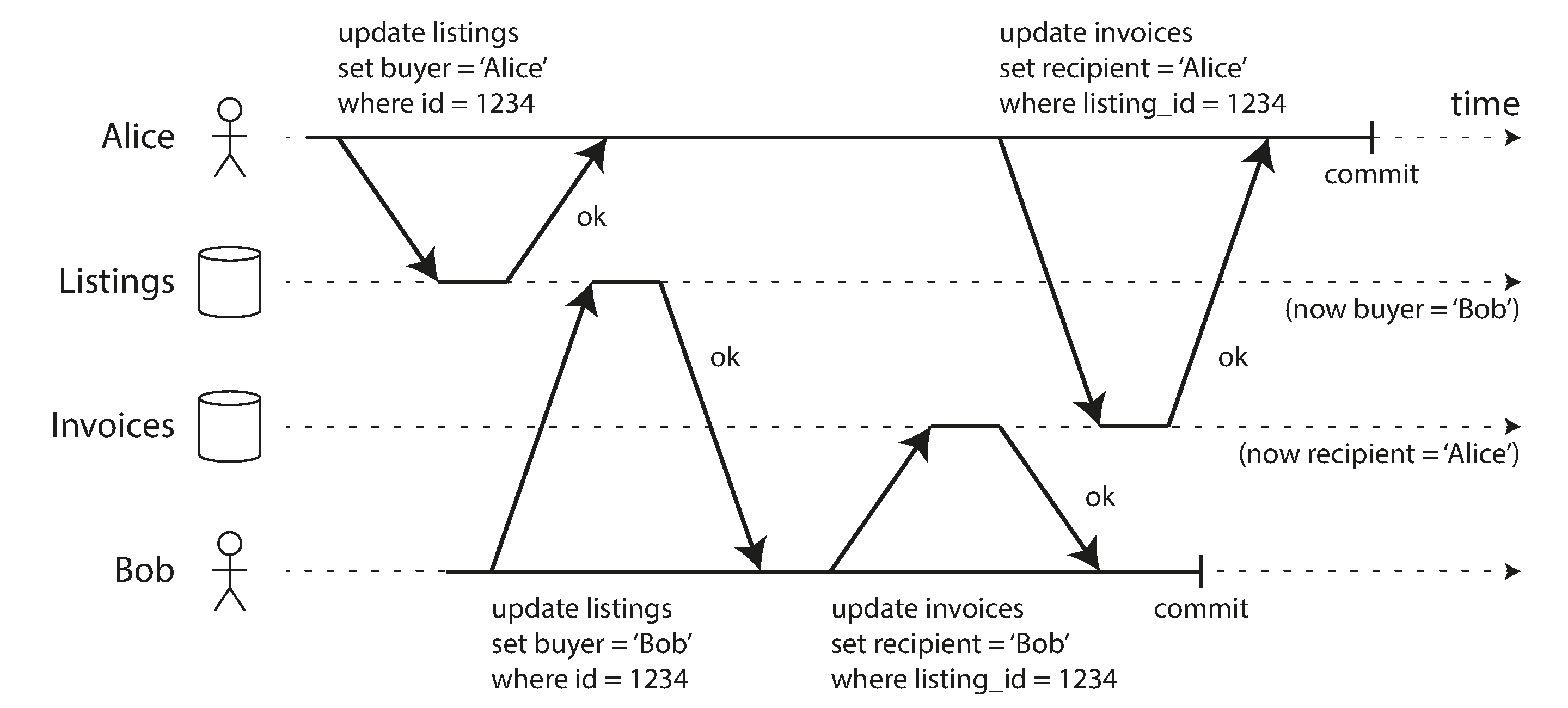
4.4 Write Skew and Phantoms
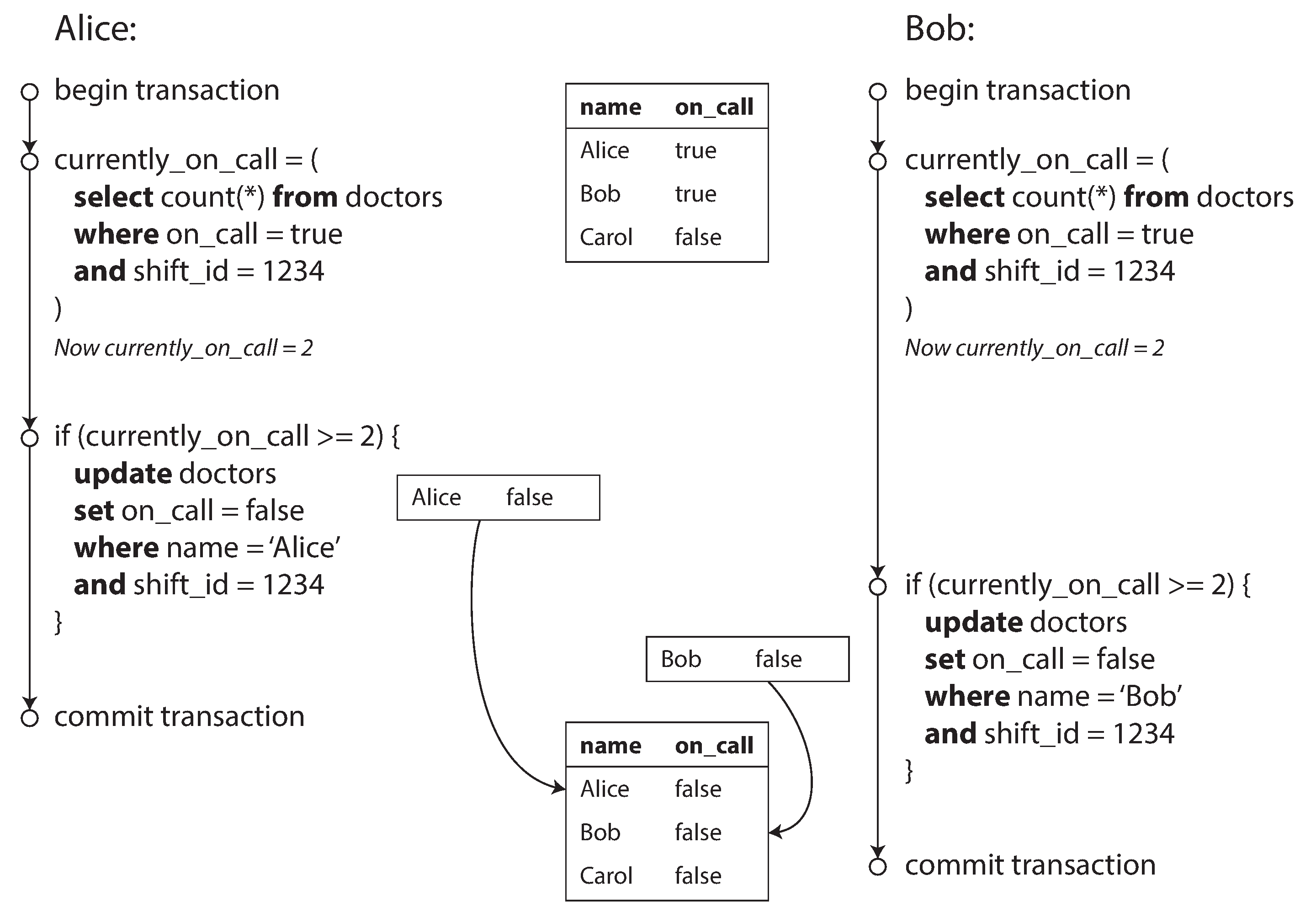
In each transaction, we first check that two or more doctors are currently on call,
since db is using snapshot isolation, both checks return 2, so both of them proceed to the next stage
Write Skew
it’s neither a dirty write nor a lost update, because the two transactions are updating two different objects
But it’s a race condition as the anomalous behavior was only possible because the transactions ran concurrently
You can think of write skew as a generalization of the lost update problem.
Write skew can occur if two transactions read the same objects, and then update some of those objects (different transactions may update different objects).
In the special case where different transactions update the same object, you get a dirty write or lost update anomaly (depending on the timing).
4.4.2 Solution
We need to explicitly lock the rows as solution in isolation snapshot works for one object, now the case come to be multiple objects, so that comes to be different
BEGIN TRANSACTION;SELECT * FROM doctors WHERE on_call = true AND shift_id = 1234 FOR UPDATE; 1UPDATE doctors SET on_call = false WHERE name = 'Alice' AND shift_id = 1234;COMMIT;
4.4.3 Phantoms
All of these examples follow a similar pattern:
A SELECT query checks whether some requirement is satisfied by searching for rows that match some search condition (there are at least two doctors on call, there are no existing bookings for that room at that time, the position on the board doesn’t already have another figure on it, the username isn’t already taken, there is still money in the account).
Depending on the result of the first query, the application code decides how to continue (perhaps to go ahead with the operation, or perhaps to report an error to the user and abort).
If the application decides to go ahead, it makes a write (INSERT, UPDATE, or DELETE) to the database and commits the transaction.
The effect of this write changes the precondition of the decision of step 2. In other words, if you were to repeat the SELECT query from step 1 after committing the write, you would get a different result, because the write changed the set of rows matching the search condition (there is now one fewer doctor on call, the meeting room is now booked for that time, the position on the board is now taken by the figure that was moved, the username is now taken, there is now less money in the account).
The steps may occur in a different order. For example, you could first make the write, then the SELECT query, and finally decide whether to abort or commit based on the result of the query.
In the case of the doctor on call example, the row being modified in step 3 was one of the rows returned in step 1, so we could make the transaction safe and avoid write skew by locking the rows in step 1 (SELECT FOR UPDATE). However, the other four examples are different: they check for the absence of rows matching some search condition, and the write adds a row matching the same condition. If the query in step 1 doesn’t return any rows, SELECT FOR UPDATE can’t attach locks to anything.
This effect, where a write in one transaction changes the result of a search query in another transaction, is called a phantom [3]. Snapshot isolation avoids phantoms in read-only queries, but in read-write transactions like the examples we discussed, phantoms can lead to particularly tricky cases of write skew.
4.4.4 Materializing conflicts for Phantoms
Pre create all rows in the db, thus phantoms problems could be converted to the doctor appointment problem we discussed before
4.4.5 Predicate Locks
We could use a predicate lock for booking case, works similarly to the shared/ exclusive lock, but rather than belong to a particular object, it belongs to all objects that match some search condition
SELECT * FROM bookings WHERE room_id = 123 AND end_time > '2018-01-01 12:00' AND start_time < '2018-01-01 13:00';
If transaction A wants to read objects matching some condition, like in that SELECT query, it must acquire a shared-mode predicate lock on the conditions of the query. If another transaction B currently has an exclusive lock on any object matching those conditions, A must wait until B releases its lock before it is allowed to make its query.
If transaction A wants to insert, update, or delete any object, it must first check whether either the old or the new value matches any existing predicate lock. If there is a matching predicate lock held by transaction B, then A must wait until B has committed or aborted before it can continue.
4.5 Serializability
There are a lot of different isolation levels, and each db declare their isolation level slightly different,
We could use serializable isolation to simplify it
Serializable isolation
Strongest isolation level
without any concurrency
Serializable Mechanism
Literally executing transactions in a serail order
Two Phase Locking
Optimistic concurrency control techniques such as serializable snapshot isolation
4.5.1 Actual Serial Execution
We could try to only execute one transaction at a time, in serial order, on a single thread
This comes to be realistic recently around 2007 because
RAM became cheap enough, thus it’s now feasible to keep the entire active dataset in memory
OLTP transactions are usually short and only make a small number of reads and writes
by contrast, long running analytic queries are typically read only, so they can be run on a consistent snapshot outside of the serial execution loop
This approach is implemented in VoltDB/ Hstore, Redis, and Datomic
Notice
A system designed for a single threaded execution can sometimes perform better than a system that supports concurrency, because it can avoid the coordination overhead of locking
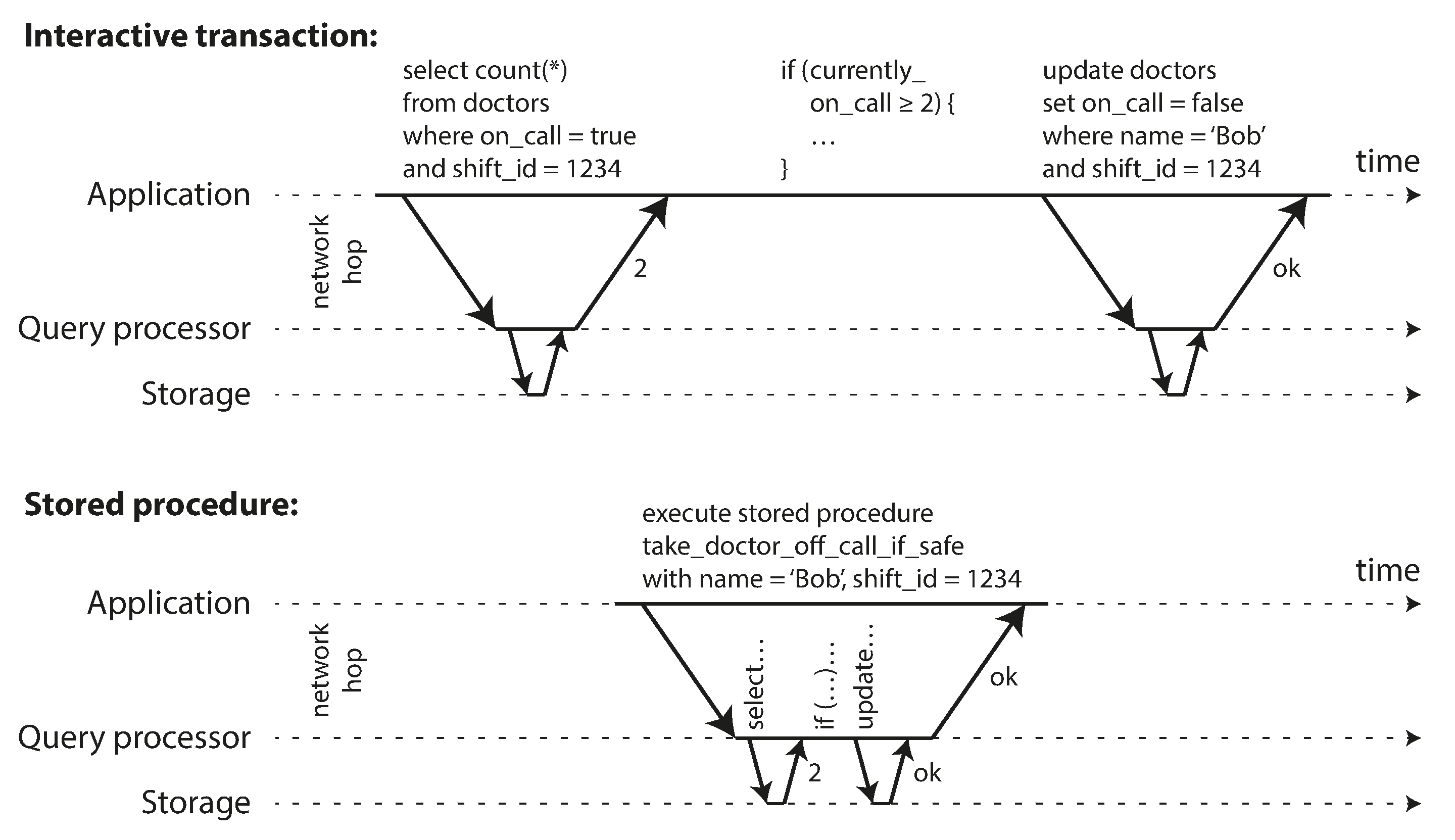
4.5.2 Encapsulating transactions in stored procedures
Philosophy
Keep transactions short by avoiding interactively waiting for a user within a transaction
means a transaction is committed within the same HTTP request,
IN the interactive style of transaction, network and db will take a lot time, we need to make sure we could handle enough throughput, we need to process multiple transactions concurrently in order to get reasonable performance.
Systems with single threaded serial transaction processing could receive the entier transaction code to db ahead of time , as a stored procedure
Pros and Cons
Each db has its own language for stored procedures
Code running in db is difficult to manage, more awkward to keep in version control and deploy
db is often much more performance sensitive,because a single db instance is often shared by a lot of application servers. A bad written stored procedure can cause much more trouble than equivalent badly written code in an application server
4.5.3 Partitioning
Partition data to scale to multiple CPU cores, and multiple nodes.
However, for any transaction that needs to access multiple partitions, the database must coordinate the transaction across all the partitions that it touches. The stored procedure needs to be performed in lock-step across all partitions to ensure serializability across the whole system.
5. Two Phase Locking
5.1 Concepts
Several transactions are allowed to concurrently read the same object as long as nobody is writing to it
But as soon as anyone wants to write(modify or delete) an object, exclusive access is required
Writes not only block other writers, it also block all readers
5.2 Implementation
If a transaction wants to read an object, it must first acquire the lock in shared mode. Several transactions are allowed to hold the lock in shared mode simultaneously, but if another transaction already has an exclusive lock on the object, these transactions must wait.
If a transaction wants to write to an object, it must first acquire the lock in exclusive mode. No other transaction may hold the lock at the same time (either in shared or in exclusive mode), so if there is any existing lock on the object, the transaction must wait.
If a transaction first reads and then writes an object, it may upgrade its shared lock to an exclusive lock. The upgrade works the same as getting an exclusive lock directly.
After a transaction has acquired the lock, it must continue to hold the lock until the end of the transaction (commit or abort). This is where the name “two-phase” comes from: the first phase (while the transaction is executing) is when the locks are acquired, and the second phase (at the end of the transaction) is when all the locks are released.
5.3 Performance
transaction throughput and response times of queries are significantly worse under two-phase locking than under weak isolation.
overhead of acquiring and releasing all those locks, but more importantly due to reduced concurrency.
6. Serializable Snapshot Isolation
It provides full serializability, but has only a small performance penalty compared to snapshot isolation
Snapshot + Serializable
optimistic concurrency control mechanism
It performs badly if there is high contention (many transactions trying to access the same objects), as this leads to a high proportion of transactions needing to abort. If the system is already close to its maximum throughput, the additional transaction load from retried transactions can make performance worse.
to achieve serialization, db need to know if the query result has been changed within the transaction
Detecting reads of a stale MVCC object version (uncommitted write occurred before the read)
Detecting writes that affect prior reads (the write occurs after the read)
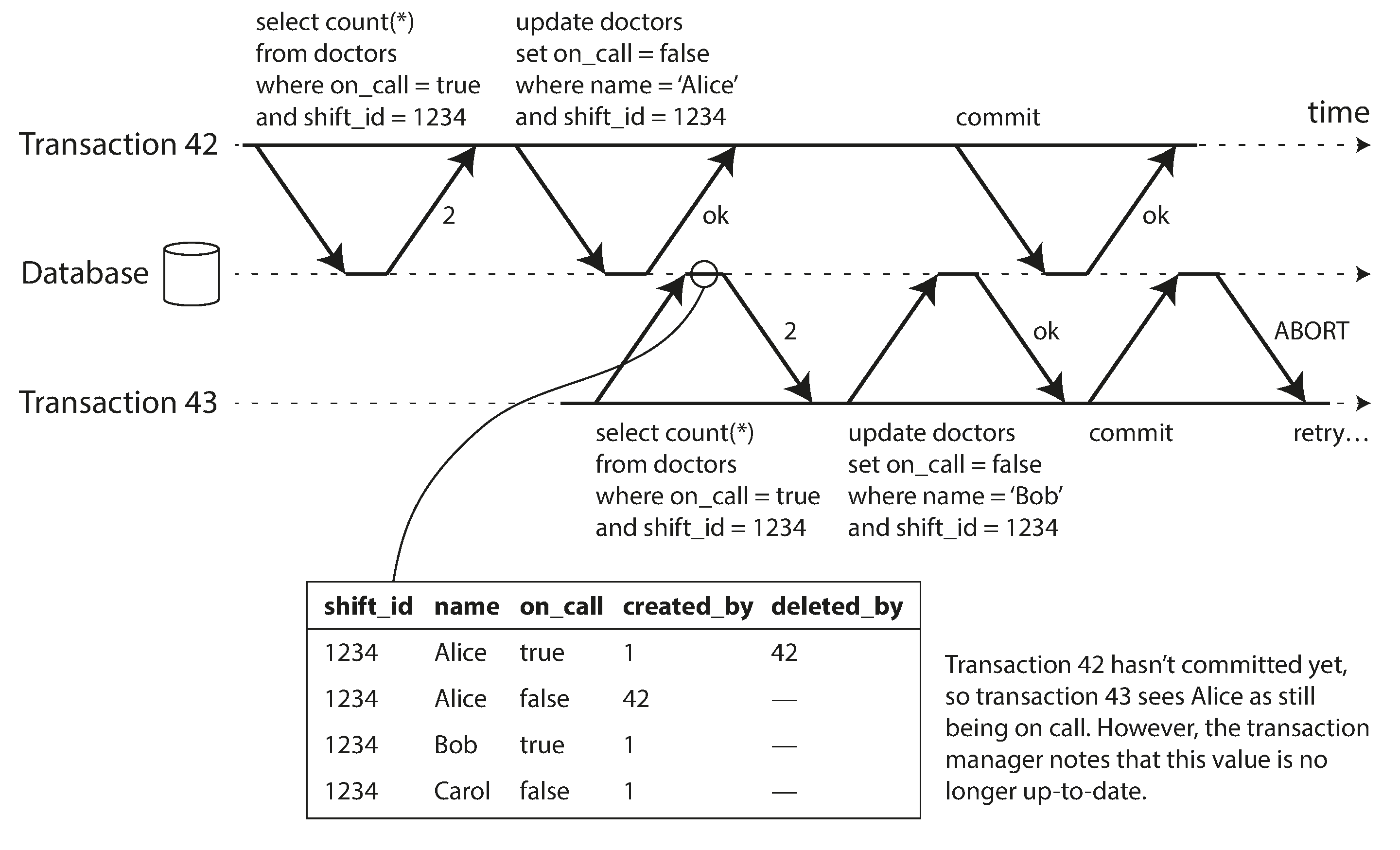
6.1 Detecting stale MVCC reads
In order to prevent this anomaly, the database needs to track when a transaction ignores another transaction’s writes due to MVCC visibility rules. When the transaction wants to commit, the database checks whether any of the ignored writes have now been committed. If so, the transaction must be aborted.
6.2 Detecting writes that affect prior reads
When a transaction writes to the database, it must look in the indexes for any other transactions that have recently read the affected data. This process is similar to acquiring a write lock on the affected key range, but rather than blocking until the readers have committed, the lock acts as a tripwire: it simply notifies the transactions that the data they read may no longer be up to date.
6.3 Performance
Compared to two-phase locking, the big advantage of serializable snapshot isolation is that one transaction doesn’t need to block waiting for locks held by another transaction. Like under snapshot isolation, writers don’t block readers, and vice versa. This design principle makes query latency much more predictable and less variable. In particular, read-only queries can run on a consistent snapshot without requiring any locks, which is very appealing for read-heavy workloads.
]]>
<ul>
<li>软件活动的根本任务<ul>
<li>打造构成抽象软件实体的复杂概念结构</li>
</ul>
</li>
<li>软件活动的次要任务1<ul>
<li>使用编程语言来表达这些抽象实体,在空间和时间的限制下将他们映射成机器语言</li>
</ul>
</li>
<
Real time data’s unifying abstractionhttps://www.llchen60.com/Real-time-data%E2%80%99s-unifying-abstraction/2022-01-29T02:14:20.000Z2022-01-29T02:20:03.851ZReal time data’s unifying abstraction
1. Overview
Logs play a key role in distributed data systems and real time application architectures.
write ahead log
commit log
transaction logs
2. What is a log?
2.1 Some Concepts
Storage abstraction
append only
totally ordered sequence of records ordered by time
Records
appended to the end of the log
read from left to right
each entry has a unique sequential log entry number
Log
record what happened and when
for distributed system, that’s the very heart of the problem
types
text logs
meant primarily for humans to read
journal/ data logs
built for programmatic access
2.2 Log in different scenario
2.2.1 Logs in DB
Function 1: Authoritative source for restoring data
DB need to keep in sync the variety of data structures and indexes in the presense of crashes
To make this atomic and durable, a db uses a log to write out information about the records they will be modifying, before applying the changes to all the various data structures it maintains
Since the log is immediately persisted it is used as the authoritative source in restoring all other persistent structures in the event of a crash.
Function 2: Replicating data between DBs
Oracle, MySQL and Postgres SQL include log shipping protocols to transmit portions of log to replica databases which act as slaves
2.2.2 Logs in distributed systems
Log Centric Approach
we could reduce the problem of making multiple machines all do the same thing to the problem of implementing a distributed consistent log to feed these processes input
squeeze all the non-determinism out of the input stream to ensure that each replica processing this input stays in sync.
time stamps that index the log now act as the clock for the state of the replicas—you can describe each replica by a single number, the timestamp for the maximum log entry it has processed.
3. Log Types
What we could put in log
log the incoming requests to a service
the state changes the service undergoes in response to request
the transformation commands it executes.
For DB usage
physical logging
log the contents of each row that is changed
logical logging
log not the changed rows but the SQL commands that lead to the row chagnes
For Distributed Systems to process and replicate
Primary Backup
elect one replica as the leader
allow this leader to process requests in the order they arrive
log out the changes to its state from processing the requests.
The other replicas apply in order the state changes the leader makes so that they will be in sync and ready to take over as leader should the leader fail.
backup will copy the result from the primary, no logical action to walk through all action primary did
- State Machine Replication - active-active model where we keep a log of the incoming requests and each replica processes each request - **each machine will do real execution, do the logical stuff** 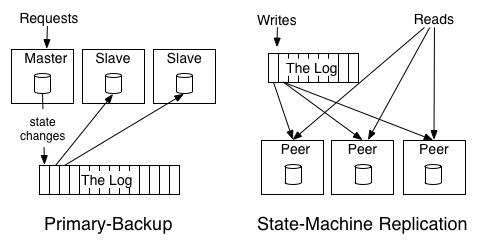
4. Changelog in Database
duality between a log of changes and a table
The log is similar to the list of all credits and debits and bank processes;
a table is all the current account balances.
If you have a log of changes, you can apply these changes in order to create the table capturing the current state.
if you have a table taking updates, you can record these changes and publish a “changelog” of all the updates to the state of the table. This changelog is exactly what you need to support near-real-time replicas.
Table support data at rest and logs capture changes
5. Data Integration
Make all of an organization’s data easily available in all its storage and processing systems
5.1 Expected workflow for data integration
Definition in author’s scope: Making all the data an organization has available in all its services and systems.
Effective Use of Data
Capture all relevant data
Put it together in an applicable processing env
real time query system
text files
python scripts, etc.
Infra to process data
mapReduce
Real time query systems
Good data models and consistent well understood semantics
Sophisticated processing
visualization
reporting
algorithmic processing and prediction
5.2 Problem1: The event data firehose
Event data rising
google’s fortune is actually generated by a relevance pipeline built on clicks and impressions — events
that would be huge amount of data,
5.3 Problem 2: The explosion of specialized data systems
Explosion of specialized data systems
The combination of more data of more varieties and a desire to get this data into more systems leads to a huge data integration problem.
5.4 Log Structured Data Flow
5.4.1 How the flow work
Recipe: Take all the organization’s data and put it into a central log for real time subscription
How the flow works
Each logical data source can be modeled as its own log
A data source could be an application that logs out events, or a db table that accepts modifications
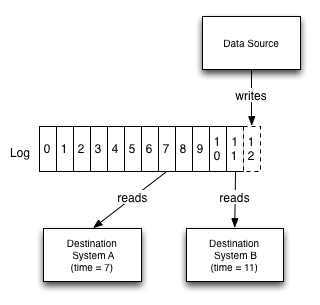
each subscribing system reads from this log as quickly as it can, applied each new record to its own store, and advances its position in the log
Log gives a logical clock for each change against which all subscriber can be measured
Consider a case where there is a database and a collection of caching servers
log provides a way to synchronize the updates to all these systems and reason about the point of time of each of these systems
Let’s say we write a record with log entry X and then need to do a read from the cache. If we want to guarantee we don’t see stale data, we just need to ensure we don’t read from any cache which has not replicated up to X.
Log also acts as a buffer that makes data production asynchronous from data consumption
satisfy different requirements like
A batch system such as Hadoop or a data warehouse may consume only hourly or daily,
A real-time query system may need to be up-to-the-second.
Consumer only need to know about the log and not any details of the system of origin
What values most from author perspective
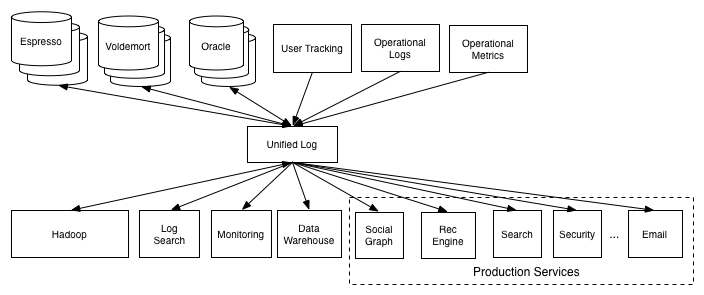
The pipeline they built for process data, though a bit of a mess, were actually extremely valuable . Just the process of makeing data available in a new processing system (Hadoop) unblocked a lot of possibilities
Many new products and analysis just came from putting together multiple pieces of data that had previously been locked up in specialized systems
LinkedIn Went Through from O(N^2) to O(2N)
Actions for the migration
Isolate each consumer from the source of the data
Create a new data system to be both a data source and a data destination
Here LinkedIn create Kafka
Kinesis is similar to Kafka as AWS use it to connects all different distributed systems as a piping
5.4.2 Relationship to ETL and the Data Warehouse
Data Warehouse
target
A repository of the clean, integrated data structured to support analysis
what be involved
periodically extracting data from source databases
munging it into some kind of understandable form
loading it into a central data warehouse
Problems
coupling the clean integrated data to the data warehouse.
cannot get real time feed
organization perspective
The incentives are not aligned: data producers are often not very aware of the use of the data in the data warehouse and end up creating data that is hard to extract or requires heavy, hard to scale transformation to get into usable form.
the central team never quite manages to scale to match the pace of the rest of the organization, so data coverage is always spotty, data flow is fragile, and changes are slow.
ETL
tasks
extraction and data cleanup process, liberating data locked up in a variety of systems in the organization and removing an system-specific non-sense
data is restructured for data warehousing queries (i.e. made to fit the type system of a relational DB, forced into a star or snowflake schema, perhaps broken up into a high performance columnformat,
problems
still, we need such data in real time as well for low latency processing as well as indexing in real time storage systems
A better approach as ETL and Data Warehouse substitution
Have a central pipeline, the log, with a well defined API for adding data
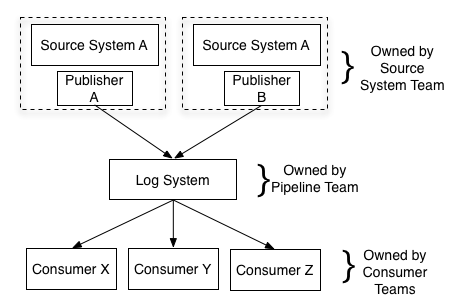
Responsibility Classification
Producer of the data feed: integrating with this pipeline and providing a clean, well-structured data feed
Datawarehouse team now only care about loading structured feeds of data from the central log and carrying out transformation specific to their system
5.4.3 Log Files and Events
Current structure also enables decoupled and event driven systems
5.4.4 How to build scalable logs
Need a log system that’s fast, cheap, scalable enough to make this practical at scale
LinkedIn in 2013 actually has already support 60 billion unique message writes through Kafka per day
Kafka achieve such high throughput via
Partitioning the log
each partition is a totally ordered log, but there is no global ordering between partitions
Assignment of the messages to a particular partition is controllable by the writer, with most users choosing to partition by some kind of key
Replication
Each partition is replicated across a configurable number of replicas
At any time, a single one of them will act as the leader, if the leader fails, one of the replicas will take over as leader
Order Guarantee
each partition is order preserving, and Kafka guarantees that appends to a particular partition from a single sender will be delivered in the order they are sent.
Optimizing throughput by batching reads and writes
occurs when
sending data
writes to disk
replication between servers
data transfer to consumers
acknowledging committed data
Avoiding needless data copies
Use a simple binary format that is maintained between in memory log, on disk log and in network data transfers
computational model can be general like MapReduce or other distributed processing frameworks,
need the ability to produce low latency results
Instead of batch get and process, we could do continuous changes
it is just processing which includes a notion of time in the underlying data being processed and does not require a static snapshot of the data so it can produce output at a user-controlled frequency instead of waiting for the “end” of the data set to be reached. In this sense, stream processing is a generalization of batch processing, and, given the prevalence of real-time data, a very important generalization
Log role
making data available in real-time multi-subscriber data feeds.
6.2 Stateful Real Time Processing
Stateful real time processing means some more sophisticated operations, like counts, aggregations, or joins over windows in the stream
We need to maintain certain state in such case
Strategies for that
Keep state in memory
cons
if the process crash, it would lose its intermediate state
if the state is only maintained over a window, the process could fall back to the point where the window began
Store all state in a remote storage system, and join over the network to that store
cons
no locality of data and lots of network round trips
Duality of tables and logs
a stream processor can keep its state in a local table or index — a bdb, leveldb
the contents of this store is fed from its input streams
it could journal out a changelog for this local index it keeps to allow it to restore its state in the event of a crash and restart
This mechanism allows a generic mechanism for keeping co-partitioned state in arbitrary index types local with the incoming stream data.
when facing process fails
recover its index from the changelog
changelog itself is the transformation of the local state into a sort of incremental record at a time backup
6.3 Log Compaction
Log need to be cleaned up someway to save the space
In Kafka, clean up has two options depending on whether the data contains keyed updates or event data
for event data, supports just retain a window of data
configured to be few days
also could be configured as space
for keyed data
as the complete log give you ability to replay it to recreate the state of the source system
but we could do log compaction by removing obsolete records — records whose primary key has a more recent update
7. Distributed System Design
How practical systems can be simplified with a log centric design
7.1 Distributed system design thought
Log here is responsible for data flow, consistency and recovery
Directions
Coalescing lots of little instances of each system into a few big clusters
Possibility 1
separation of systems remains more or less as it is for a good deal longer.
an external log that integrates data will be very important.
Possibility 2
re-consolidation in which a single system with enough generality starts to merge back in all the different functions into a single uber-system.
extremely hard
Possibility 3
data infrastructure could be unbundled into a collection of services and application-facing system apis
use open source, like in Java stacks
zookeeper
handle system coordination
mesos and yarn
process virtualization
resource management
netty, jetty
handle remote communication
protobuf
handle serialization
kafka and bookeeper
provide a backing log
path towards getting the simplicity of the single system in a more diverse and modular world that continues to evolve. If the implementation time for a distributed system goes from years to weeks because reliable, flexible building blocks emerge, then the pressure to coalesce into a single monolithic system disappears.
7.2 Usage of log in system architecture
Usage of log in system architecture
Handle data consistency (whether eventual or immediate) by sequencing concurrent updates to nodes
Provide data replication between nodes
Provide “commit” semantics to the writer (i.e. acknowledging only when your write guaranteed not to be lost)
Provide the external data subscription feed from the system
Provide the capability to restore failed replicas that lost their data or bootstrap new replicas
Handle rebalancing of data between nodes.
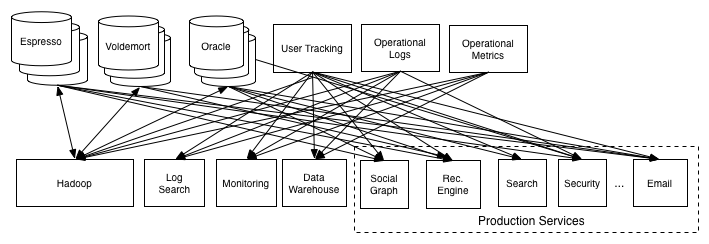
What mentioned above is actually a large portion of what a distributed data system does. left over is mainly related with client facing query API and indexing strategy
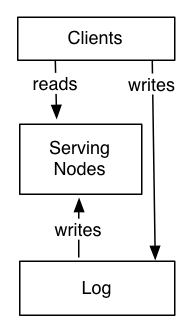
System Look
System is divided into two logical pieces
log
capture the state changes in sequential order
serving layer
store whatever index is required to serve queries
writes could go directly to the log or may be proxied by the serving layer
writes to the log yields a logical timestamp, if the system is partitioned, then the log and serving nodes will have the same number of partitions, though they may have very different numbers of machines
The client can get read-your-write semantics from any node by providing the timestamp of a write as part of its query—a serving node receiving such a query will compare the desired timestamp to its own index point and if necessary delay the request until it has indexed up to at least that time to avoid serving stale data.
For handling restoring failed nodes or moving partitions from node to node
have the log retain only a fixed window of data and combine this with a snapshot of the data stored in the partition
it’s possible for the log to retain a complete copy of data and garbage collect the log itself
]]>
<h1 id="Real-time-data’s-unifying-abstraction"><a href="#Real-time-data’s-unifying-abstraction" class="headerlink" title="Real time data’s u
Flywayhttps://www.llchen60.com/Flyway/2022-01-01T13:57:09.000Z2022-01-01T13:57:52.879Z1. Overview
An open source database migration tool
Favors simplicity and convention over configuration
has 7 basic commands
migrate
clean
info
validate
undo
baseline
repair
1.1 Why DB migrations?
we need a way to version the table
we need to know what state is the db on this machine
database migration help us
recreate a database from scratch
make it clear at all times what state a database is in
migrate in a deterministic way from your current version of the database to a newer one
1.2 How Flyway works?
Flyway first try to locate its schema history table
if db empty, then flyway will create it instead
this default db named as flyway_schema_history
Then flyway will begin scanning the filesystem or the classpath of the application for migrations
The migrations are then sorted based on the version number and applied in order
The schema history table will be updated accordingly as each migration gets applied
we use flyway migrate to execute the migration
2. Flyway Commands
2.1 migrate
help migrate the db
2.2 clean
drop all objects in the confgured schemas
2.3 info
print the details and status information about all migrations
2.4 validate
validates the applied migrations against the ones available on the classpath
2.5 undo
undoes the most recently applied versioned migration
2.6 baseline
baselines an existing database, excluding all migrations up and including baseline version
2.7 repair
repair the schema history table
3. Concepts
3.1 Migrations
all changes to the db are called migrations
migrations can be
versioned
types
regular
undo
the effect can be undone by supplying an undo migration
contains
version
must be unique
description
purely informative for you to be able to remember what each migration does
checksum
detect accidental changes
repeatable
contains
description
checksum
instead of being run just once, they are re-applied every time their checksum changes
Within a single migration run, repeatable migrations are always applied last, after all pending versioned migrations have been executed. Repeatable migrations are applied in the order of their description
3.1.1 Versioned Migrations
contains
version
must be unique
applied in order exactly once
description
purely informative for you to be able to remember what each migration does
A migration can fail at any point. If you have 10 statements, it is possible for the 1st, the 5th, the 7th or the 10th to fail. There is simply no way to know in advance. In contrast, undo migrations are written to undo an entire versioned migration and will not help under such conditions.
we should maintain backwards compatibility between the DB and all versions of the code currently deployed in production
3.1.3 Repeatable Migrations
contains
description and a checksum, but no version
repeatable migrations are re-applied every time their checksum changes
Very useful for managing database objects whose definition can then simply be maintained in a single file in version control
Repeatable migrations are always applied last, after all pending versioned migrations have been executed; always applied in the order of their description
3.1.4 SQL Based Migrations
used for
DDL change — CREATE/ALTER/DROP statements for TABLES,VIEWS,TRIGGERS,SEQUENCES,…
Simple reference data changes
simple bulk data changes
Naming Patterns
Prefix
v for versioned
u for undo
r for repeatable migrations
version
with dots or underscores separate as many parts as you like
Separator
__ two underscores
Suffix
.sql
Discovery
Flyway discover sql migrations from directories referenced by the location property
3.1.5 Script Based Migrations
name patten
``V1__execute_batch_tool.sh`
could be used for
triggering execution of a 3rd party application as part of the migrations
cleaning up local files
3.1.6 Transactions
By default, Flyway wraps the execution of an entire migration within a single transaction
3.2 Callbacks
For the case we need to execute same action over and over again
we could hook into its lifecycle
there are certain keywords we could use, and invoke them during the process
By default, in case an error is returned, flyway displays it with all necessary details, marks the migration as failed and automatically rolls it back if possible
But we could change the behavior like
treat an error as a waring
treat a waring as an error
perform an additional action
3.4 Dry Runs
Used for
preview changes Flyway will make to the db
submit the SQL statements for review
use Flyway to determine what needs updating,
how it works
flyway sets up a read only connection to the db,
assesses what migrations need to run and generates a single SQL file containing all statements it would have executed in case of a regular migration run
3.5 Baseline Migrations
Over the lifetime of a project, there would be tons of db objects be created/ destroyed across many migrations
we want to simplify with a single, cumulative migration that represents the state of db after all of those migrations have been applied without disrupting existing env
How it works?
Prefixed with B followed by the version of your db they represent
Only used when deploying to new env
If used in an env where some Flyway migrations have already been applied, baseline migrations will be ignored,new env will choose the latest baseline migration as the starting point
every migration with a version below the latest baseline migration’s version is marked as ignored
baseline migration are executed during the migrate process
Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data – think XML, but smaller, faster, and simpler.
You define how you want your data to be structured once, then you use special generated source code to easily write and read your structured data
2. Why use Protocol Buffers?
XML is human readable and wide language supports
but is notoriously space intensive
encoding/ decoding can impose a huge performance penalty on applications
With protocol buffers
write a .proto description of the data structure
the protocol buffer compiler then creates a class that implements automatic encoding and parsing of the protocol buffer data with an efficient binary format
the generated class provides getters and setters for the fields
take care of the details of reading and writing the protocol buffer as a unit
3. Java Tutorial (In Proto2)
3.1 Define Protocol Format
syntax = "proto2";// starts with package delcaration // we should define this to get rid of name conflict package tutorial;// enable generating a separate .java file for each generated class option java_multiple_files = true;// specify in what java package name your generated classes should live// if not set here, it will simply match the pkg name given by the package declaration option java_package = "com.example.tutorial.protos";// define the class name of the wrapper class which will represent this file // if not given, it will be auto generated by converting the file name to upper camel case option java_outer_classname = "AddressBookProtos";/**Message Definition: An aggregate containing a set of typed fields Contain certain standard types + boo1 + int32 + float + double + string we could also add further structure to msgs by using other msg types as field types + marker + identify the unique tag field use in binary encoding + try to use 1 - 15 as it neeeds one less byte+ modifier + optional + field may or may not be set + if not, a default value will be used + we could set our own default values + or system will provide defaults + numeric types -- zero + strings -- empty string + bools -- false + embedded messages -- default instance or prototype of the message, which has none of its fields set + repeated + the field may be repeated any number of times [0, xxx) + order will be preserved in the protocol buffer + act like a dynamic sized array + required + a value for the field must be provided + try to build an uninitialized msg will throw runtime exception + parse an uninitialzied msg will throw IOException + required is not favored as it cannot be backward compatible */message Person { // =1 marker identify the unique tag that field uses in the binary encoding optional string name = 1; optional int32 id = 2; optional string email = 3; enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } message PhoneNumber { optional string number = 1; optional PhoneType type = 2 [default = HOME]; } repeated PhoneNumber phones = 4;}message AddressBook { repeated Person people = 1;}
3.2 Compiling Protocol Buffers
To generate the classes, we need to run the protocol buffer compiler
specify the source directory, the destination directory and the path to our .proto
we could define and use msg types inside other msg types
message SearchResponse { message Result { string url = 1; string title = 2; repeated string snippets = 3; } repeated Result results = 1;}// to use the msg type outside its parent message type message SomeOtherMessage { SearchResponse.Result result = 1;}
4.4 Updating a Message Type
don’t change the field numbers for any existing fields
if you add new fields, any msg serialized by code using your old msg format can still be parsed by your new generated code
keep in mind the default values for these elements so that new code can properly interact with msgs generated by old code
to remove a field
rename the field with prefix like OBSOLETE_
or make the filed number reserved,
int32, uint32, int64, uint64 and bool are all compatible
string and bytes are compatible as long as the bytes are valid UTF-8
4.5 Special Keywords
4.5.1 Any
let you use messages as embedded types without having their .proto definition
it contains an aribitrary serialized messages as bytes
4.5.2 Oneof
if we have a msg with many fields and where at most one field will be set at the same time, we can enforce the behavior and save memory by using the oneof feature
at most one field can be set at the same time
setting any member of the oneof automatically clears all the other members
4.6 Maps
map<key_type, value_type> map_field = N;
4.7 Define Service
If you want to use message types with an RPC system, we can define an RPC service interface in a .proto file
then the protocol buffer compiler will generate service interface code and stubs in chosen language
4.8 Options
Options do not change the overall meaning of a declaration, but may affect the way it is handled in a particular context.
java_package
pkg you want to use for your generated Java classes
java_outer_classname
class name for the wrapper java class you want to generate
java_multiple_files
optimize_for
SPEED
Compiler will generate code for serializing, parsing and performing other common operations on your msg types.
Code is highly optimized
CODE_SIZE
generate minimal classes
operations will be slower
LITE_RUNTIME
only depend on the lite runtime library
usefyl for apps running on constrained platform like mobile phones
]]>
<h1 id="Protobuf-Learning"><a href="#Protobuf-Learning" class="headerlink" title="Protobuf Learning"></a>Protobuf Learning</h1><h1 id="1-Wha
Bazel Introhttps://www.llchen60.com/Bazel-Intro/2021-12-22T02:05:15.000Z2021-12-22T02:07:14.224Z1. What is Bazel?
Bazel is a build and test tool built that supports building and testing multiple projects for multiple languages and build outputs
What
Build and Test tool similar to Make, Maven, Gradle
Caches all the previously done work, tests or builds faster everytime
Support multi languages, multi platforms,
Support large code base across multi repos
build, test, and query to trace dependencies in the code
Why
scales
multi platform
How
Need a BUILD file
2. Concepts
Workspace - With WORKSPACE
dir contains the source file
considered as root
WORKSPACE
a blank text file, which identifies the directory and its content as a Bazel workspace
at the root of the project’s directory structure
Repos - With WORKSPACE
External repos are defined in the WORKSPACE file using workspace rules
Packages - With BUILD
A package is defined as a directory containing a file named BUILD or BUILD.bazel
which reside beneath top level directory in the ws
This file has instructions on how to run or build or test the project
Rules
written using a DSL named Starlark
thus are built for certain language already like rules_java, etc.
Targets
Pkg is container, element of pkg —- target
Most targets are files or rules
File
source files - written by people
generated files — generated by build tool
rule
specify relationship between set of inputs and output
output are always generated files
3. Best Practices
A project should always be able to run bazel build //... and bazel test //...
You may declare third party dependencies
either declare them as remote repositories in the WORKSPACE file
or put them in a directory called third_party under workspace directory
everything should be built from source whenever possible, instead of depending on a library so file, we should create a BUILD file and build so from its sources, then depend on that target
for project specific options, use the configuration file under workspace/.bazelrc
every directory that contains buildable files should be a package
// generate graph for class in use, and output as a svg file bazel query --notool_deps --noimplicit_deps "deps(//booking)" --output graph > /Users/lchen1/Documents/bookingGraph.in dot -Tsvg < bookingGraph.in > graph.svg
4.2 Specify multiple build targets
Package Splits
for larger project, we may want to split into multiple targets and packages to allow for fast incremental builds, this could also speed up builds by building multiple parts of a project at once
java_binary( name = "ProjectRunner", srcs = ["src/main/java/com/example/ProjectRunner.java"], main_class = "com.example.ProjectRunner", deps = [":greeter"],)java_library( name = "greeter", srcs = ["src/main/java/com/example/Greeting.java"],)
with this configuration, bazel will first build greeter library, then the projectRunner binary
deps attribute tells bazel the greeter library is required to build the projectRunner binary
when referencing targets within the same BUILD file, we can skip the // workspace root identifier and just use :target_name
5. E.G
java_binary
pre defined rule telling bazel to create a binary when a target is invoked
java_binary( // target name name = "mymain", // all source files, passed as glob, inside the fully qualified directory names on classpath srcs = glob(["src/main/java/com/abhi/*.java"]), // main runner class main_class = "com.abhi.MyMain", // dependent classes/ interfaces to be included, not part of srcs deps = ["//another-dir:animal"])
java_library
pre-defined to create library as the name suggests
java_library( name = "animal", srcs = ["src/main/java/com/abhi/Animal.java"], // if other class is implemented in a different pkg, it has to be visible to main-dir visibility = ["//main-dir:__pkg__"])